ScanRobo+MediaDriveで読み取り精度上げてみた
-
TAG
MediaDrive OCR ScanRobo -
UPDATE
2020/04/15
皆さん、こんにちは。
今回のコラムは、OCRツール「ScanRobo」の紹介記事です。
筆者は実際にScanRoboを導入するお客様に向けて開発を行っていますが、使用方法や読み取り結果などについての記事がネット上にほとんど見当たらなかったため、今回コラムのテーマとして取り扱うことにしました。
OCRツール導入を検討されている方や、実際にScanRoboを使用している方の参考になれば幸いです。
また、弊社では以前からOCRに関する記事を掲載しており、以下がよく検索されている人気記事です。
是非ご覧ください。
ScanRoboとは
ScanRoboとは、RPAテクノロジーズ株式会社が提供しているOCRツールです。
弊社では、アルヒ株式会社様にScanRoboを導入し、住宅ローン手続きの申し込み業務の自動化を行った事例もあります。
(RPAテクノロジーズ株式会社HPより)
『スキャンロボ』で「ARUHI」の“住宅ローン手続きの自動化”を実現
ScanRoboは、以下の2つのアプリケーションから構成されています。
■Kofax Total Agility Designer (以下 KTA Designer)
⇒アクティビティと言われる各要素からプロセスとよばれるワークフローの作成や、
UI画面を設定するWebサイト
■Kofax Transformation Designer(以下 Transformation Designer)
