Azure Data Factoryのデータフローのめんどくさいマッピングを効率化してみた
目次
はじめに
先日初めてAzure Data Factoryを触ってみて、階層構造があるxmlのデータ変換を行いました。
その中でデータフローの選択アクティビティで項目をマッピングするのがとても大変だったので、どうにかして簡単に全ての項目をマッピングできないか、という検証を行ってみました。
実際にデータフローでのマッピング方法を検討してみる
前提条件
下記の流れで任意のソースからxmlファイルをインポートし、選択アクティビティで必要な項目を選択し、任意の出力先へデータをシンクする、というデータフローを作成します。①ソースの追加、②選択、③シンクというアクティビティを使用することを想定します。
今回は選択アクティビティでのマッピングを効率的にできないか、という検証を行います。
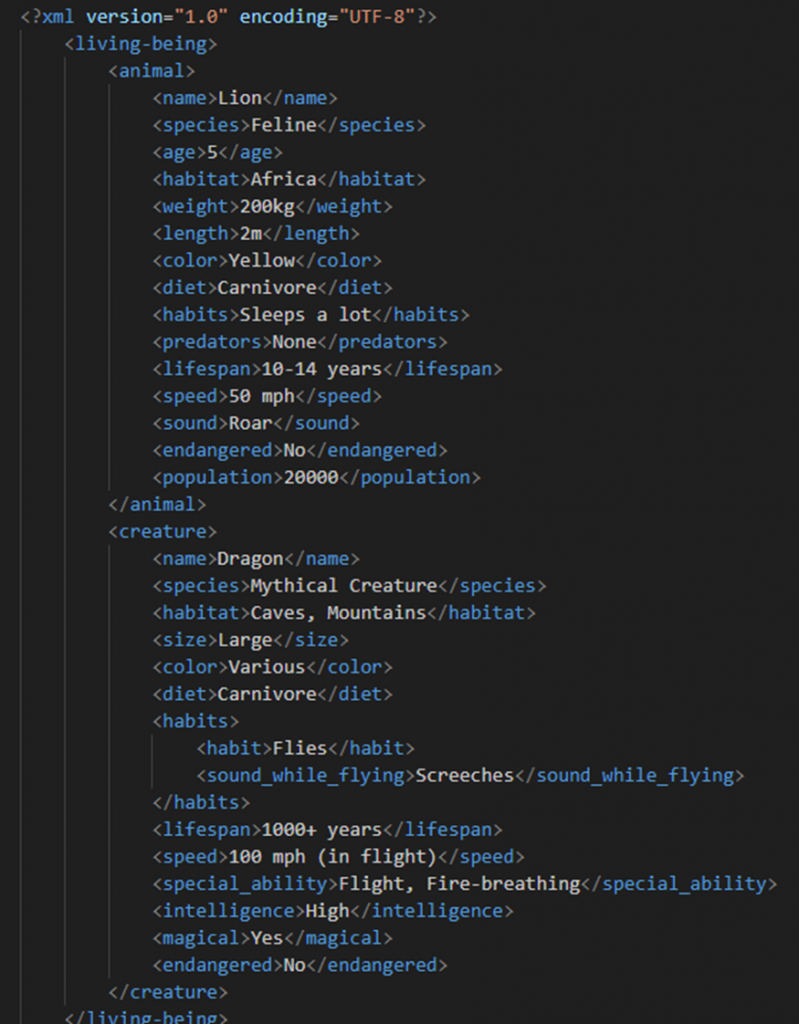
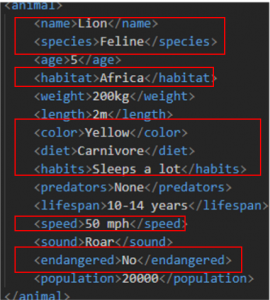
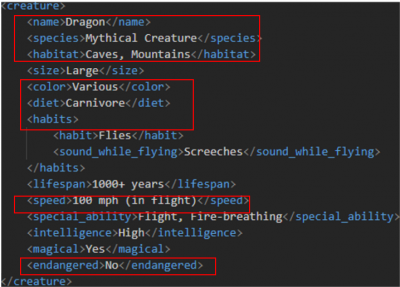
