画像認識サービス【Learning Center Vision】を紹介します!
-
TAG
AI Learning Center Vision ノーコード 画像解析 -
UPDATE
2023/03/01
目次
1.はじめに
こんにちは。新年が始まり、3月に入りました。暖かい日も増えてきてそろそろ桜の季節ですね。桜と言えば、過去のコラムでは桜の開花も予測できるAIデータ解析サービス「Learning Center Forecast」を紹介しました。
今回は前回とは違った方向性でAIデータ解析サービスを紹介したく、画像認識サービス「Learning Center Vision」について執筆しようと思います。
画像認識を一から始める難しさと「Learning Center Vision」の手軽さを比較することで、「Learning Center Vision」の魅力をお伝えします!
2.「Learning Center Vision」とは?
「Learning Center Vision」は機械学習を用いて画像データをあらかじめ定められた識別結果(ラベル)に分類する、AI inside 株式会社が提供する画像認識サービスです。全ての操作がマウス操作で完結されており、機械学習の事前知識やチューニングなどを意識することなく画像認識サービスを作成することができます。
「機械学習」とは、「学習データを解析し、その結果を学習する技術のこと」で、学習した結果を基に予測や分類をすることができます。機械学習には「教師あり学習」「教師なし学習」「強化学習」の3種類があり、「Learning Center Vision」では「教師あり学習」が利用されています。
過去コラムで紹介されている「Learning Center Forecast」と同様、専門知識を必要とせず、簡単に精度の高いサービスを作ることが可能です。
「Learning Center Vision」は動画や画像を用いることでインフラ設備や小売り・卸売分野で効果をもたらすだけでなく、金融・製造・医療・不動産など様々な分野で活用されています。
| 分野 | AIモデルの識別内容 | 効果 |
| インフラ・設備 | 対象建造物の劣化箇所の検知、劣化状況を診断 | 点検作業の負担軽減や個人差による劣化診断のばらつきをなくし、安全性の向上を実現 |
| 小売・卸売 | 荷物に含まれる検品対象物の形状や個数を判別 | 検品作業の自動化、安定した品質や作業の効率化を実現 |
3.画像認識の複雑さ
まずは一般的な画像認識AIモデルを一から作る流れについて整理したいと思います。
この章につきましては、内容が専門的で理解しづらい方もいらっしゃると思いますので、「Learning Center Vision」が気になる方はこの章を飛ばして4章へお進みください。
画像認識を行うための流れとしては、画像データの準備(前処理)→学習アルゴリズムと学習モデルの選定→コーディングの流れになります。それぞれの過程において、専門知識が必要となり、ある一定以上の精度を持つ画像認識を行うためには、専門知識に基づく調整と検証が必要となるため、難易度が高いです。それぞれの手順を少し掘り下げて説明します。
画像データの準備(前処理)
まず初めに、画像認識を行うための「学習用画像データ」と「予測用画像データ」を準備します。教師あり学習ではもととなる学習用データのデータ量が少ない、または予測したいものに対して全く違う画像を学習用データとして入力している場合には認証精度が低くなります。
例えば、数字の0から9を識別するような画像認識を行いたいと考え、予測用画像データとして真ん中に数字が書かれているものを用意したのに、学習用画像データは左右に数字が寄って書かれていると認証精度が低くなります。
さらに、教師あり学習を行うため、学習用データと予測用データの1つ1つに対して何の画像であるかといったラベルを付ける必要があります。今回のようにハードコーディングを行う際には、画像データの大きさを28*28pixelなどすべて同じ大きさに揃える必要があり、画像データの一部分だけを画像認識に使用したい場合は、手作業で切り取りし、指定の大きさにリサイズする必要があります。
学習アルゴリズムと学習モデルの選定
この段階では、画像認識を行うために、学習アルゴリズムと学習モデルを決定します。 学習モデルとは、学習用データや予測用データを入力した際の結果(ラベル)を出力する関数のようなもので、学習アルゴリズムによって使用する学習モデルが異なります。
学習アルゴリズムとは、学習用データを学習モデルに入力した結果の誤りを限りなくなくすための手順や方法のことを示します。
画像認識において、学習アルゴリズムは畳み込みニューラルネットワーク(Convolutional Neural Network)がよく用いられています。畳み込みニューラルネットワークは学習用データを単なる1枚の画像として捉えるのではなく、1枚の画像を複数の領域に小分けすることによって、文字の特徴(形、傾き、色など)を認識することでより精度の良い画像認識を実現するための学習アルゴリズムです。
コーディング:Pythonを利用した画像認識の一例(手書き数字)
画像認識に用いられるプログラミング言語として、Python、R言語、Javaなどがあげられます。今回は、機械学習用のライブラリやフレームワークが充実しているPythonを利用して、数字0から9までの画像データを認識する画像認識を作成します。
画像認識に使用した学習データや学習アルゴリズム、学習モデルなどを以下にまとめました。
| 項目 | 内容 |
| 学習データ |
MNIST(手書き数字のデータセット) 学習用:60000枚 予測用:10000枚 |
| 学習アルゴリズム | 畳み込みニューラルネットワーク(CNN) |
| 学習モデル | 入力層、畳み込み層、出力層の3層のモデル |
| 開発環境 | Google Colaboratory |
学習モデルは単純な3層のモデルを用いました。精度をあげるためにはこの学習モデルの層を増やす、正規化を行う、などの調整が必要になり、トライアンドエラーを繰り返すことになります。この作業が画像認識のハードルを上げている一番の理由だと思っています。
開発環境のGoogle ColaboratoryはGoogle社が提供しているブラウザ上でPythonを記述、実行でき、開発環境が不要かつGPUに料金なしでアクセスできるサービスです。端末に開発環境や計算処理を行うスペックがない場合に非常に便利です。
以下作成したソースコードになります。
import os
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchvision import datasets, transforms
# ---------------
# ハイパーパラメータなどの設定値
num_epochs = 10 #学修を繰り返す回数
num_batch = 100 #一度に処理する画像の枚数