⇒帳票分類、読み取りの詳細設定を行うアプリケーション
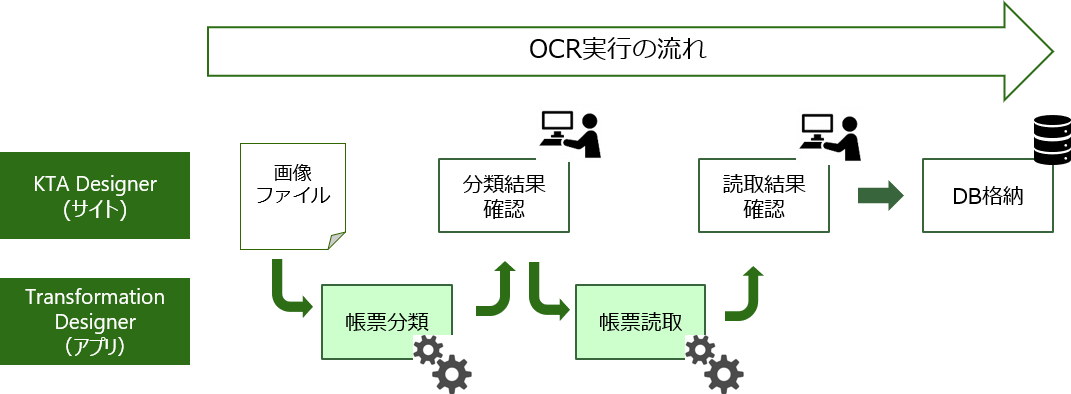
準定型帳票を実際に読み取りさせてみた
では実際に、サンプルの帳票を準定型帳票として読み取ってみましょう。
ScanRoboの準定型帳票の読み取り方法は、以下の順番で行われます。
1.帳票全体に全文OCRをかけて全文読み取り
2.全文OCRの読み取り結果から、実際に取得したいデータのキーワードとなる単語を探索
3.キーワードとデータの相対位、及びデータの内容に合わせた正規表現を設定し、データ取得
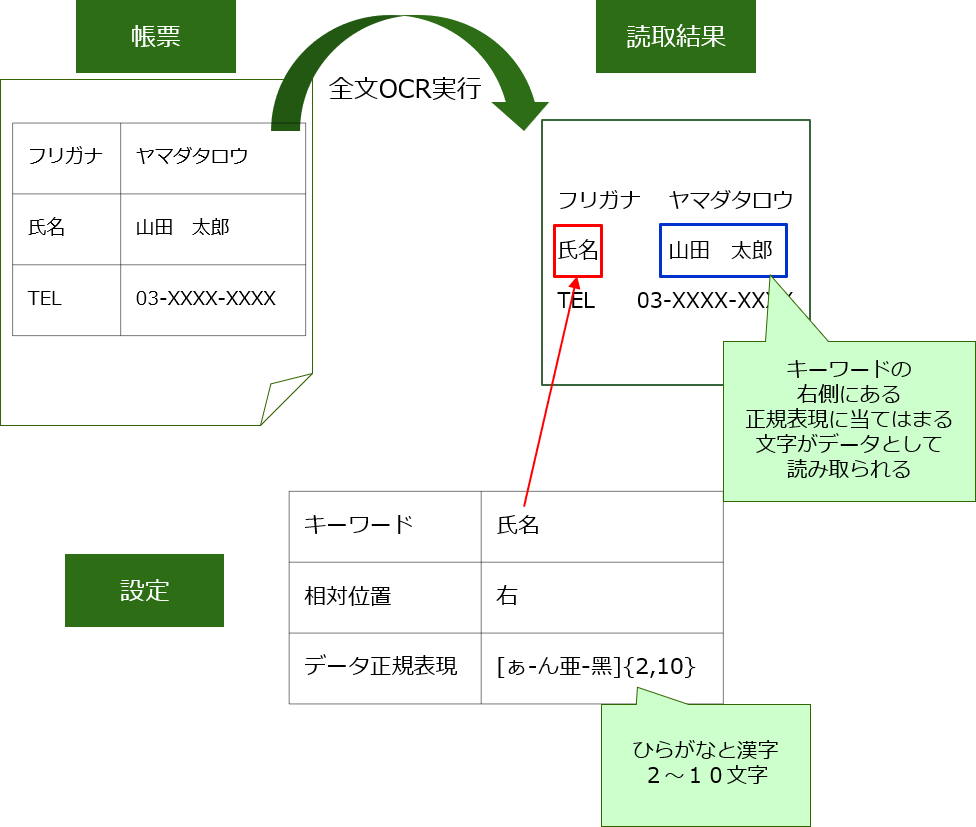
氏名という項目の内容を取得したい場合は、以下のような流れになります。
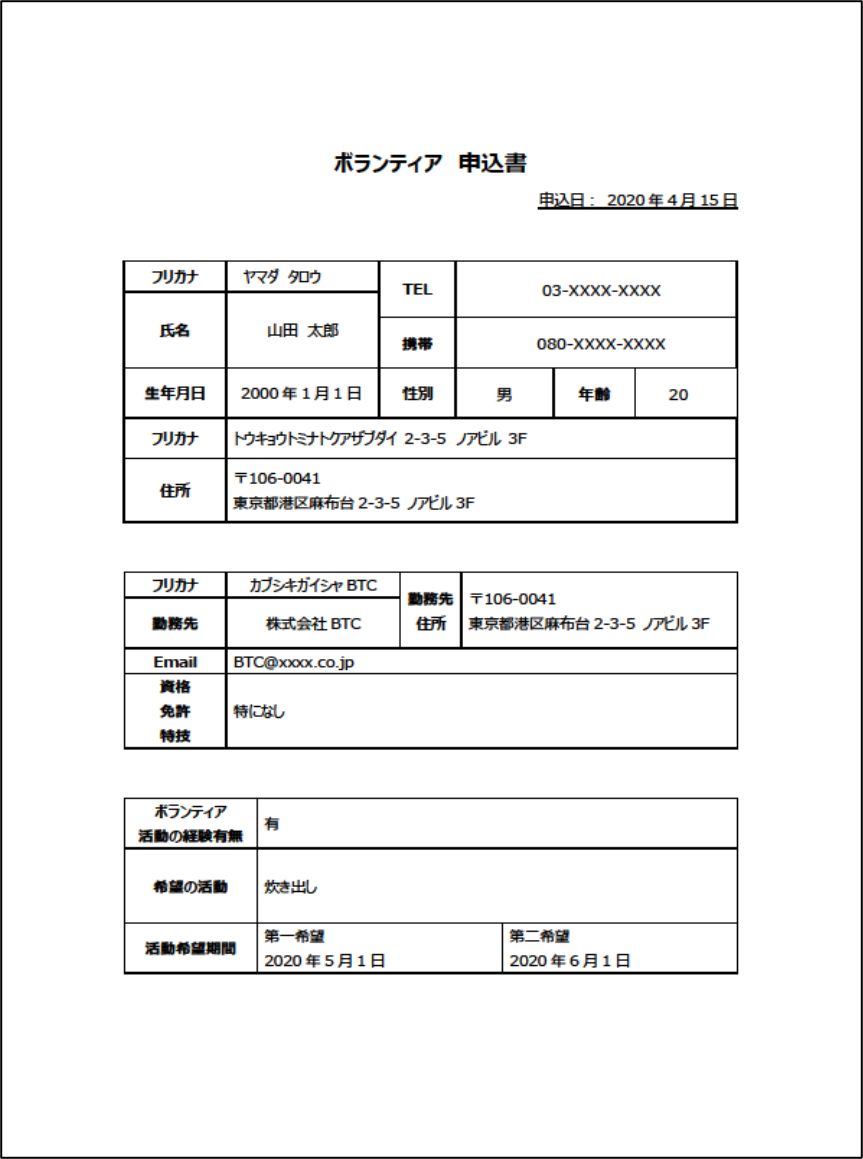
サンプルの帳票は以下の、ボランティア申込書です。今回はすべての項目を読み取ってみました。
Transformation Designerにて、まず全文OCRを行った結果が以下の通りです。
※見やすいようにシステム開発時の画面を表示しています。
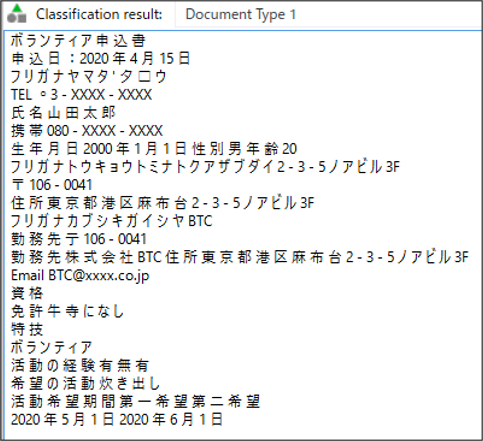
誤字がいくつか見られることがわかります。漢字などの読み取りが難しいと思われる内容だけでなく、数字やカタカナの読み取りも間違って読み取られています。
ではこの全文OCRから
・読み取りたいデータのキーワード
・キーワードとデータの相対位置
・データ内容の正規表現
を設定していきます。
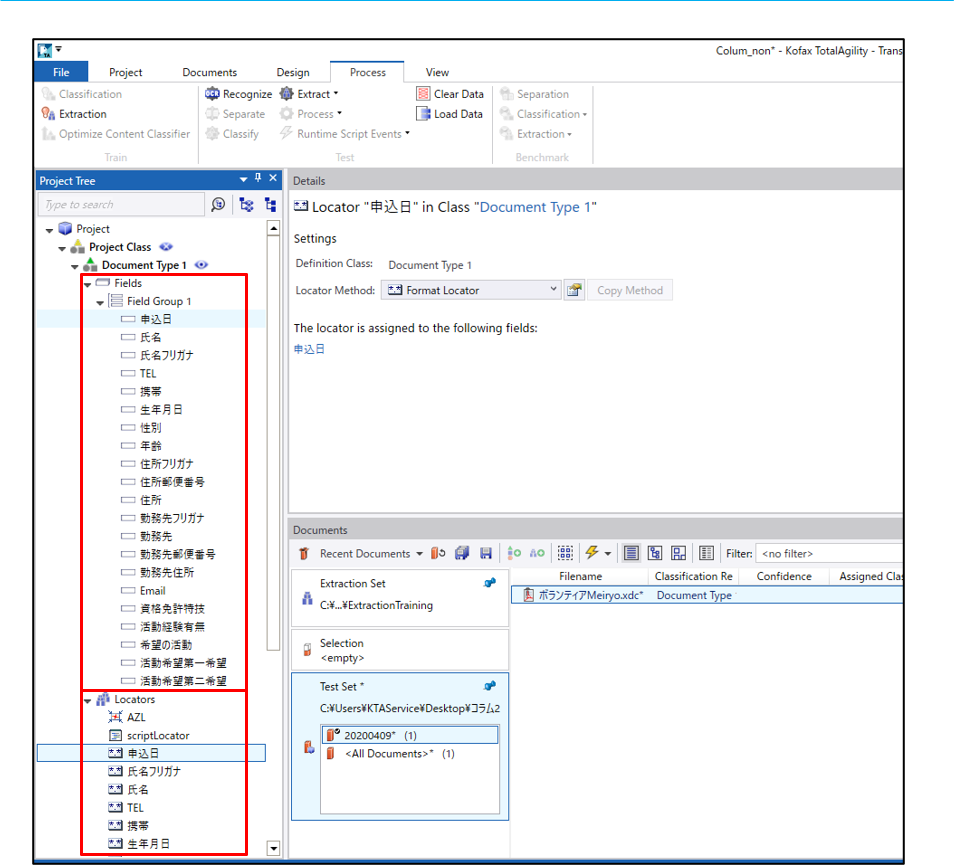