取り込むxmlファイルには下記のようなデータが入っています。<living-being>という項目の下に<animal>, <creature>という項目があり、更にその下の階層に細かい項目が書かれています。
この階層構造になっている最下層の項目を一つ一つ取り出していきたいです。
①自動マッピングを使ってみる
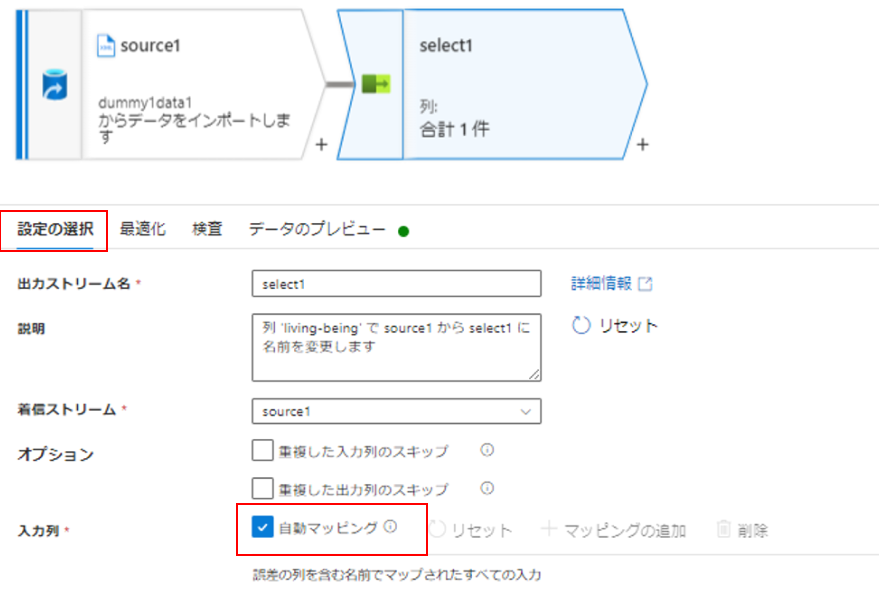
選択アクティビティに「自動マッピング」というものがあるので、チェックを付けてマッピングできるかやってみます。

①のソースの追加アクティビティからxmlファイルを読み込んだ後、そのまま選択アクティビティで自動マッピングしてみると、データのプレビューではデータが階層構造になっており、最下層の項目が表示できません。階層構造になっていないデータであれば使えそうですが、今回は不適のようです。
②固定マッピングを使ってみる
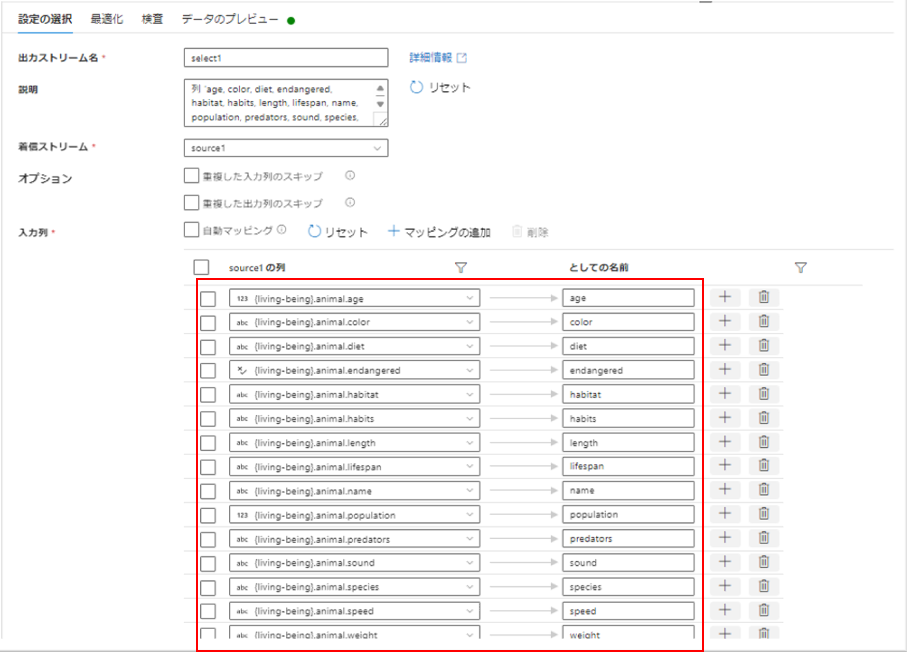
固定マッピングで一つ一つ項目をマッピングしていきます。
取り出す階層を指定し、出力名を一つ一つ入力して指定します。

