AutomationAnywhereの最新版A2019を用いて感情分析を行ってみた
-
TAG
A2019 Automation Anywhere RPA 自然言語解析 -
UPDATE
2019/12/23
感情分析とは?
感情分析とは、書かれた文章に含まれている単語から、ポジティブな意見 or ネガティブな意見 or 中立的な意見かを判断することです。主な活用事例としては、アンケート調査の自由記入欄に記載されている内容やコールセンターの対応記録等から数値化(見える化)することで改善に活かしたり、ニーズを把握したりするのに用いられています。
11/12に公開された、Automation Anywhere Enterprise A2019 Community Edition(以下、A2019)では、直接Pythonのスクリプトを実行できるようになりました。 こちらを利用して、感情分析を行ってみました。
なお、A2019ではIBM Watsonのアクションが追加されていますが、自然言語処理(NLP)のアクションは、現状用意されていないため、別途準備する必要があります。
実施に当たり
今回の感情分析に必要なものについては、以下となります。
anaconda3(Pythonの実行環境)
janome(形態素解析エンジン)
また、Pythonスクリプトの実行にあたり、環境変数PATHを設定しておく必要があります。
感情分析にあたり、日本語の極性辞書は、東北大学 乾・岡崎研究室 / Author(s): Inui-Okazaki Laboratory, Tohoku Universityにて、公開されている「日本語評価極性辞書」を使用させていただきました。
A2019からの変更点
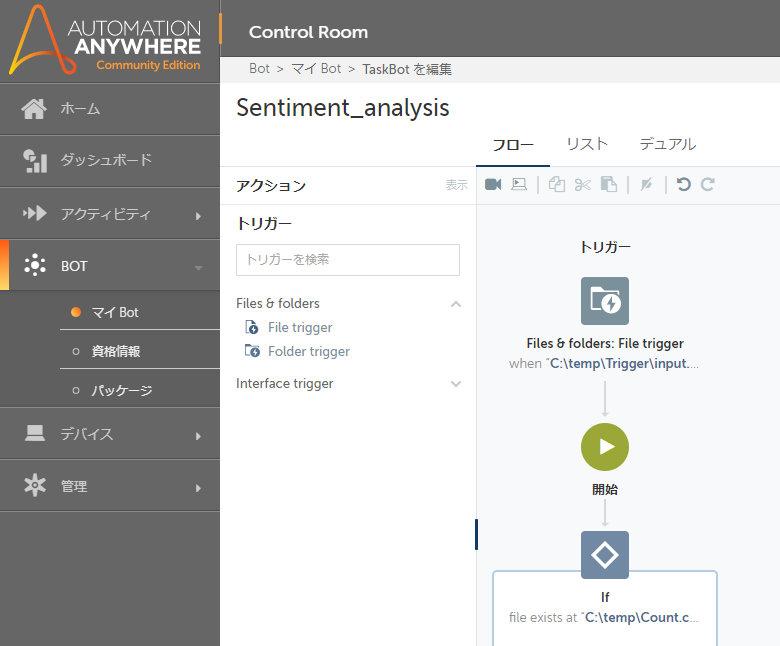
◆その1:フロー型のインタフェース提供
v11までは、リスト型の開発画面でしたが、フロー型の開発画面が提供され、視覚的にわかりやすくなったと思います。既存と同様の開発画面(リスト型)も準備されていますので、今まで開発してきて慣れ親しんでいる方は、リスト型を使用ください。この辺りはお好みで選択していただければと思います。
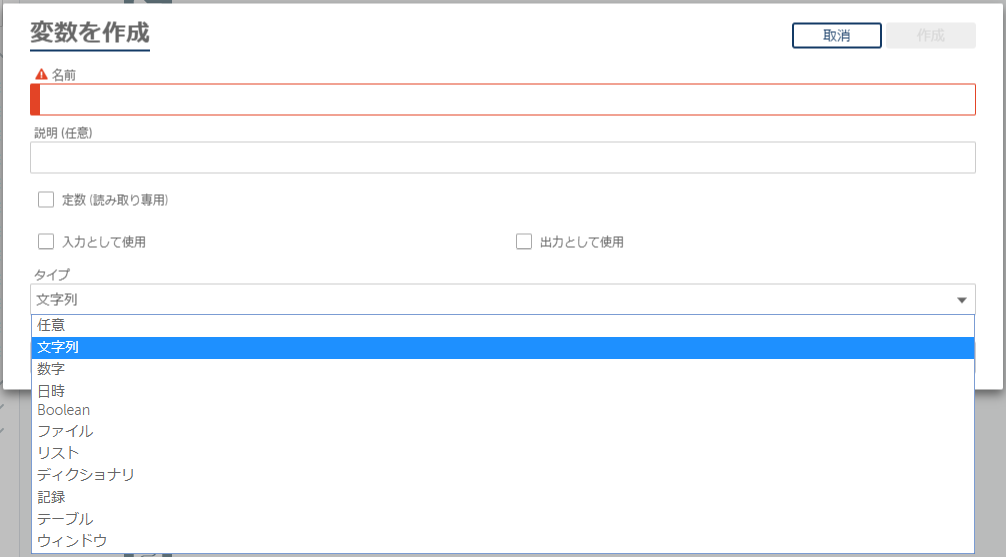
◆その2:変数の型について
v11までは、ExcelやCSVから値を取得する場合は、「Excel Column」、「Filedata Column」というシステム変数から値を取得することができましたが、A2019では変数を定義し、操作できるようになりました。
