AIデータ解析サービス【Learning Center Forecast】技術検証やってみた
-
TAG
AI AMATERAS RAY 機械学習 -
UPDATE
2022/05/26
1.はじめに
こんにちは。新型コロナウイルス感染拡大から早2年半。もうすぐ季節は梅雨となり、じめじめと蒸し暑い時期がやってきますが、ようやくマスク生活も終わりに近づいてきましたね。体調には気を付けて、楽しい夏をお過ごしください。
さて、ちょうど1年前にAIデータ解析サービス「Learning Center Forecast」を触ってみた内容のコラムを執筆しました。今回は前回に引き続き、桜の開花日予測を「Learning Center Forecast」を使ってやってみたいと思います。
2.「Learning Center Forecast」とは?(おさらい)
まず「Learning Center Forecast」と「機械学習」について、簡単におさらいしていきましょう。
「Learning Center Forecast」とは「機械学習を用いて学習用データから最適な予測結果を算出する、AI inside 社のAIデータ解析サービス」です。
また、「機械学習」とは「学習させたいデータを解析し、その結果を学習する技術のこと」で、学習した結果を基に予測や分類をすることができます。機械学習には「教師あり学習」「教師なし学習」「強化学習」の3種類があり、Learning Center Forecastでは「教師あり学習」が利用されています。
「Learning Center Forecast」についてより詳しく知りたい方は前回コラムをご覧ください。
3.「Learning Center Forecast」技術検証やってみた
それでは、Learning Center Forecastを使って今年の桜の開花日予測を行っていきましょう。
今回は、前回コラム執筆時に比較的予測精度が低かった3都市(東京・広島・福岡)について予測します。桜の開花日予測には、2~4月の平均気温と最高気温、2/1から桜の開花日までの日数のデータが必要なので、各情報は気象庁のHPから参照しています。
一般的に、機械学習の予測精度が低い原因は、主に以下の3つと言われています。
1.学習用データの量が少ないこと
2.学習用・予測用データの質が低いこと
3.予測モデルの作り方が悪いこと
この3つの原因について、前回と今回では以下のように変更して予測精度が上がるかを検証していきます。
| 原因 | 前回 | 今回 |
| 1 | 学習用データを2000~2020年までの21年分を使用 | 学習用データを1953~2021年までの69年分を使用※ |
| 2 | 学習用・予測用データ共に、7都市全てを1ファイルで作成 | 学習用・予測用データ共に、各都市ずつファイルを作成 |
| 3 | 7都市を1つの予測モデルに集約 | 1都市につき1つの予測モデルを作成 |
※Learning Center Forecastでは学習用データは最低100データ必要ですが、1952年以前の気象庁の桜の開花日のデータがなかったため、1953年以降のデータを使用します。
まず初めに、「学習用データ」と「予測用データ」を準備します。
Learning Center Forecastで利用している「教師あり学習」は、「学習用データを基に、そのデータがどんなパターンになるかを予測するもの」なので、元となる学習用データは非常に重要です。前述した通り、学習用データのデータ量がそもそも少ない、または、予測したいものに対して全く関係ない値を学習用データとして入力している場合には予測精度が低くなります。学習用データを作成する際は、予測対象に対してどの値が必要なのか、十分検討するようにしましょう!