データのプレビューで、最下層項目のデータが表示されました!固定マッピングでは全ての項目を正しく取り出せそうです。
しかしこのマッピング、項目が多い場合は膨大な時間がかかりますし、ミスも発生してしまいます。他の方法を検討してみましょう。
③ルールベースのマッピング
選択アクティビティのマッピングには一つ一つ項目を指定する固定マッピングのほかに、ルールベースのマッピングがあります。今度はルールベースのマッピングを行ってみました。
※ルールベースの詳細については、下記をご参照ください
マッピング データ フロー内の列パターン - Azure Data Factory & Azure Synapse | Microsoft Learn
入力内容は下記の通りです。
一致条件:true() …データが存在するか
階層レベル:{living-being}.animal, {living-being}.creature …取り出したい階層の上の階層を指定
としての名前:$0 …列パターン内の現在の動的列名、この場合は最下層項目名
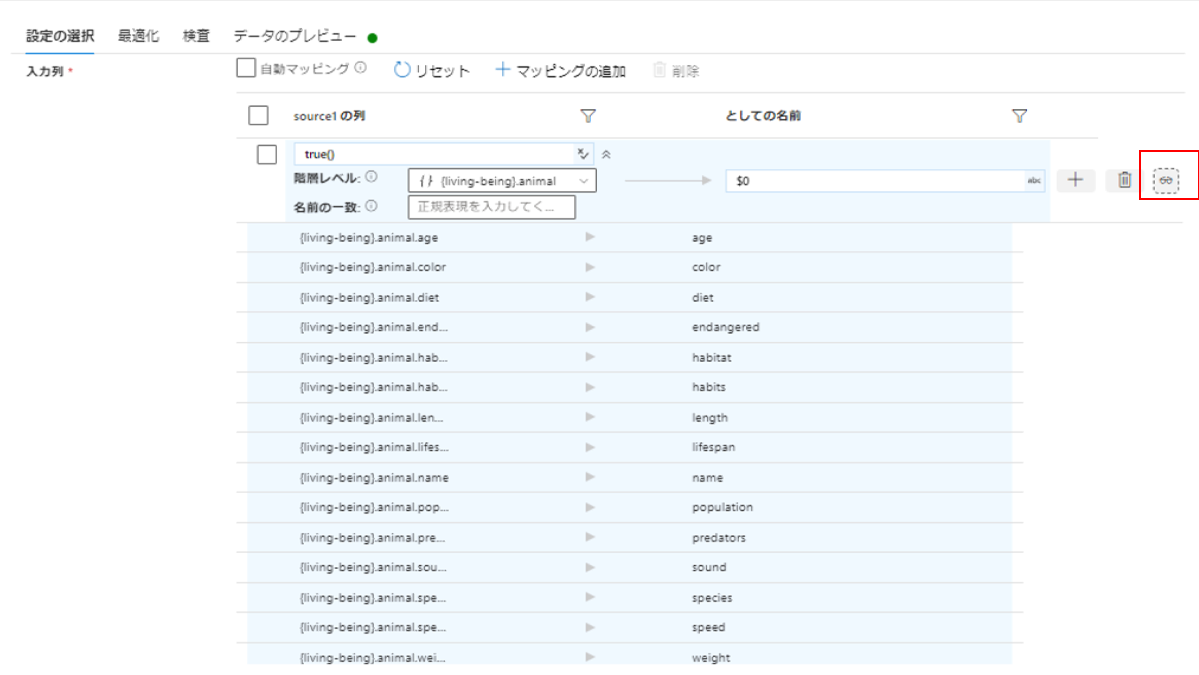
animal階層を指定してマッピングします。