(いままで定義されていたシステム変数は、ほとんどありません。)
また、変数の型も定義する必要があり、If文等での比較についても、型を合わせる必要があるなど、今までとは異なり、プログラム言語に近くなりました。
(今までのやり方に慣れているユーザにとっては、A2019に慣れるまではやや違和感があるかもしれません。)
◆その3:Recorder
SmartRecorder、ScreenRecorder、WebRecorder、ObjectCloningがまとまり、Recorderになりました。 ブラウザについてもFirefoxやChromeがサポートされるなど、より汎用性が広がりました。
まだ正式版がリリースされていない状態ではありますが、SetText等のDelayがms⇒s単位に代わってしまい、処理時間が長くなってしまうため、こちらについては、早急に修正対応いただきたいと思います。
⇒ A2019の技術者の方と話す機会があり、改善要望として上げておいたので、リリースまでには対応されるものと思われます。(2019.12.3時点)
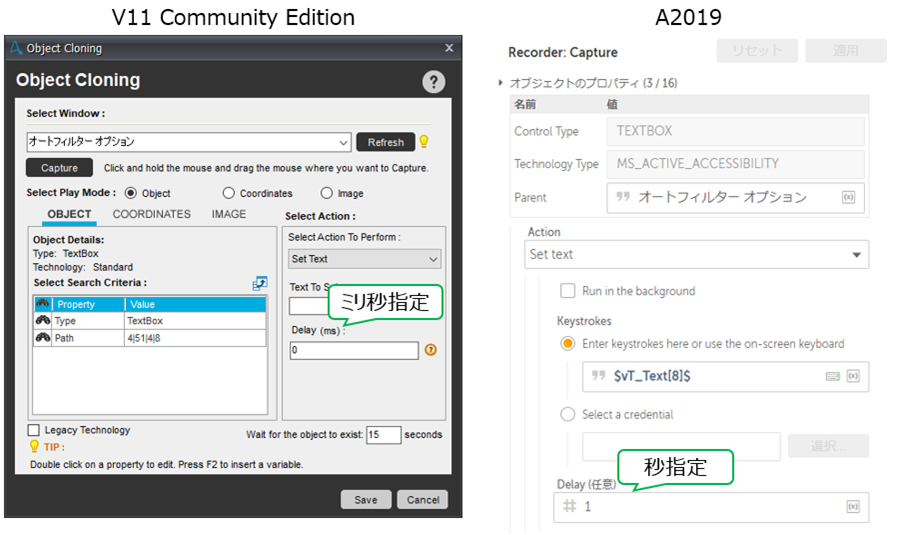
以上のように、操作性や変数定義など、開発者向けになったことで、プログラムを知らない人には、ハードルが上がったのではないかと考えます。
また、正式版のリリースに向け、頻繁にバージョンアップが行われ、メニューの日本語化や機能追加など日々進化を感じることができます。
しかし、現時点ではv11からの移行ツールは提供されておらず、タスクのコピーやダウンロードもできないため、今後のバージョンアップで改善され、より使いやすくなることを期待します。
A2019の仕様の話はこれぐらいにしておき、実際に感情分析を行ってみます。
実施内容
一連の作業の流れとしては、以下の通り。
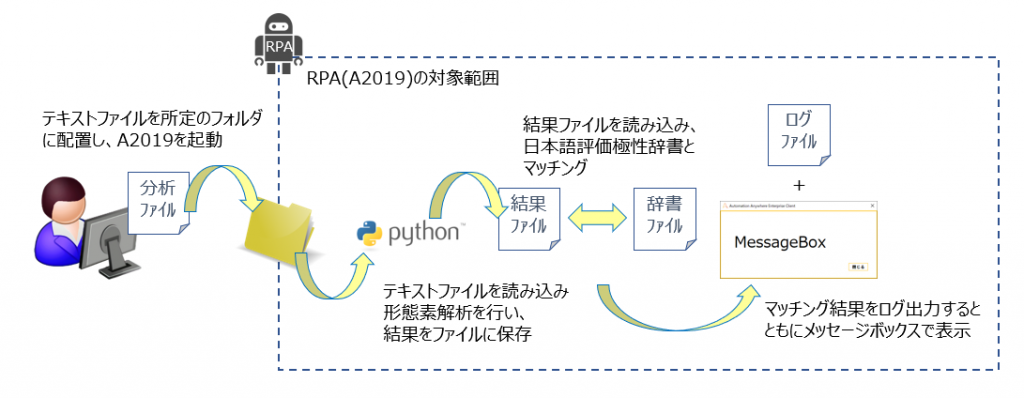
実行および結果
実際に2つの文書で、感情分析を行ってみます。
注:今回は原則、出力された単語を辞書と突合せ、評価を行っております。
また、分かち書きの段階で、記号、助詞、接頭詞は除外しています。
最初に、いかにもポジティブな感じの文書を分析してみます。
「今日は晴天で、気分が良かったので、心もリフレッシュできる森林浴に行き、楽しい一日を過ごした。」
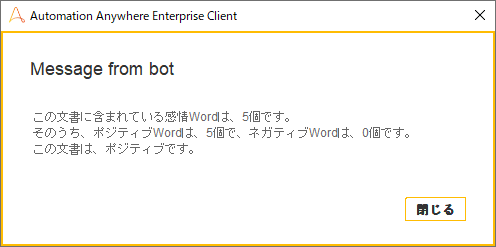
分かち書きした結果です。15個の単語が含まれています。