learning_rate = 0.001 #学習率
image_size = 28*28 #画像の画素数
# GPU(CUDA)が使えるかどうか?
device = 'cuda' if torch.cuda.is_available() else 'cpu'
#-----------------------------------
# 学習用 / 評価用のデータセットの作成
# 変換方法の指定
transform = transforms.Compose([
transforms.ToTensor()
])
# Mnistデータの取得
# 学習用
train_dataset = datasets.MNIST(
'./data', #データの保存先
train = True, #学習用データを取得する
download = True, #データがないときにダウンロードする
transform = transform #テンソルへの変換など
)
# 評価用
test_dataset = datasets.MNIST(
'./data',
train = False,
transform = transform
)
# データローダー
train_dataloader = torch.utils.data.DataLoader(
train_dataset,
batch_size = num_batch,
shuffle = True)
test_dataloader = torch.utils.data.DataLoader(
test_dataset,
batch_size = num_batch,
shuffle = True)
# -------------------------
# ニューラルネットワークモデルの定義
class Net(nn.Module):
def __init__(self, input_size, output_size):
super(Net, self).__init__()
# 各クラスのインスタンス(入出力サイズなどの設定)
self.fc1 = nn.Linear(input_size, 100)
self.fc2 = nn.Linear(100, output_size)
def forward(self, x):
# 準伝搬の設定(インスタンスしたクラスの特殊メソッド(__call__)を実行)
x = self.fc1(x)
x = torch.sigmoid(x)
x = self.fc2(x)
return F.log_softmax(x, dim=1)
#-------------------------------
# ニューラルネットワークの生成
model = Net(image_size, 10).to(device)
#--------------------------------
# 損失関数の設定
criterion = nn.CrossEntropyLoss()
#--------------------------------
# 最適化手法の設定
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
#--------------------------------
# 学習
model.train() # モデルを訓練モードにする
for epoch in range(num_epochs): #学習を繰り返し行う
loss_sum = 0
for inputs, labels in train_dataloader:
# GPUが使えるならGPUにデータを送る
inputs = inputs.to(device)
labels = labels.to(device)
# optimizerを初期化
optimizer.zero_grad()
# ニューラルネットワークの処理を行う
inputs = inputs.view(-1, image_size) # 画像データ部分を一次元へ並びかえる
outputs = model(inputs)
# 損失(出力とラベルとの誤差)の計算
loss = criterion(outputs, labels)
loss_sum += loss
# 勾配の計算
loss.backward()
# 重みの更新
optimizer.step()
# 学習状況の表示
print(f"Epoch: {epoch+1}/{num_epochs}, Loss: {loss_sum.item() / len(train_dataloader)}")
# モデルの重みの保存
torch.save(model.state_dict(), 'model_weights.pth')
# ---------------------
# 評価
model.eval() #モデルを評価モードにする
loss_sum = 0
correct = 0
with torch.no_grad():
for inputs, labels in test_dataloader:
# GPUが使えるならGPUにデータを送る
inputs = inputs.to(device)
labels = labels.to(device)
# ニューラルネットワークの処理を行う
inputs = inputs.view(-1, image_size) # 画像データ部分を一次元へ並び変える
outputs = model(inputs)
# 損失(出力とラベルとの誤差)の計算
loss_sum += criterion(outputs, labels)
# 正解の値を取得
pred = outputs.argmax(1)
# 正解数をカウント
correct += pred.eq(labels.view_as(pred)).sum().item()
print(f"Loss: {loss_sum.item() / len(test_dataloader)}, Accuracy: {100*correct/len(test_dataset)}% ({correct}/{len(test_dataset)})")
以下が上記のソースコードを実行した結果になります。数字0から9までの画像を96.82%の精度で識別できる画像認識ができあがりました。

以上のように、画像認識を一から組み立てて実装するためには、いくつもの専門知識が必要かつ多大な時間も要することが分かります。
4.「Learning Center Vision」の操作イメージ
今回紹介させていただく「Learning Center Vision」は、ここまでに紹介した学習アルゴリズムと学習モデルの選定等を自動で実施してくれるため、ユーザーはそれらに関する事前知識が一切なくとも使うことができます。
ユーザーが準備するのは学習させたい画像データのみです。もちろん画像認識に関するコーディング等も不要です!
