テキストマイニングによる自然言語文章の解析
はじめに
改めてテキストマイニングのその定義について触れます。
現在テキストマイニング自体は景気分析、マーケット分析などに使用されており、最近はAIと掛け合わせる活用方法も様々に出現しています。有名な例としてはチャットボットが挙げられます。非定型のテキストデータを分析することで、定型テキストデータより広範囲で詳細な情報を得ることができます。
新聞記事や自由回答によるアンケートなど、社会調査データ分析で用いられるテキスト型データを計量的に分析する手法として主に2つの手法が使用されていると言われています。そのうちの1つが上記で触れたテキストマイニングの手法になります。
どちらかのみを用いてきた2つの分析手法を組み合わせることで、分析者独自の視点・観点と、データ分析という点で重要な客観性、信頼性の均衡を取る手法が提唱されています。この手法の有効性とさらなる活用方法について言及していこうと思います。
テキスト型データの分析手法
■従来のテキスト型データの分析手法
テキスト型データの分析方法として、一般的にはデータを計量的に分析する手法がとられます。「計量的分析」と呼ばれるこの手法は、コンピュータを用いてデータをいくつかのカテゴリーに分類したうえで、各カテゴリーのデータの個数を数え上げる分析方法です。
計量的分析には2つの手法があり、従来はこの2つのうちどちらかを用いて分析が行われてきました。
A:Dictionary-based アプローチ = 質的分析寄りの手法
分析者が分析を行いたい理論、仮説に従って分類基準(コーディングルール)を作成し、それに基づいて分類(コーディング)、分析を行う手法。- メリット
- ✓分析者の理論、仮説に基づきテキストデータの様々な側面に焦点を当てて分析することが可能
- デメリット
- ✓意図的、無意識的に理論や仮説に都合のよい分類基準が作成されてしまう
-
- ✓分類基準を作成するのは人のため、基準のブレが分類、分析のブレになる
-
- ✓データの全体像から分類基準を作成するため、データ量が増えると分類基準の統一性の保持が難しくなる
B:Correlational アプローチ = 量的分析寄りの手法
分析対象のテキストデータを、多変量解析により自動的にグループに分類し分析を行う手法。この手法が所謂「テキストマイニング」と呼ばれるものである。
- メリット
- ✓データを自動的に分類することで、人依存による分類のブレをなくすことができ、客観性を保持できる
-
- ✓コンピュータを用いることで膨大なデータ量を処理できる
- デメリット
- ✓分析者の理論、仮説に基づいたデータ操作が困難である
※ただし、出現回数の少ない語を似通った語同士でまとめたり、分析に必要な語のみを選択したりと、従来のこのアプローチにはDictionary-based アプローチに通ずるある種の手作業が発生しており、一般的な多変量解析とは異なった様相を呈するものとなりうる。

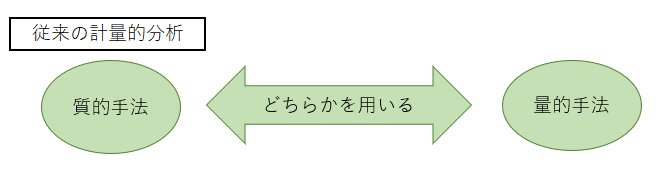
従来の計量的分析ではAかBどちらかを用いることがほとんどのため、それぞれが独自でその技術を発達させてきました。互いにメリットデメリットがある中、ABを組み合わせることでそれぞれの短所を補い合うことが可能だと考えられます。
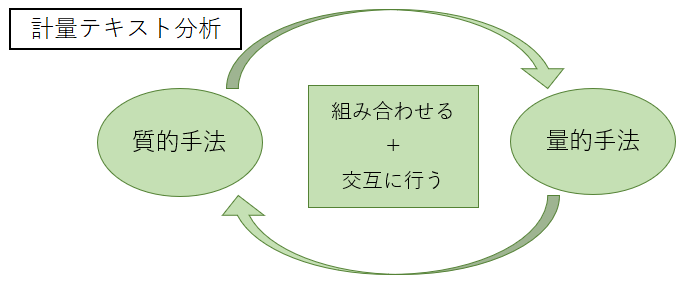
■提唱される手法
質的な分析、量的な分析を明確に区別しつつ組み合わせることで、双方のメリットを取り入れることができ、また各々の作業を交互に相乗的に行うことでより精度の高い分析が可能となります。この手法を「計量テキスト分析」と呼びます。
計量テキスト分析の手法 = 量的分析+質的分析
- ①量的分析の段階 = データの全体像を把握する
分析者の理論や仮説など、人の意識の影響をなるべくなくし、機械的にデータを分類、要約、整理する段階。
②質的分析の段階 = データを探索、追及する