感情分析したところ、5つの感情が含まれている単語があり、最初に予想した通り、すべてがポジティブな単語でした。

次はいかにもネガティブな下記文書を分析してみます。
「今日は雨だからやる気もなく、天気が悪いこともあり、気分が落ち込んで、どこにも出かけることができなかった。」
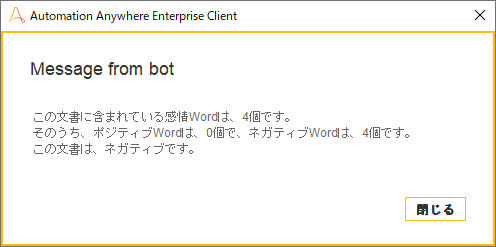
分かち書きした結果です。こちらは17個の単語が含まれています。

感情分析したところ、4つの感情が含まれている単語がありました。その中で「やる気」「できる」は、ポジティブな単語なのですが、そのあとに否定の「ない」があるため感情値を反転させています。
単語に否定の助動詞を組み合わせることで、感情が逆転するため、一部補正をかける必要があります。
(例:高いは、ネガティブとなりますが、高くない=安いとなり、ポジティブと扱う必要があります。)
結果、すべてがネガティブな単語と分析されました。

最後に、青空文庫にある、人間失格(太宰治)の「第一の手記」を感情分析してみました。
単語数3204のうち、感情が含まれている単語は268個でした。
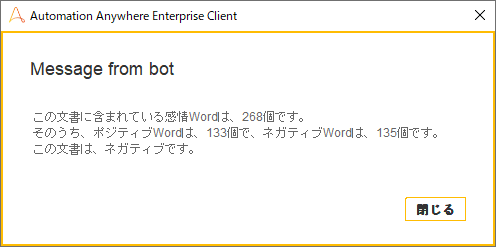
「人間失格」というタイトルや、書き出し部分からして相当ネガティブな結果になるのではないかと思ったのですが、上記のようにややネガティブという結果で、ちょっと意外でした。
実際に文書を読むとポジティブな単語が続いたあとに、そうではないという否定の発言につながる部分があり、単純に単語を拾うだけでは、ポジティブな文書として解析される点が多いことに気づきました。
今回は、このような結果となりましたが、利用する辞書によっては、結果が異なることも想定されます。
まとめ
今回は、A2019でスクリプト(Python)の実行が容易になったため、RPAと組み合わせて、感情分析が行えることを試してみました。fastTextやWord2Vecを用い、お客さまニーズにあった極性判定辞書を作ることで、より高い精度で感情値を付与できるのではないかと考えます。
BTCは、AutomationAnywhereの代理店であり、開発経験のあるエンジニアも在籍しております。また、最近ではAIや自然言語処理などの依頼も多く対応しております。自然言語処理やAutomationAnywhereの導入、実現性検証など、依頼がありましたらご気軽に相談ください。
参考
小林のぞみ,乾健太郎,松本裕治,立石健二,福島俊一. 意見抽出のための評価表現の収集. 自然言語処理,Vol.12, No.3, pp.203-222, 2005. / Nozomi Kobayashi, Kentaro Inui, Yuji Matsumoto, Kenji Tateishi. Collecting Evaluative Expressions for Opinion Extraction, Journal of Natural Language Processing 12(3), 203-222, 2005.
東山昌彦, 乾健太郎, 松本裕治, 述語の選択選好性に着目した名詞評価極性の獲得, 言語処理学会第14回年次大会論文集, pp.584-587, 2008. / Masahiko Higashiyama, Kentaro Inui, Yuji Matsumoto. Learning Sentiment of Nouns from Selectional Preferences of Verbs and Adjectives, Proceedings of the 14th Annual Meeting of the Association for Natural Language Processing, pp.584-587, 2008.
最新情報をお届けします!
RPAに関する最新コラムやイベント情報をメールで配信中です。
RPA領域でお仕事されている方に役立つナレッジになりますので、ぜび登録してください!









- July 2024 (1)
- June 2024 (2)
- May 2024 (3)
- April 2024 (1)
- March 2024 (1)
- February 2024 (1)
- January 2024 (1)
- December 2023 (1)
- November 2023 (2)
- October 2023 (3)
- September 2023 (1)
- August 2023 (4)