上の図が実際の設定画面です。Fieldにてデータを取得したい項目を設定します。Locatorとは、Fieldで設定した項目を取得するために帳票上でどの位置にデータ内容があるかを設定するものです。
定型帳票の場合は座標で設定しますが、今回の準定型帳票では取得したいデータのキーワードや相対位置、正規表現を設定します。試しに申し込み日のLocatorの設定をしてみます。
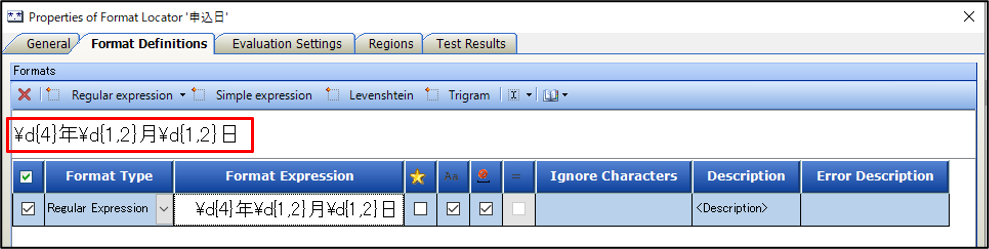
申し込み日のLoactorを開くと、このような画面が開きます。Format Definitionsにて正規表現を設定します。申し込み日は日付なので、
「数字4桁+年+数字1or2桁+月+数字1or2桁+日」
に当てはまるようなデータを取得するように設定します。

続いて、Evaluation Settingsにて「申込日」というキーワードを一文字ずつ設定します。なぜ一文字ずつ設定しているかというと、ScanRoboの全文OCRにおいては、単語ではなく文字ごとに読み取り結果が認識されるためです。
また、右側のKeyword in relation to matchというところで、このキーワード(今回は「申込日」)が取得したいデータのどの方向に存在するかを設定します。今回は、「申込日:2020年4月15日」となるので、キーワードはデータから見て左側、つまりWESTの方向に存在するため、「W」を選択します。

「申込日」の設定を行って、テストを行った結果が上の図です。