また、学習用データと予測用データのフォーマットは合わせ、予測用データに目的変数を記載しないように注意してください。学習後に予測用データを読み込ませる際には、カラムの設定はできません。今回は開花日までの日数を予測するため、予測用データに「2/1から開花日までの日数」は記載していません。
それぞれのデータには、以下の情報が記載されている必要があります。
- 目的変数 … 予測させたい対象のこと。(今回は、2/1から開花日までの日数)
- 説明変数 … 目的変数を求めるために必要な情報のこと。(今回は、2~4月の平均気温と最高気温と都市名)
- Index … データをナンバリングすること。
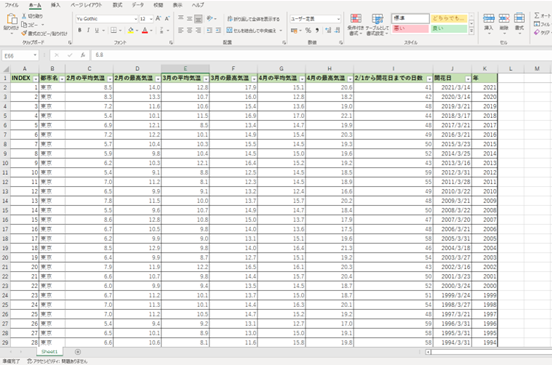
上の3つのデータを記載した学習用データと予測用データは、それぞれ以下のように作成しました。3都市それぞれの学習用データと予測用データを作成していますが、ここでは東京のみ添付します。
・学習用データ
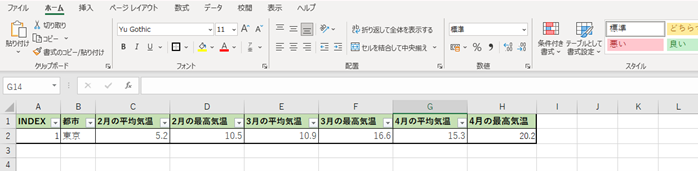
・予測用データ
実際にLearning Center Forecastに学習用データと予測用データを読み込ませていきます。ここでは一部画面のみ抜粋して紹介しますので、どんな画面が表示され学習されるのかは、前回コラムをご覧ください。
早速プロジェクトを作成します。
無事プロジェクトが作成されました。
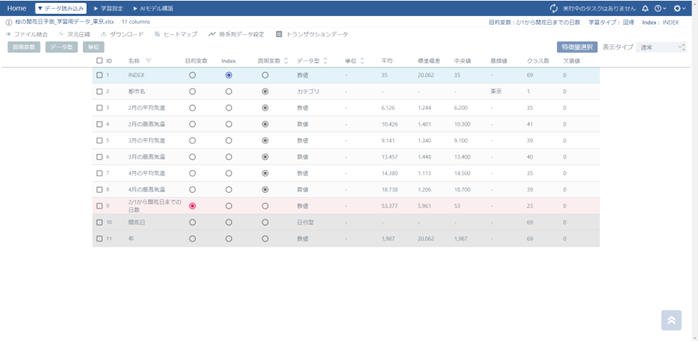
作成されたプロジェクトの目的変数とIndex、説明変数を設定します。「開花日」と「年」は予測に不要のため、非活性にしています。
学習用データをLearning Center Forecastに読み込ませて学習させていきます。
今回はアルゴリズムを「全選択」、評価指標が「MAE(平均絶対誤差)」、学習設定を「簡単モード」に設定します。
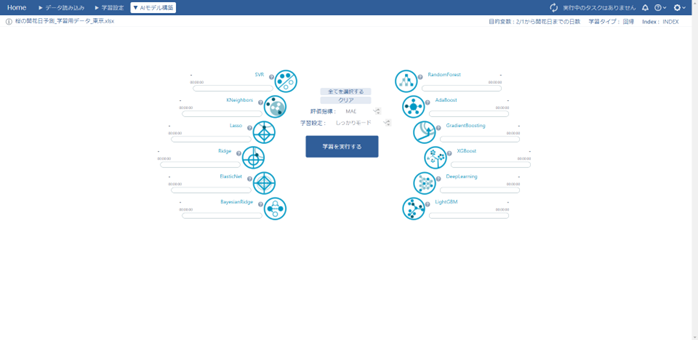
