OCRを使わずにPDFのデータをロボットが処理!
はじめまして。RPA事業部の岡です。
最近、受注案件が増加し、RPAが世に広まっていることを感じています。
一方で、画像から文字等のデータを検出したい等、OCRの需要も着々と増加してきています。
OCR単体でも業務効率化を期待できますが、OCRで検出したデータをRPAのロボットで処理させる等、OCRとRPAを組み合わせることで、さらなる業務効率化を期待できます。
ただし、OCRを導入すると、画像のレイアウトの分類や文字の検出率を上げるためのチューニング等、様々なステップが必要になります。
この記事をご覧になっている方の中には、OCRを使わないで画像からデータを検出してロボットに処理させたい、と考えた方もいると思います。
そこで今回は実際に業務で実践した、OCRを使わずにPDFをロボットに処理させる裏技を紹介します。
イントロダクション
今回は図1のような表を持つPDF※をロボットに処理させようと思います。
といっても今回は大人の事情で、ロボットがPDFから表のデータを検出するステップまでとします。
※画像の一部にマスキングを施していますが、本記事の掲載のための処理であり、実際はマスキングを行っていない画像で本記事内の作業を行っています。

紹介させていただく裏技ではOCRの代わりにAdobe Acrobat pro DC (以下、AApD) を使用します。
OCRと比較すると、導入されている企業様も多いと思います。
それでは、裏技の詳しい内容に触れていきます。
ステップ1 PDFをHTMLファイルに変換
PDFをロボットに処理させるために、PDFをHTMLファイルに変換してしまいます。
先ずは、AApDで対象のファイルを開いて、右側のメニューから「PDFを書き出し」を選択します。
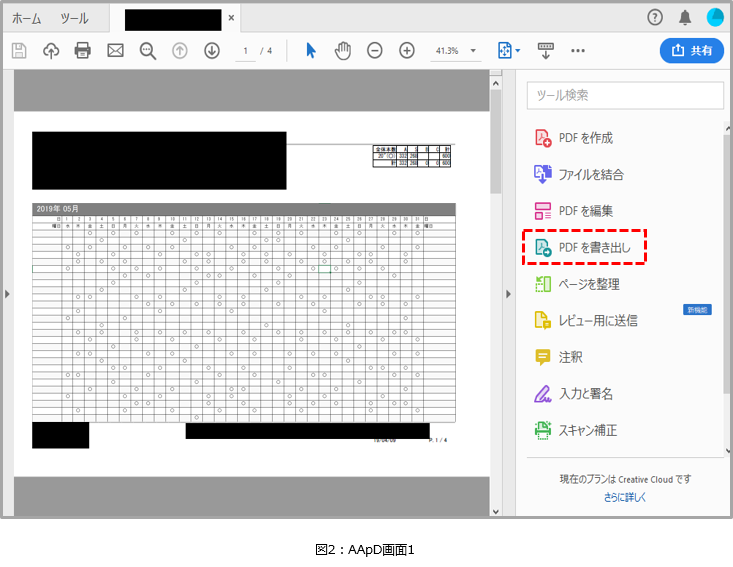
すると、図3の画面が表示されるので、「HTML Webページ」を選択し、「書き出し」ボタンをクリックします。
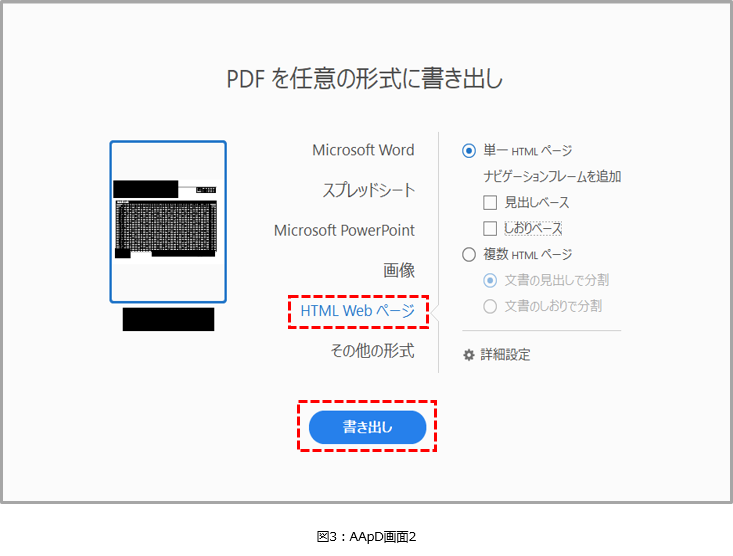
