半構造化文書のデータが取れる、凄いぞABBYY社のOCR

目次
令和初の夏の暑さに負けない熱いOCRツール「 ABBYY FlexiCapture 」の紹介記事になります。
RPA×OCRについて基礎知識があるとより楽しめると思います。
(参考)OCRの読取精度に囚われ過ぎず、業務プロセス全体の効率化を
https://rpa.bigtreetc.com/column/ocrbusinessprocess/
目次
1.用語の定義
2.ABBYY社について
3.半構造化文書を実際にABBYY FlexiCaptureで文字認識させてみた
4.レイアウトが異なってもデータを取得出来る理由
5.ABBYY FlexiCaptureのOCRを使ってみた感想
6.最後に
1.用語の定義
この後よく出てくる単語について説明します。
固定文書 ・・・同じフォーマット、つまり常に同じ座標に取得したいデータがある帳票のことです。
ABBYY社及び今回では「固定文書」と呼びますが、「定型帳票」も同じ意味です。
従来のOCRで取得出来るのは、このタイプのみでした。
帳票の例を挙げると、申し込み書やアンケートがあります。
半構造化文書 ・・・フォーマットは異なるものの、商品の右に数量、単価が記載されている等の一定の規則に従って作成された帳票のことです。
ABBYY社及び今回では「半構造化文書」と呼びますが、「準定型帳票、非定型帳票」も同じ意味です。
帳票の例を挙げると、見積もり書や請求書があります。
今回はこの、半構造化文書を実際にOCRで認識させていきます。
2.ABBYY社について
ABBYY社は文書処理技術に長けている会社で、その実力は200ヶ国以上でサービスやソリューションが利用されているほどのグローバル企業であります。
ABBYY社の技術は日本でも馴染みがある大手スキャナメーカーやモバイルメーカーで採用されており数々の実績を持つ会社です。
今回はABBYY社の製品の中からOCRに関連する2製品について説明します。
ABBYY FlexiCapture ・・・「固定文書」を読み取る定義を作成するときに使用します。また、実際に読み取ったデータをDBに格納したり、CSVなどに変換するときにも使います。
イメージとしては、簡単な処理ならこなせる作業者です。

ABBYY FlexiLayout Studio ・・・ 「半構造化文書」を読み取る定義を作成するときに使用します。
ABBYY FlexiCaptureのサポートツールといった位置付けで、実際のデータはABBYY FlexiCaptureで処理されるので、システム開発で読み取り定義を作る時のみ使用します。
イメージとしては、 難題をこなすために指示を出してくれる上司です。
![]()
システム開発では下記のようなフローで処理します。
(例)半構造化文書読み取りフロー
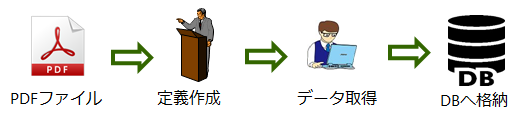
では実際にOCRの定義を作成し、データ取得までの処理をしてみましょう!
3.半構造化文書を実際にABBYY FlexiCaptureで文字認識させてみた
今回は2ページに跨っている請求書を扱います。
データを取得したい箇所を赤枠で囲ってあります。
半構造化文書はキーワードを見つけて、そのキーワードの相対位置でデータを取得するのが基本です。詳細は後述します。
日付と請求書番号はテキスト形式で、数量の下は表形式でデータを取得します。
サンプル請求書1ページ目