Learning Center Forecastには12のアルゴリズムが設定されており、学習用データに応じて最適なアルゴリズムを選択することができます。
評価指標とは「モデルの性能を評価するための基準のこと」で、4パターンのうち1つを設定することができます。「MAE(平均絶対誤差)」が標準で設定されています。
学習設定では、より良くデータをフィッテングするために様々なパラメータを変更することも可能なようで、「簡単モード」「通常モード」「しっかりモード」の3つから選択することができます。
学習が終了しました。学習にかかった時間は約4分でした。
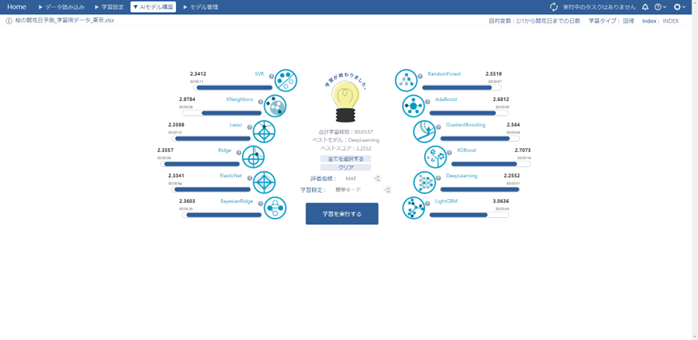
次に、学習させたアルゴリズムについてホールドアウト検証を行い、予測モデルを作成していきます。
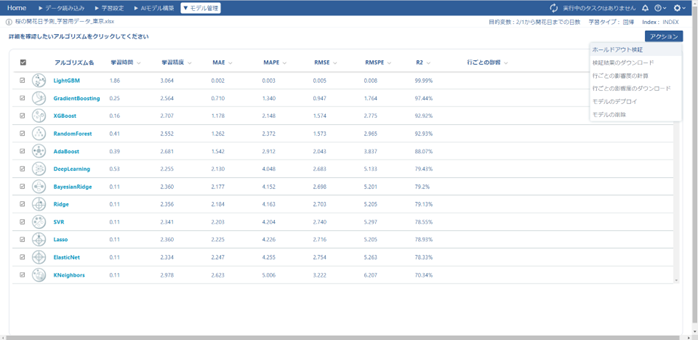
ホールドアウト検証が終わると、検証結果が表示されます。
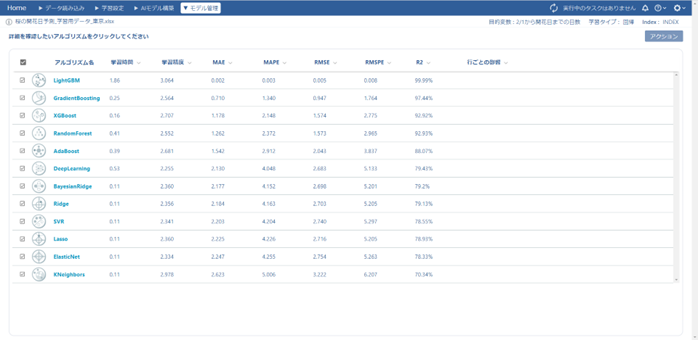
今回は評価指標を「MAE(平均絶対誤差)」に設定したので、「MAEが小さい=誤差が小さい」ということになり、評価指標が良い順にアルゴリズムが並び変えられます。MAEが最も小さく検証結果が良いアルゴリズムは「LightGBM」なので、この予測モデルをデプロイします。
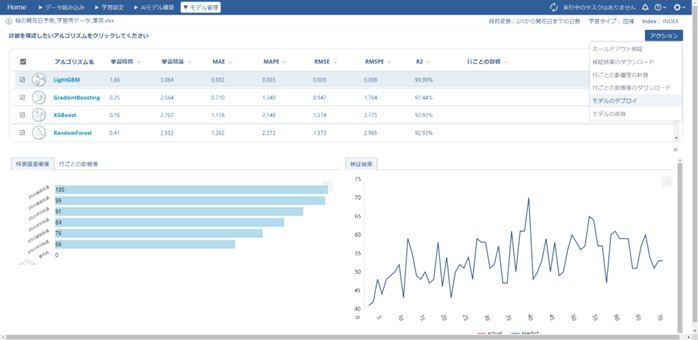
「データ予測」画面を開き、予測用データを読み込ませて予測を開始します。
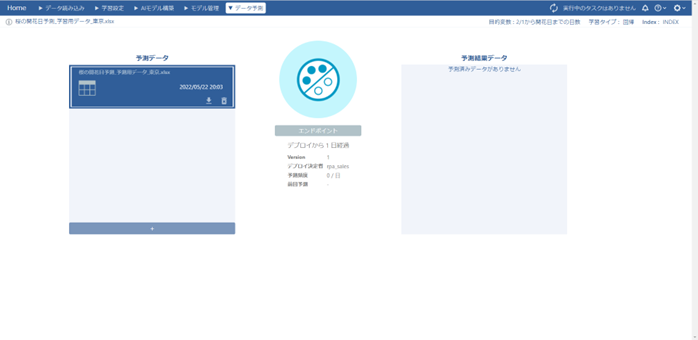
予測開始からほんの数秒で出力された予測結果データをダウンロードします。
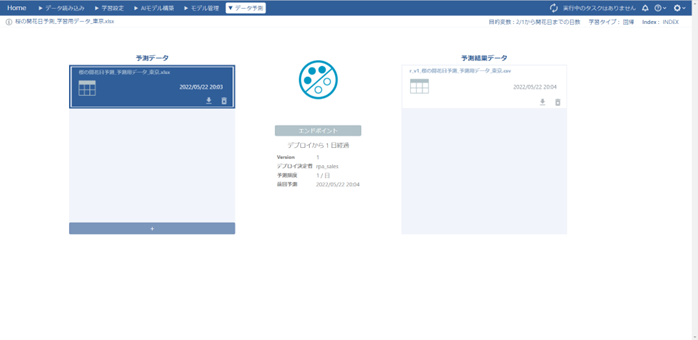
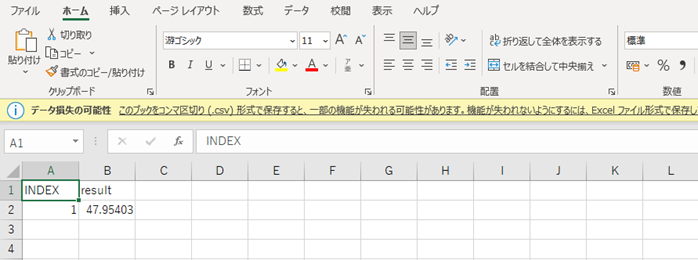
ダウンロードした予測結果データはこのようになりました。