「書き出し」ボタンをクリックするとHTMLファイルの保存場所を確認されるので任意の場所に保存してください。
HTML変換したPDFをブラウザで表示したものが以下の図4になります。
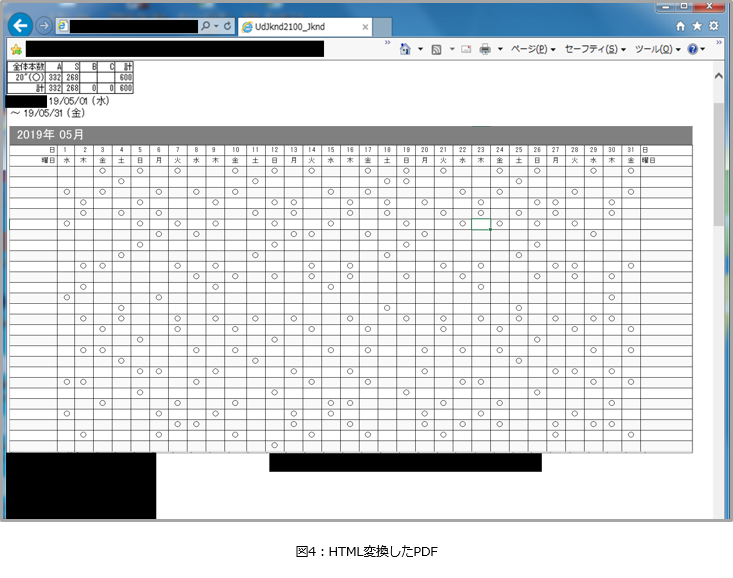
PDFの時から若干レイアウトが変化していますが、変換自体は成功しています。
なぜHTMLに変換?
この記事をご覧の方の中にはなぜHTMLに変換しているの?と疑問に持たれる方もいると思います。
実際にExcelに変換してロボットに処理させようと試みましたが、Excelへの変換は成功したもののデータの検出に失敗してしまいました。
いろいろと手段を模索している中で、ロボットのWeb画面のボタンやテキストボックス等、いわゆる「要素」を認識できる※という特性に注目し、HTMLへの変換を試してみたところうまくいったというわけです。
※使用するRPAツールに左右されるため、必ずではありません。
ステップ2 ロボットで処理したいデータを検出
PDFをHTMLに変換したら、あとはロボットで処理したいデータを検出するだけです。もうほとんどゴールですね。
念のため、ロボットが表を要素として認識できているか確認してみましょう。
今回はBluePrismというRPAツールを使用しています。
下の図5はロボットがHTMLに変換したPDFから要素を取得している作業のキャプチャです。
表が赤枠※で囲まれていますね。
この赤枠は、ロボットが赤枠で囲んでいる部分を要素として認識していることを示しています。
つまり、HTML変換することでロボットに表を認識させることに成功したということです。
※実際の赤枠は線が細くわかりずらいため、図5は赤枠が強調されるように修正を行っています。
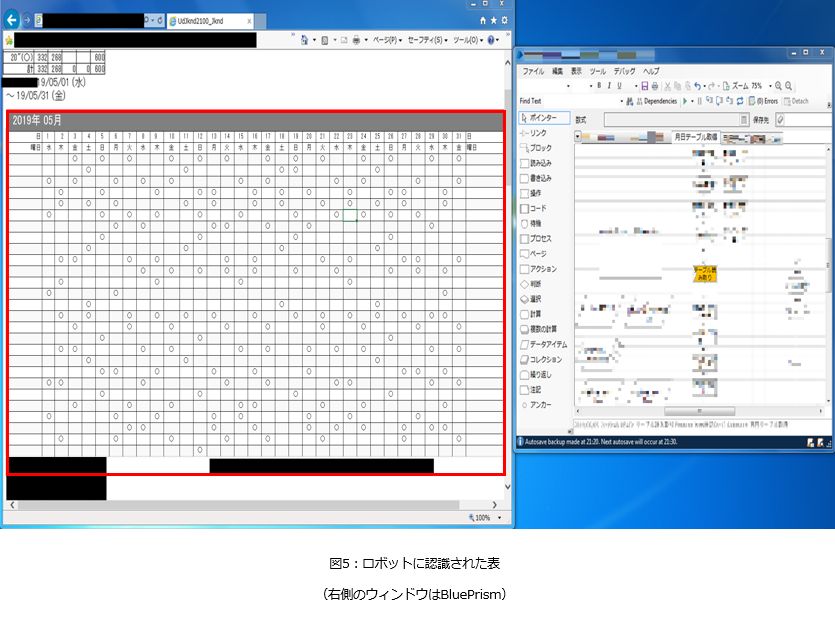
あとは、表のデータ(曜日や○)を検出し、ゴールとなります。
実際のロボットの開発では、要素としては認識できているのに、データの検出がうまくいかないということが多々あるため、要素として認識できても油断はできません。