それでは、「Learning Center Vision」の操作画面を見ていきましょう。
画像データの準備(前処理)
まず、どのような画像認識を行うのか、ワークスペースを作成します。
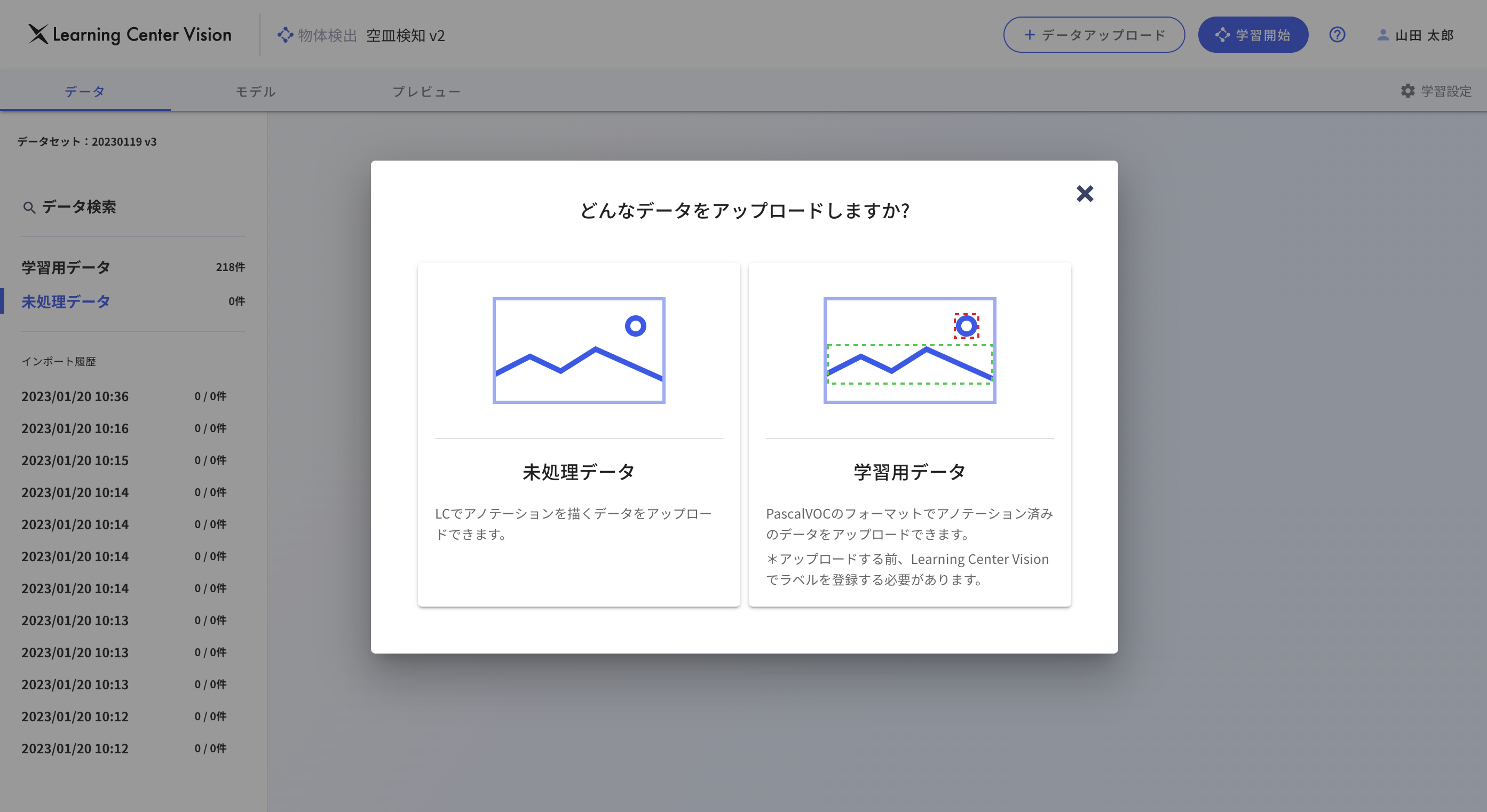
次に、先ほど作成したワークスペースに学習用データをアップロードします。
まず、画像認識で行う識別結果(ラベル)を作成し、画像データをアップロードします。 ブラウザから画像をアップロードする方法に加え、アップロード用のAPIも用意されているためRPAや別のシステムから画像をアップロードさせることも可能です。