サンプル請求書2ページ目

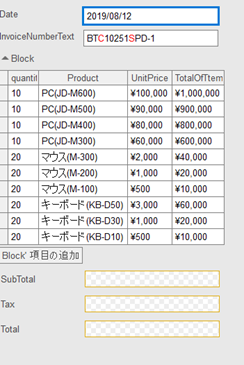
ABBYY FlexiCaptureで実際に読み取れたデータは下記の通りです。
赤文字の所はソフトが自信ないと表示している目安になります。
※見やすいようにシステム開発時の画面でご紹介しております。
読み取り結果
1ページ目
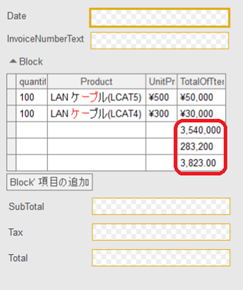
2ページ目
1ページ目は正確にデータが取得出来ていますが、
2ページ目の小・消・合を、それぞれSubTotal・Tax・Totalの項目で取得したかったのですが、品目の合計と同じ表であるBlockに格納されてしまいました。
どちらのページも日本語と英数字の誤りはなくきちんとデータが取れており、精度の高さが伺えます。
2ページ目の小・消・合を正しく取得するためには、Blockの表にフッターを認識させる等のトライ&エラーで正確に読めるように調整をしていきます。
一般的にOCRが難しい複数ページに跨る帳票も、 ABBYY FlexiCaptureであればデータの取得が出来ることが分かりました。
4.レイアウトが異なってもデータを取得出来る理由
どうして、このようにレイアウトが異なってもデータが取れるのか解説します。
「固定文書」では表の座標からデータを取得できるのですが、
「半構造化文書」は特定のキーワードの相対的位置からデータを取得していきます。
そのためフォーマットやデータが複数ページに跨っていても、一定の規則を元にデータを取得出来るのです。
そのため半構造化文書から「2019/08/12」を読み取るには下記のステップを踏みます。

①日本語の「日付」という文字を取得する。
②日付の下の、XXXX/MM/DDという形式の文字を取得する。
③ ①と②の条件に当てはまる「2019/08/12」を認識する。
ポイントは①のOCRがキーワードとなるデータを正しく認識してくれるかどうかです。
キーワードの相対位置から欲しいデータを探すので、肝心のキーワードが見つからないとエラーになってしまいます。
そのため定義を作成する時は複数の帳票から、キーワードに出来そうな文字を探して定義します。
また、テクニックとして 「日付」を無視して「XXXX/MM/DD」という形式だけで見つけることも可能ですが、画像中央右寄り(文字が小さいですが)にある「期限」も同じ形式なため、誤読してしまうことが多いので、
「日付の下」+ 「XXXX/MM/DD」で確実に欲しいデータを取得していきます。
このように半構造化文書では、キーワードとなる情報を手掛かりに相対位置でデータを取得するので、
今までのOCRでは対応出来なかったそれぞれ別のフォーマットで複数のお客様から頂く見積もり書や請求書
といった帳票をOCRでデータ化することが出来るのです。
5.ABBYY FlexiCaptureのOCRを使ってみた感想
数年前のOCRを使ったときは読み取り精度が低く、自分で全部一から入力した方が
早いと思っておりましたが、今回の帳票では100%の精度で読み取りできることが分かりました。
また読み取り精度が高いことに加えて、座標を指定しなくても読み取ってくれるので、
1つの定義で複数のフォーマットの帳票の読み取りが行える技術の進歩には感動しました。
6.最後に
ABBYY FlexiCaptureは半構造化文書に強く、半構造化文書の読み取り精度が上がらず過去にOCR導入を見送った企業でも改める検討してみる価値はあります。
OCRを活用して業務の効率化をしてみませんか。
BTCであれば、RPA×OCRでお客様にとって最適なご提案と技術力で業務効率化を実現をさせて頂きます。
最後までお付き合いいただきありがとうございました。
最新情報をお届けします!
RPAに関する最新コラムやイベント情報をメールで配信中です。
RPA領域でお仕事されている方に役立つナレッジになりますので、ぜび登録してください!









- July 2024 (1)
- June 2024 (2)
- May 2024 (3)
- April 2024 (1)
- March 2024 (1)
- February 2024 (1)
- January 2024 (1)
- December 2023 (1)
- November 2023 (2)
- October 2023 (3)
- September 2023 (1)
- August 2023 (4)