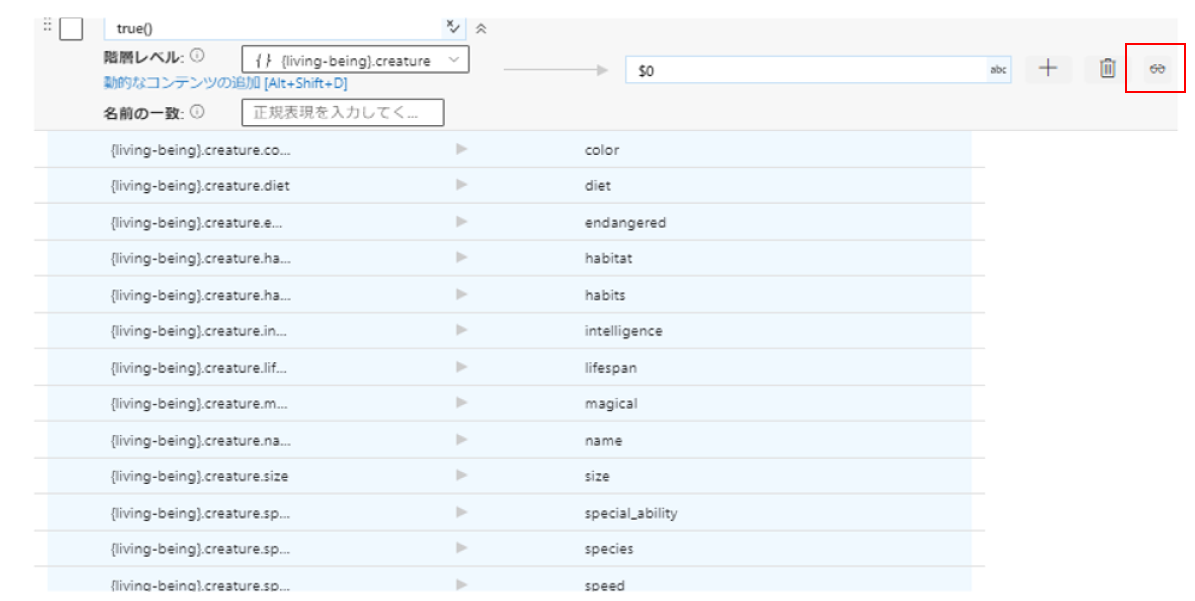
同様に、creature階層を指定してマッピングします。
右端の眼鏡マークを押すとマッピングしている項目がプレビューできます。animalとcreatureの下の階層項目を簡単に取り出せて、よさそうな感じがしますね。
では選択アクティビティのデータのプレビューで実際に正しくマッピングできているか確認しましょう。
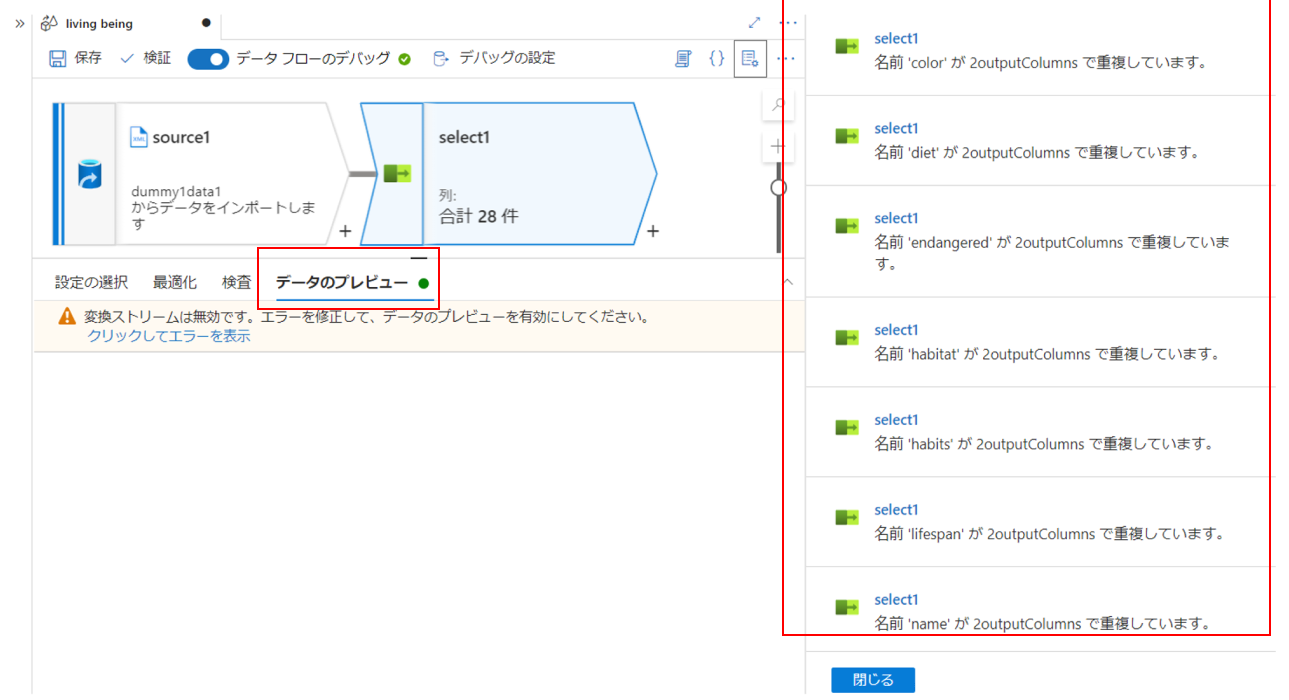
めちゃくちゃエラーが出ていますね。どうやらanimal以下の項目たちと、creature以下の項目たちの名前が被ってしまっているようです。
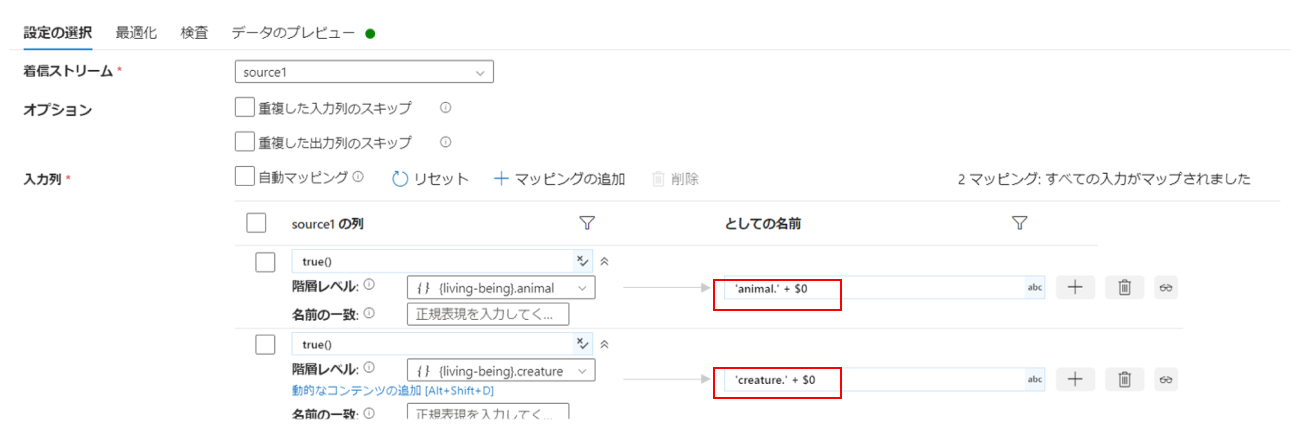
Animal階層の項目の接頭辞に「animal.」を、creature階層の項目の接頭辞に「creature.」を追加しました。
この状態で再びデータのプレビューを確認します。
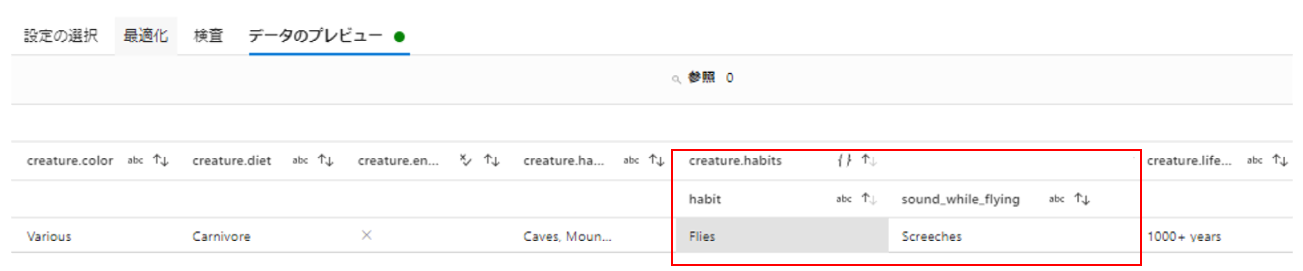
エラーが解消されました。しかし、habitsの下に更に項目があるためまだ階層構造が存在しています。この階層の項目もマッピングが必要です。