キーワードとして認識されている文字がオレンジ色、データとして判別されている部分が緑色、データとして判別されているが一致度が緑色の部分より低いものが紫色の部分になります。今回は正しい箇所が読み取られていることが分かります。
この設定を、読み取りたいデータ項目ひとつずつに設定していきます。全ての設定を完了し、データを取得した結果が以下の通りです。
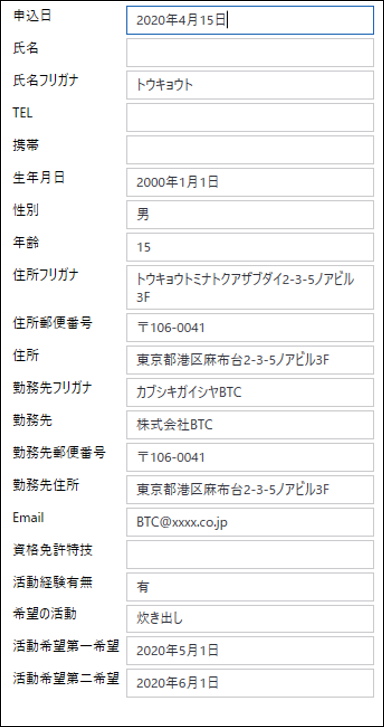
空欄になっている項目は、そもそもキーワード自体が見つけられなかった項目です。また、実際にキーワードが取得出来て、データの場所を特定できている場合でも全文OCR自体が間違っているのでデータ内容の読み取り結果が間違っている部分も多くあり、さらに、一見データを取得できている部分もよく見るとデータ内容が異なっているところもあります。
今回の読み取り成功率は以下のような結果になりました。
キーワード取得(データ場所)成功率 = 15 / 21 項目 = 71.4 %
データ内容取得成功率 = 15 / 15 項目 = 100 %
合計読み取り成功率 = 71.4 % × 100 % = 71.4 %
これら読取結果の原因としては、ScanRoboの日本語精度がまだあまりよくなく、全文OCRが正確に読み取られていないためにおこると考えられます。
では、これらのOCR精度を上げるにはどうしたら良いでしょうか。
MediaDrive
ScanRoboではデフォルトのOCRエンジンだけではなく、他のエンジンを追加することも可能です。