次に、それぞれの画像に対して学習に用いたい部分をマウス操作で囲み、ラベルに対する学習用データを作成します。
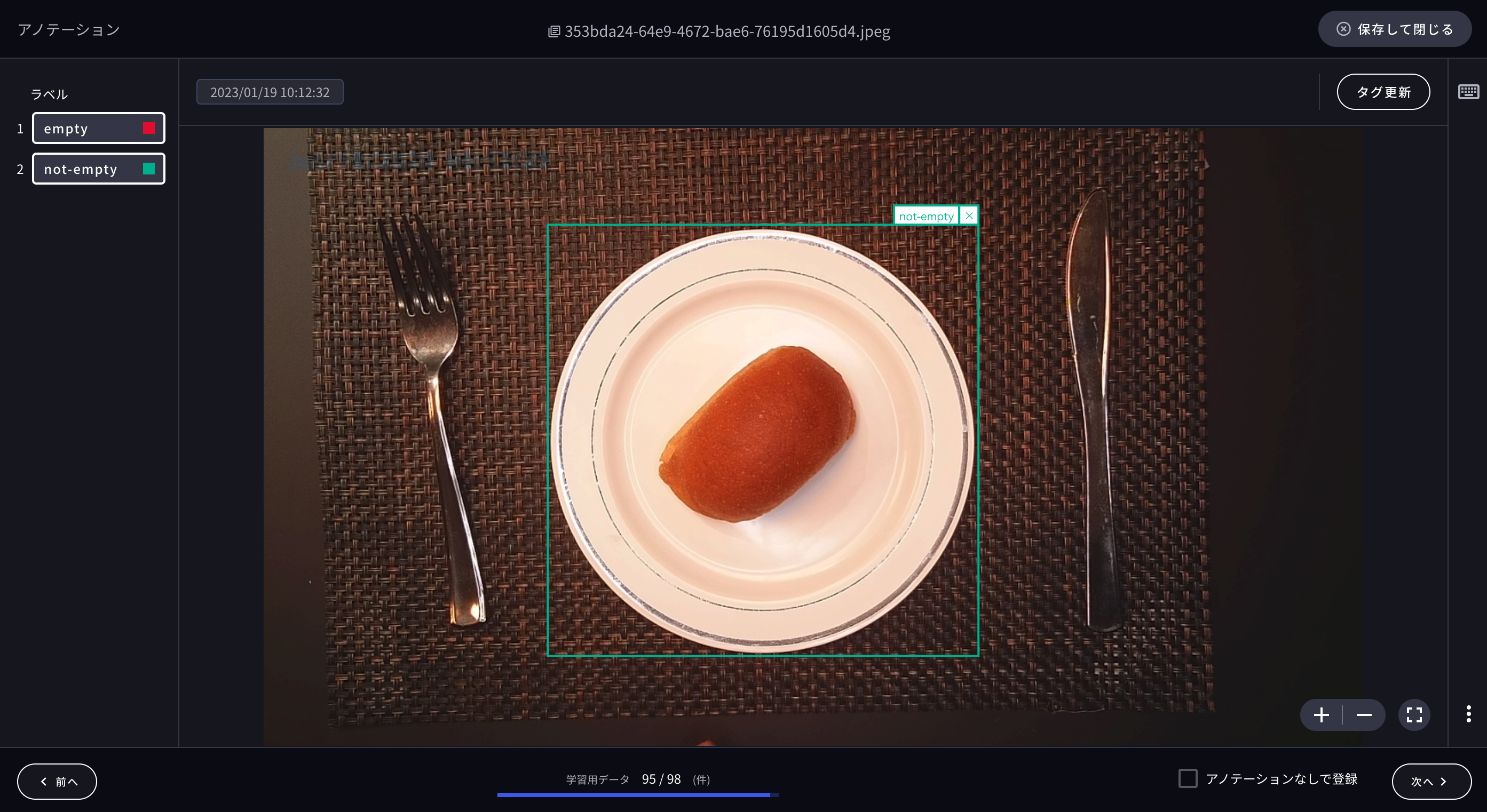
また、以下のように1枚の画像から複数の学習用データを作成することも可能です。
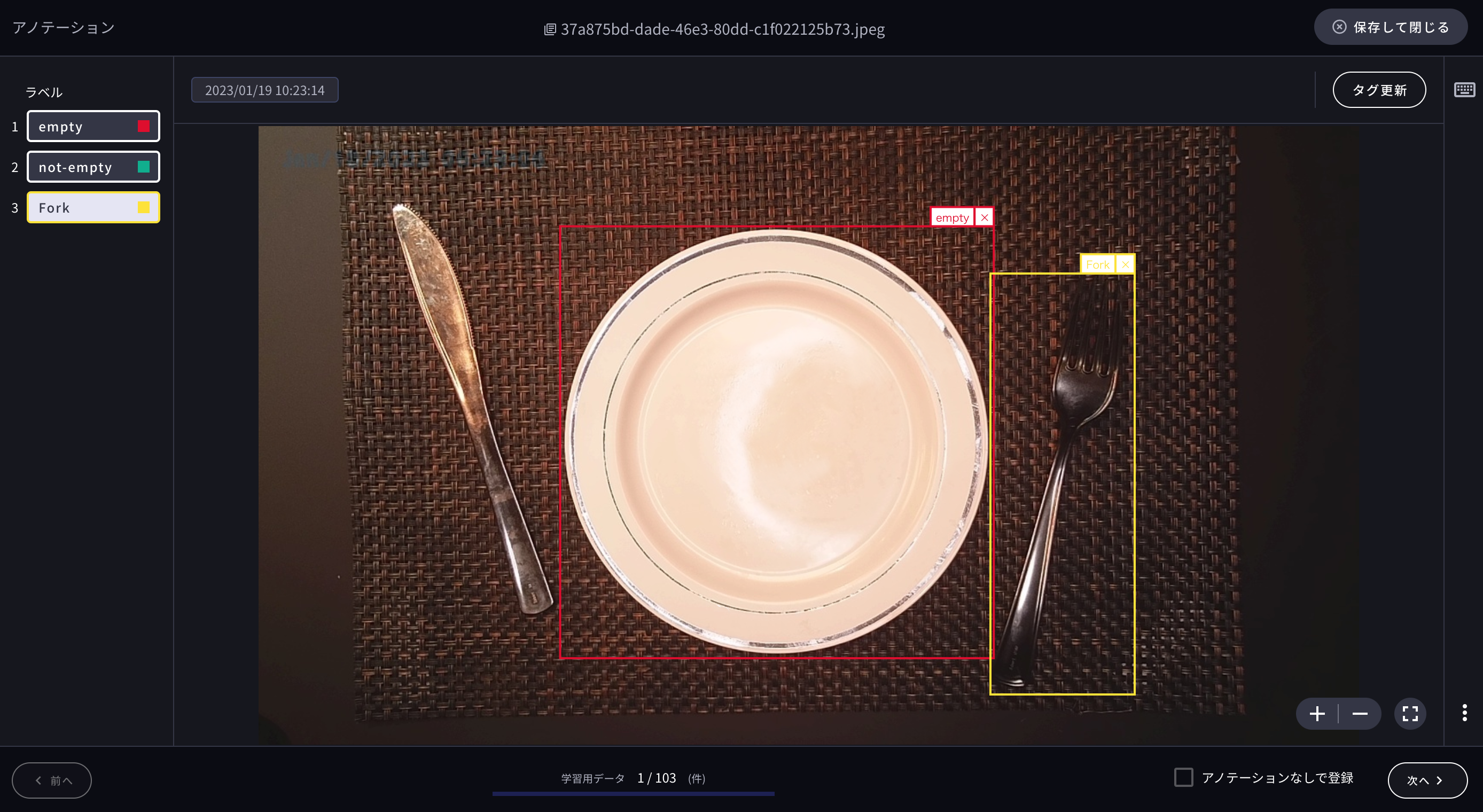
以上のステップのみで「Learning Center Vision」に用いる学習用データの準備が完了します。
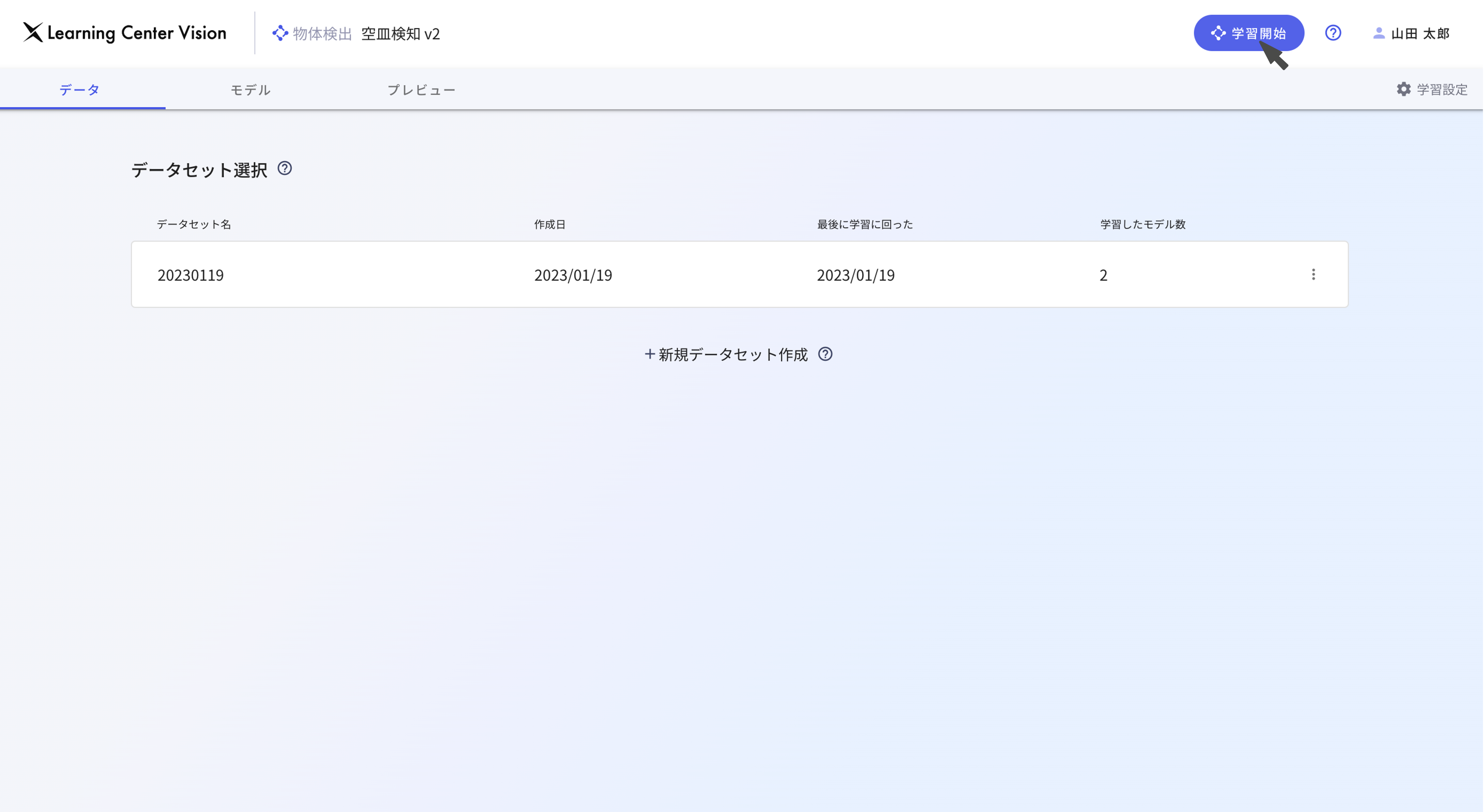
学習と利用方法
画像データの準備が終了し、右上の「学習開始」ボタンをクリックするだけで 「Learning Center Vision 」の学習が終了し、AI モデルが作成されます。