マッピングします。
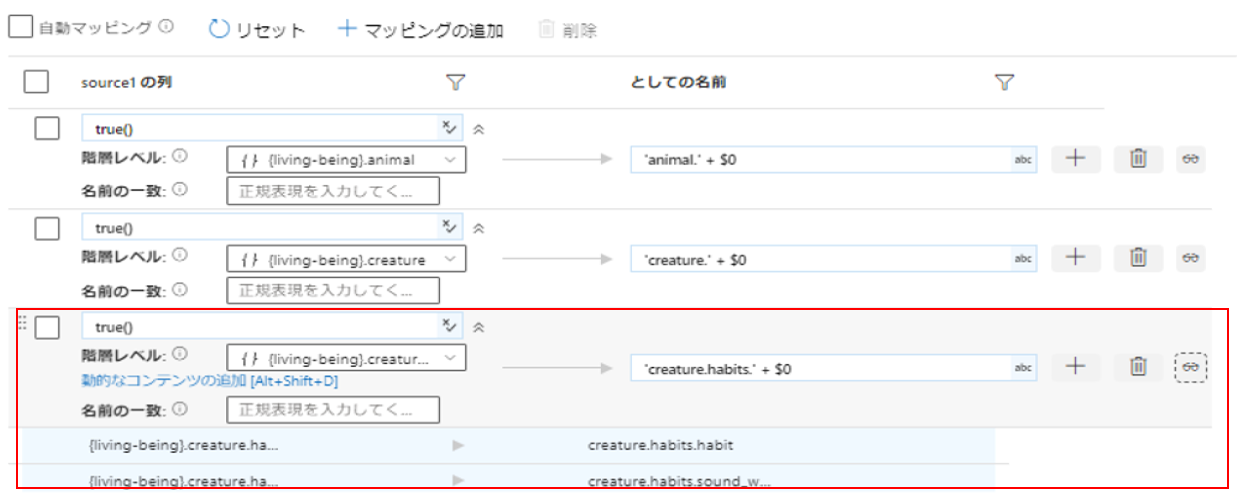
これですべてのマッピングが完了しました。
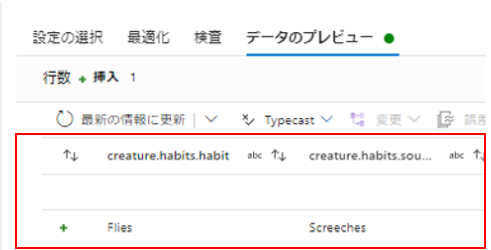
今回は階層も項目も少なかったのでこれらの手順でマッピングができましたが、もっと階層も項目も多かったら一つ一つの階層でルールベースのマッピングをして、項目名が一意になるように出力させて・・・と気が遠くなるかもしれません。もっと良い方法はないのか検討してみました。
④フラット化アクティビティのマッピング
ここで登場するのが、フラット化アクティビティです。フラット化アクティビティは2020年4月に追加されたアクティビティで、階層構造のデータで、繰り返し値を持つ個々の行に値を非正規化するアクティビティです。詳しくは以下をご参照ください。
マッピング データ フローのフラット化変換 - Azure Data Factory & Azure Synapse | Microsoft Learn