先ほどの帳票の読み取り結果を上げるために株式会社NTTデータNJK(元MediaDrive)が販売している「活字文書OCRライブラリ v9.5」という活字向けOCRエンジンを追加してみました。このOCRエンジンは通称「MediaDrive」と呼ばれているため、以下では「MediaDrive」と記述させていただきます。
では早速 MediaDrive を ScanRobo に追加して、先ほどの帳票を読み取ってみましょう。
MediaDriveをScanRoboで使用するには、Transformation Designerの script Locator にスクリプトを追加することが必要です。
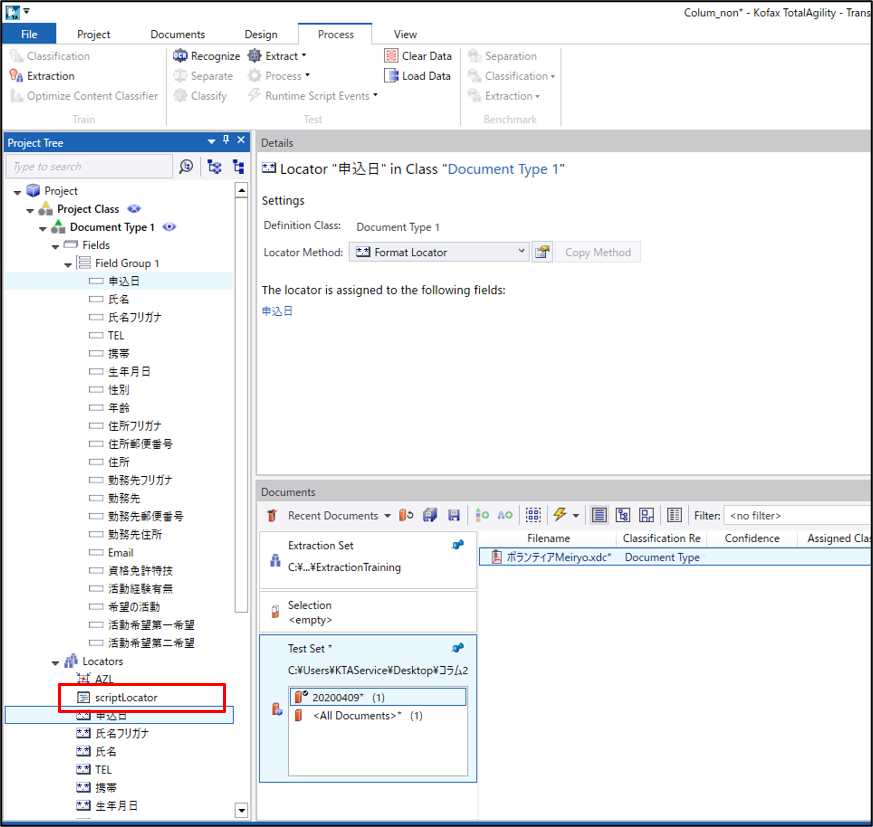
上図の「scriptLocator」を使用してscriptを追加し、日本語読取の設定を行うことでエンジンが追加されます。
実際に、MediaDriveを使用して全文OCRを行った結果が以下になります。

先ほどとは異なり、ほとんどの文字が正確に読み取られています。
では、この全文OCR結果からデータを取得した結果を見てみましょう。
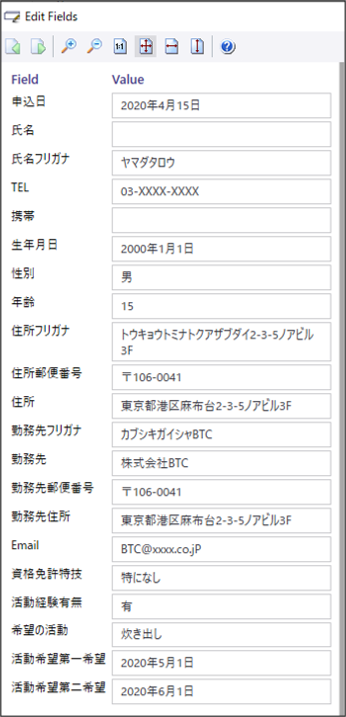
キーワードが取得できていないもの、データの場所が正確に特定できていないものも見られますが、先ほどと比べて読み取り結果の精度が上がったことが伺えます。
MediaDriveを使用した読み取り成功率は以下のような結果になりました。
キーワード取得(データ場所)成功率 = 18 / 21 項目 = 85.7 %
データ内容取得成功率 = 18 / 18 項目 = 100 %
合計読み取り成功率 = 85.7 % × 100 % = 85.7 %