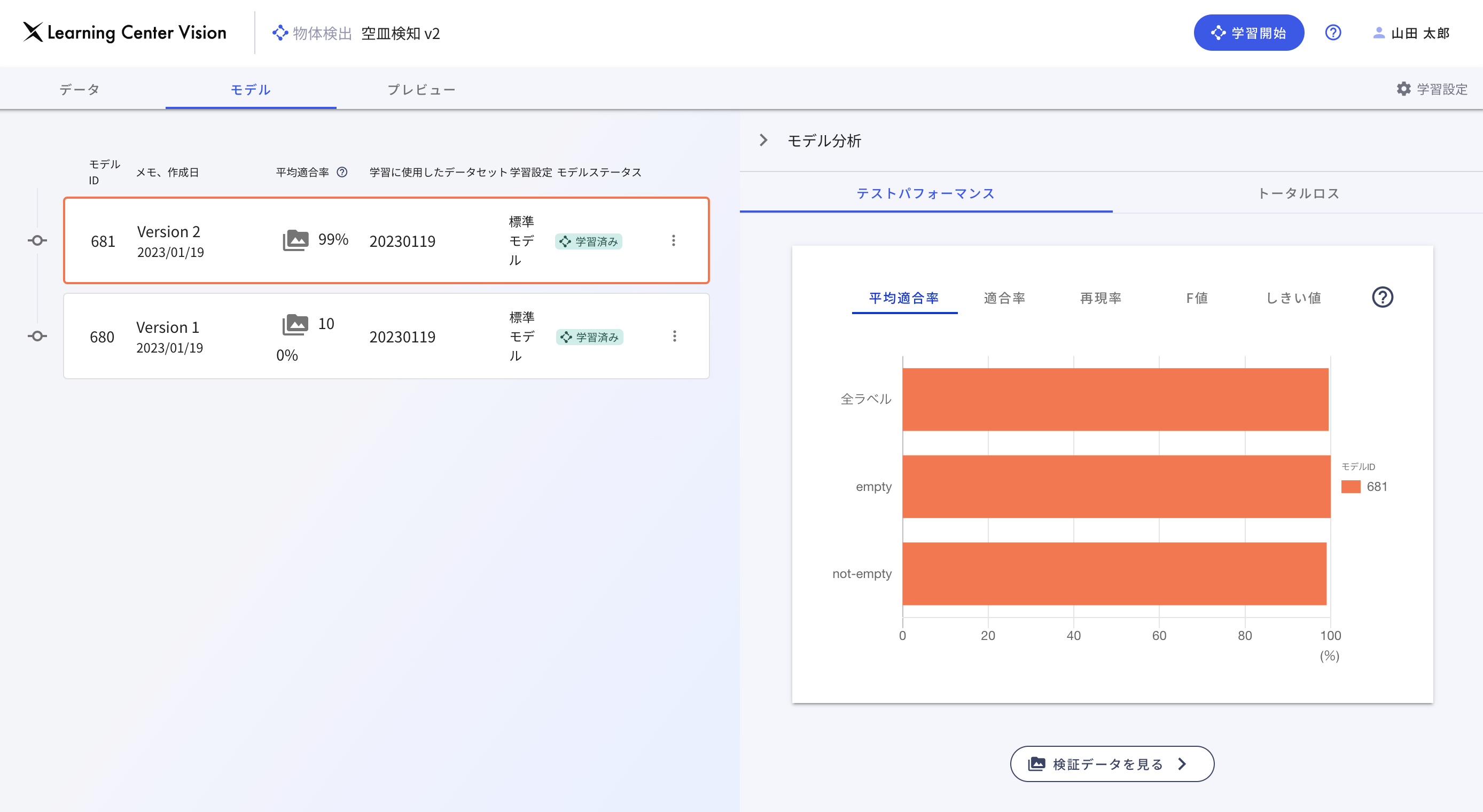
作成されたAIモデルが用意した学習用データをどのくらいの精度で検出できているかを確認することができます。
作成したAIモデルに認識させたい画像をプレビュー画面でアップしていきます。 画像をブラウザからアップロードすることで、特定のラベルに識別できる画像の範囲を囲ってその精度を表示してくれます。
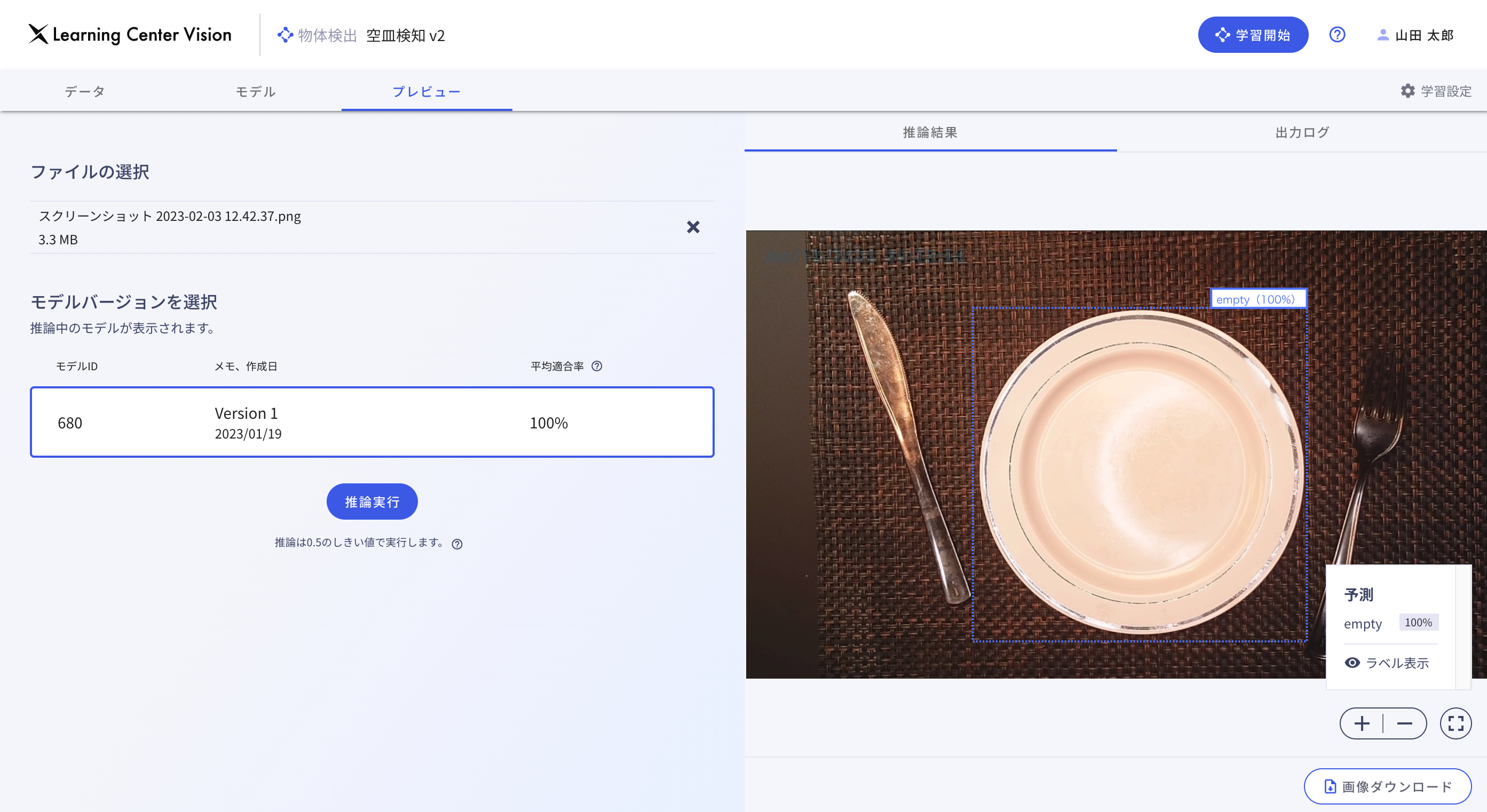
このように「Learning Center Vision」を導入することで大変手軽にAIでの画像認識が実現できることが分かりました。