広島と福岡の開花日も同様に予測していきます。因みに、広島と福岡の最も精度が高いアルゴリズムは「XGBoost」でした。
Learning Center Forecastで予測した桜の開花日と実際の開花日を比較した結果がこちらです。

また、前回と今回の予測結果は以下の通りです。
| 都市 | 前回誤差(日) | 今回誤差(日) |
| 東京 | 3 | 0 |
| 広島 | 6 | 1 |
| 福岡 | 5 | 2 |
3都市全ての誤差が前回よりも小さくなり、東京は予測日と実測日が一致しましたね!ウェザーニュースは福岡が3/17と予測しており、今回のAMATERAS RAYの予測誤差がより小さいことがわかります。
4.終わりに
今回はLearning Center Forecastの技術検証ということで、前回とは少しやり方を変更して、桜の開花日を予測してみました。学習用データと予測モデルの作成を一工夫することで、より予測精度を上げることができたので、AI予測をしているものの精度が低くて悩んでいるという方は、ぜひご参考にしていただければと思います。
また、Learning Center Forecastだけではなく、弊社ではAI推進も行っておりますので、AIや機械学習に少しでも興味がある方は是非ご連絡いただければと思います。
長くなりましたが、最後まで読んでくださり、ありがとうございました!
最新情報をお届けします!
RPAに関する最新コラムやイベント情報をメールで配信中です。
RPA領域でお仕事されている方に役立つナレッジになりますので、ぜび登録してください!









- November 2024 (2)
- October 2024 (3)
- September 2024 (2)
- August 2024 (4)
- July 2024 (1)
- June 2024 (2)
- May 2024 (3)
- April 2024 (1)
- March 2024 (1)
- February 2024 (1)
- January 2024 (1)
- December 2023 (1)