フラット化アクティビティを使用するには繰り返し値(つまり配列)が存在しないといけないのですが、今回読み込むxmlファイルには繰り返し値が存在しないため、ソースの追加アクティビティのスキーマ設定で配列を追加します。
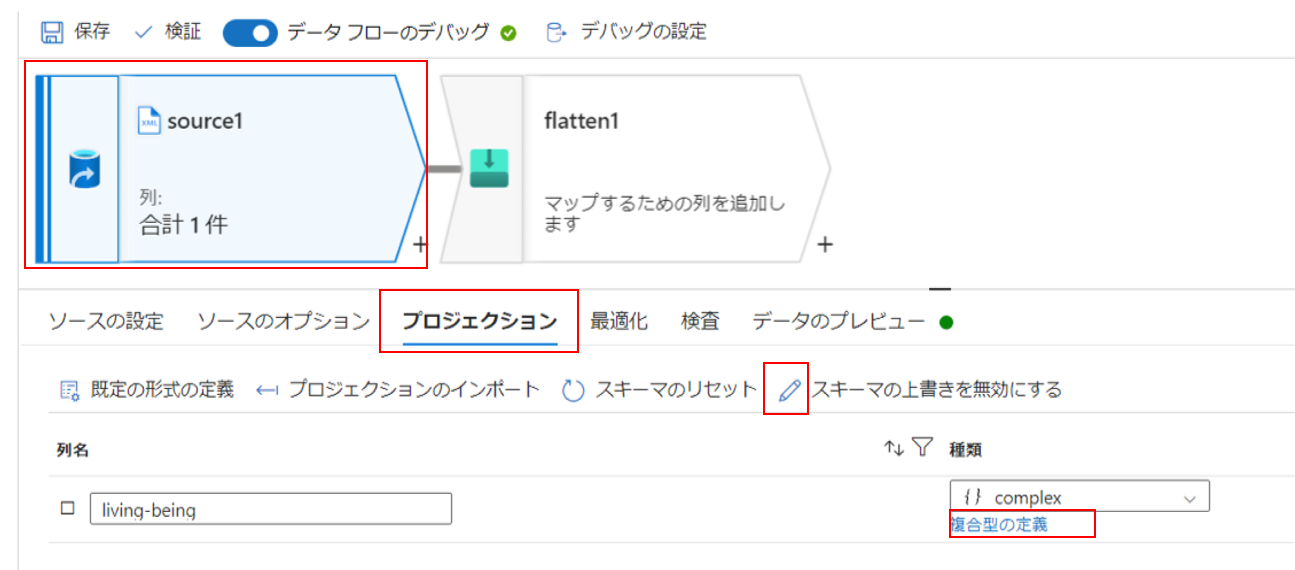
ソースの追加アクティビティに戻り、プロジェクションのスキーマの上書きから、「複合型の定義」をクリックします。
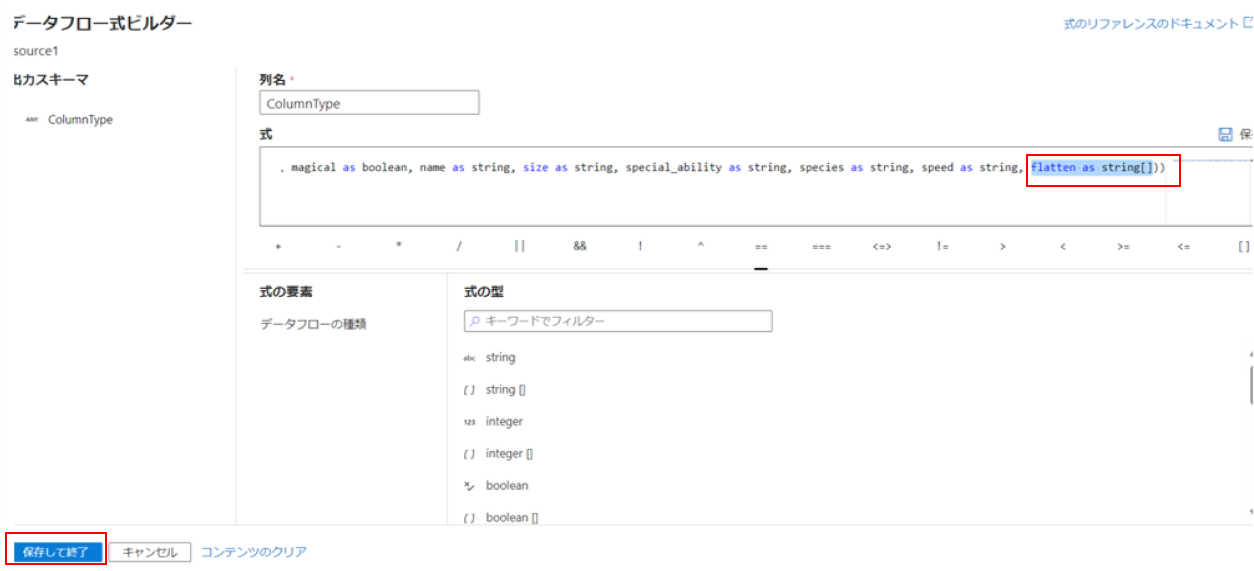
データ型定義の最後に任意の項目(今回はflatten)を追加し、データ型を配列型(string[])に定義します。
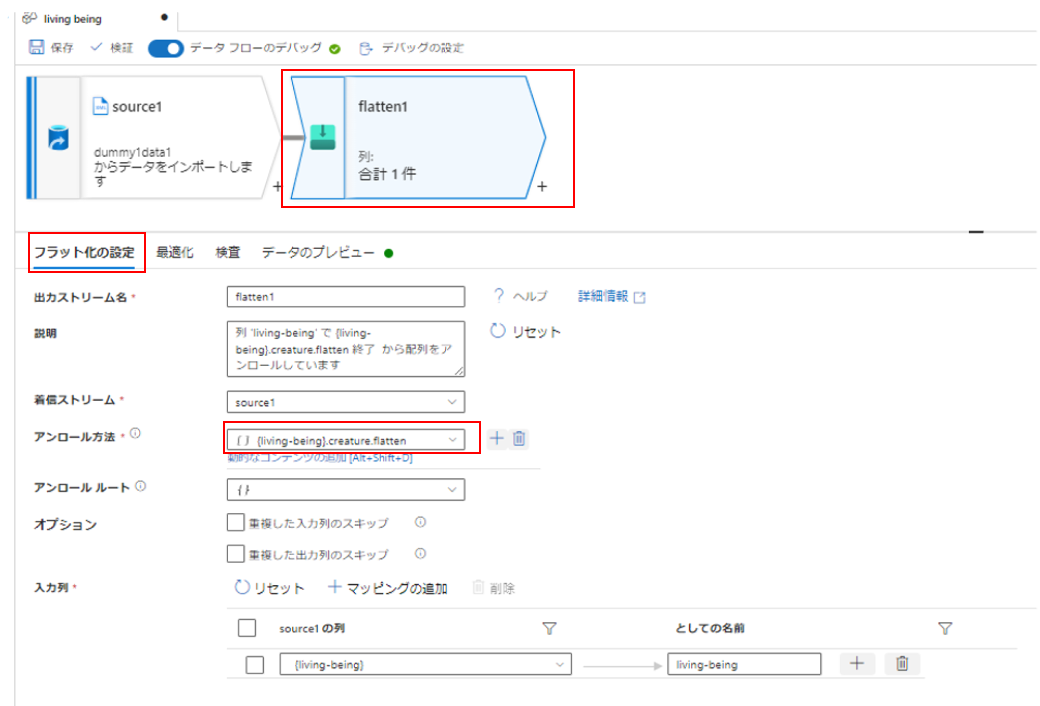
フラット化アクティビティを再び選択し、アンロール方法に先ほど設定した「flatten」を含む階層を選択します。

下記の通り設定します。すると、親項目を含めた項目名が全て出力されます。
一致条件:true()
詳細な列の走査:有効(チェック)
階層レベル:指定なし
としての名前:$0
今回は「living-being」という項目名は不要なので、replace関数を使って除去することも可能です。