①のデータを元に作成したコーディングルールにより、理論、仮説、問題意識を操作しデータを分析する段階。
- 従来の手法との比較
✓①と②の段階を明確にすることで、データに対する客観性を担保できる
✓①により大量のデータの全体像を把握しやすくなり、データに即したコーディング規則の作成が容易となる
✓②で作成したコーディング規則を用いることで、理論、仮説に沿ってデータを操作し分析することが可能となる
■システムについて
従来の分析手法であるA:Dictionary-based アプローチと、B:Correlational アプローチのどちらかに即したシステムはそれぞれ存在しましたが、両アプローチを兼ね備えたシステムはありませんでした。仮に既存のシステムを用いて提唱する計量テキスト分析の手法を実現する場合、それぞれの段階ごとで別のシステムを用いる必要があります。基本的な仕様の違いによる結果の違いが生じるため、既存システムの併用は困難であると考えられています。
そこで両方のアプローチ、すなわち提唱する計量テキスト分析の手法を実現するフリーソフト「KH Coder」が作成され、その処理方法はすべて公開されています。なお、この「KH Coder」が作成、公開された後に、商用システムとして、「KH Coder」の考え方に近いものも発売されています。「KH Coder」にない感情・評価を判別する機能があるなど、分析用システムも進化の一途を辿っています。
現状と今後の活用
■現在の活用形態
以下の場面で【AI×テキストマイニング】が活用されています。
✓アンケート調査、自由回答式の回答欄の分析
→ネットワーク分析などを用いることで、何について言及しているのかを判断
✓コールセンターでの問い合わせ内容の分析
→ネガティブワードを学習させてアラートを上げる
→顧客満足やクレームの分析し、対応フローを振り分ける
✓SNSなどのビックデータの分析
→マーケット調査、将来予測
■課題と今後の活用への期待
技術的な制約
上記で述べた計量テキスト分析の手法では、量的分析の結果(=テキストマイニングの結果)をもとに分析者がコーディングルールを作成し、コーディングルールをもとにコンピュータがコーディングを行っています。しかし、今の技術では単純なコーディングしか自動処理できず、複雑な事柄や概念によるコーディングになると対応できない場合もあります。この場合、AI技術の更なる向上により、より複雑なコーディングが可能となるかもしれません。機械学習・ディープラーニングといった技術を用いることで、複雑なコーディングルールを学習し自動分類が可能な範囲が広がると期待します。
ただし、すべてを機械学習による自動分類が可能であるとは考えられず、自然言語が人間独特の技術である以上、最後の一線を判断するのは人間の役割として在り続けると考えます。自然言語を分析する際は、どこまでが自動に処理するもので、どこからが人間による判断によるものなのか、はっきりと区別しておく必要があるのでないのでしょうか。
おわりに
今後はテキストマイニングの技術をRPAなどの具体的なシステムと組み合わせて活用する方法について考えていきたいと思います。どうぞご期待ください。
参考
『社会調査のための計量テキスト分析 内容分析の継承と発展を目指して』樋口耕一(2014)ナカニシヤ出版
最新情報をお届けします!
RPAに関する最新コラムやイベント情報をメールで配信中です。
RPA領域でお仕事されている方に役立つナレッジになりますので、ぜび登録してください!









- September 2024 (2)
- August 2024 (4)
- July 2024 (1)
- June 2024 (2)
- May 2024 (3)
- April 2024 (1)
- March 2024 (1)
- February 2024 (1)
- January 2024 (1)
- December 2023 (1)
- November 2023 (2)
- October 2023 (3)