少しの不安を抱きつつ、ロボットが検出した表のデータが図6となります。
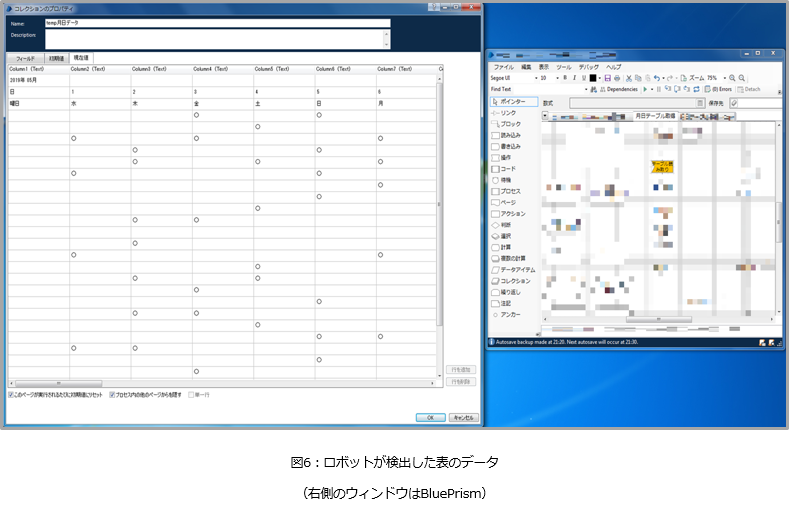
成功しました。
少し見づらいですが、表のデータを検出できていることが分かると思います。
あとは、ロボットが用途に合わせて表のデータを処理していくだけですね。
まとめ
今回はAApDを利用して、OCRを使わずにPDFをロボットに処理させる裏技を紹介しました。
OCRを使用せずとも、少しの工夫でロボットにPDFを処理させることが可能になります。
ただし、今回紹介した方法は、処理対象となるPDFがテキストコピー可能であり、レイアウトが固定となっている、いわゆる「定型」の場合のみ有効な方法です。
例えば、複数ページ存在するが、各ページのレイアウトが異なっている、いわゆる「準定型」や「非定型」のPDFが処理対象の場合は、残念ながら今回の裏技は使えません。
「準定型」や「非定型」のPDFから文字データを検出したり、ロボットが処理できるように変換したい場合は、OCRの導入を強くお勧めします。
弊社ではRPAの導入はもちろんOCRの導入にも力を注いでいます。
RPA、OCRに興味がある、導入を検討している、という場合はお気軽にお問い合わせください。
今回は以上です。ありがとうございました。
最新情報をお届けします!
RPAに関する最新コラムやイベント情報をメールで配信中です。
RPA領域でお仕事されている方に役立つナレッジになりますので、ぜび登録してください!









- July 2024 (1)
- June 2024 (2)
- May 2024 (3)
- April 2024 (1)
- March 2024 (1)
- February 2024 (1)
- January 2024 (1)
- December 2023 (1)
- November 2023 (2)
- October 2023 (3)
- September 2023 (1)
- August 2023 (4)