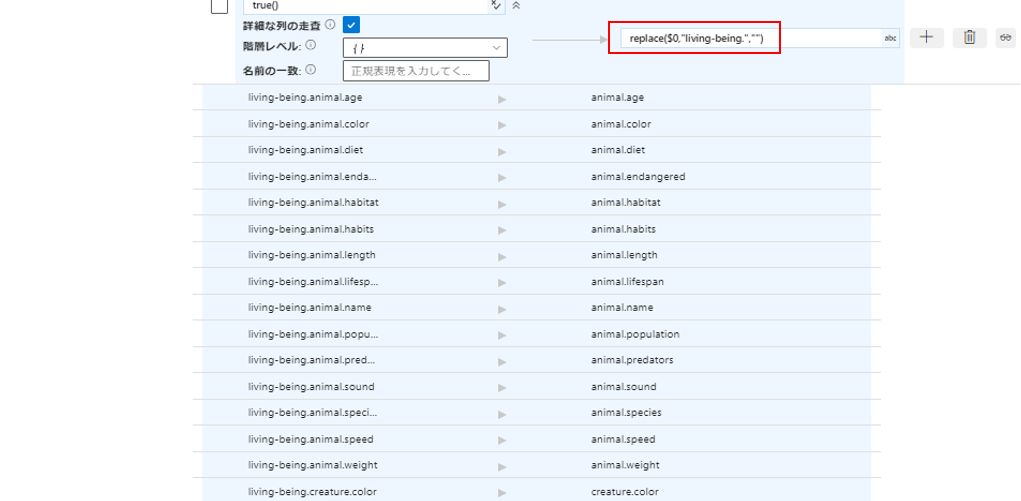
下記の通り設定します。
一致条件:true()
詳細な列の走査:有効(チェック)
階層レベル:指定なし
としての名前:replace($0,"living-being.","")
これでanimal、creature階層を含めたすべての項目のマッピングが完了しました。一つ一つマッピングしていた時に比べると、かなり時間短縮されます。
【補足事項】全ての最下層項目が一意である場合
今回はanimal階層の下にある項目と、creature階層の下にある項目が重複していたため使用できませんでしたが、最下層項目が全て一意である場合は下記のように設定して、最下層項目のみを出力することが可能です。
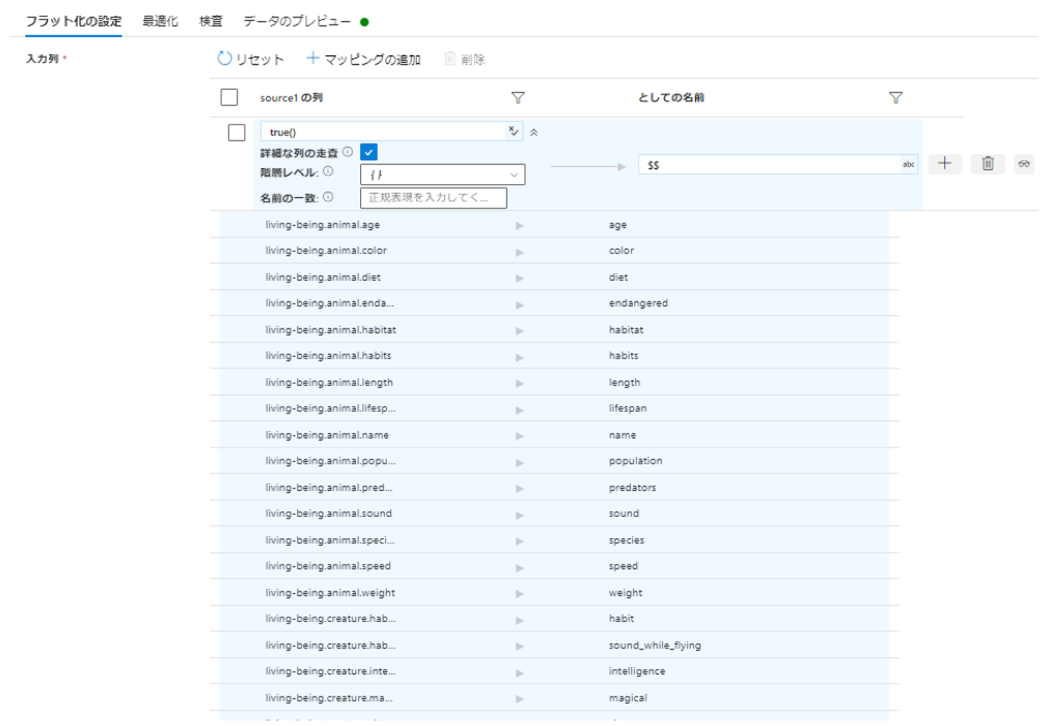
一致条件:true()
詳細な列の走査:有効(チェック)
階層レベル:指定なし
としての名前:$$
親項目を項目名に含める必要がなければ、これでマッピング完成です。
※ちなみに、どちらのマッピングでも全ての項目を選択しており、不要な項目はどうやって取り除いたらいいのかと疑問に思われた方もいらっしゃるかもしれません。その場合は、シンク先のテーブルに不要項目を作らなければ、シンクの際に自動でその項目がはじかれます。(選択アクティビティの意味とは・・・となりますが)
まとめ
このように、フラット化アクティビティのルールベースのマッピングを使用して全ての項目を一括でマッピングできることがわかりました。
項目をマッピングするのが面倒くさい!となった場合は、ぜひ一度お試しください。
関連記事


最新情報をお届けします!
RPAに関する最新コラムやイベント情報をメールで配信中です。
RPA領域でお仕事されている方に役立つナレッジになりますので、ぜび登録してください!









- November 2024 (2)
- October 2024 (3)
- September 2024 (2)
- August 2024 (4)
- July 2024 (1)
- June 2024 (2)
- May 2024 (3)
- April 2024 (1)
- March 2024 (1)
- February 2024 (1)
- January 2024 (1)
- December 2023 (1)