5.おわりに
さて、長々と画像認識のコーディングから「Learning Center Vision」の使い方まで説明してきました。
画像認識のそれぞれのポイントをコーディングと「Learning Center Vision」で比較したものを以下にまとめました。
| 一般的な画像認識 | Learning Center Vision | |
| 学習用画像データの準備 | すべて同じ画像サイズに揃えてラベル付け | 様々な画像サイズでもマウス操作だけでラベル付けできる |
|
学習アルゴリズム 学習モデルの選定 |
事前知識を必要とし、どのアルゴリズム、モデルが最適なのかトライアンドエラーで模索 | 事前知識不要で、すべて自動で決定 |
| コーディング | Pythonなどのプログラミング言語 | なし |
画像データの準備が簡単になっただけでなく、画像認識に関する事前知識やプログラミング知識がなくても画像認識を行えること、操作方法が単純であることに非常に驚きました。
これまで導入が難しかった画像認識AIも、「Learning Center Vision」の登場により誰でも簡単に始めることができるようになりました。
弊社では「Learning Center Vision」のような画像認識以外のAIツールの取り扱いがあります。少しでもAIについてご興味がある方はぜひこちらへご連絡ください。
最新情報をお届けします!
RPAに関する最新コラムやイベント情報をメールで配信中です。
RPA領域でお仕事されている方に役立つナレッジになりますので、ぜび登録してください!









- November 2024 (2)
- October 2024 (3)
- September 2024 (2)
- August 2024 (4)
- July 2024 (1)
- June 2024 (2)
- May 2024 (3)
- April 2024 (1)
- March 2024 (1)
- February 2024 (1)
- January 2024 (1)
- December 2023 (1)