ScanRoboデフォルトのOCRエンジンの結果よりも、キーワードが読み取れた項目が3つ増え、全体での読み取り成功率も 71.4%⇒85.7% と 14.3% 増えています。
以上のように、日本語精度が高いOCRエンジンを組み合わせることで読み取りの成功率が上がることが分かりました。また実際に開発を行う際には、さらに読み取る場所を細かく特定したり、正規表現を細かく設定したり、固有の辞書を追加することでさらに精度をあげることが可能です。
最後に
ScanRoboでは、目的に合わせてOCRエンジンを組み替えることで様々な帳票に対応できるということが分かりました。また、今回の設定はあまり細かく行わずありのままの結果を見ていただきましたが、帳票に合わせて取得するデータ範囲をさらに詳細に設定して、精度を上げることもできます。
是非OCRを導入・自動化を検討していただけたらと思います。
最後までお付き合いいただき、ありがとうございました。
最新情報をお届けします!
RPAに関する最新コラムやイベント情報をメールで配信中です。
RPA領域でお仕事されている方に役立つナレッジになりますので、ぜび登録してください!









- November 2024 (2)
- October 2024 (3)
- September 2024 (2)
- August 2024 (4)
- July 2024 (1)
- June 2024 (2)
- May 2024 (3)
- April 2024 (1)
- March 2024 (1)
- February 2024 (1)
- January 2024 (1)
- December 2023 (1)




