Automation AnywhereのIQBot精度比較
はじめに
以前のコラムで、Automation Anywhere社が提供するEnterprise A2019版についてご紹介いたしました。
【簡単でおすすめ】高性能なAI-OCRが無料で試せるIQBotを使ってみませんか?
今回は、その中のOCR製品であるIQ Botを使用し、 画像を抽出する際に利用するOCRエンジンごとの精度比較を行っていきたいと思います。

今回はIQ Botが対応している上記の3種類のOCRエンジンにおいて、英語活字、英語手書き、日本語活字、日本語手書きの4種類の組み合わせで精度検証を行います。
IQ Botの使い方
まずはOCR精度検証の前に簡単にIQBotの簡単な使い方をご紹介します。
Community Edition版はAutomation AnywhereのHPからEntryすることで簡単に使用が可能です。
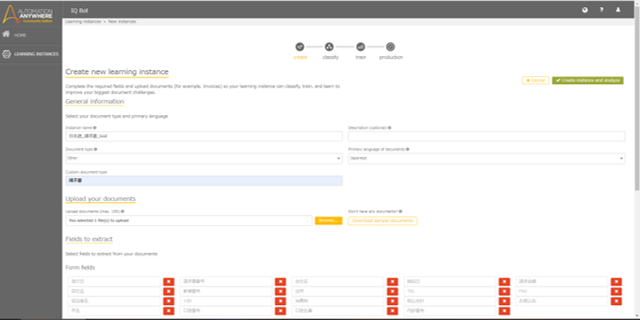
Entryが完了し、Community Edition版のIQ Bot画面を開くと、My learning instancesというメニューがあります。
右上の「New instance」をクリックし、新規で学習モデルを作成します。

General informationではインスタンス名、説明、帳票のタイプ、読み取る言語を設定し、 Upload your documentsにて、学習させたい帳票をアップロードします。
この時、Primary language of Documentsにて言語の設定を行いますが、 Document TypeはOtherを選択すると日本語が選択できるようになります。
Fields to extractでは帳票内の読み取りたい項目名を設定します。
Create instance and analyzeを押下した次の画面では、項目の場所などの設定を行いますが、 設定した項目名と帳票に存在する項目名が一致する場合は、自動で抽出が行われるというのが IQBotのポイントです。
また、この段階で設定した項目に、後ほど項目を追加することは可能ですが、 削除ができないので注意が必要です。
そして、読み取りたい項目が複数行あるものに関してはField to extractではなく、 Table/repeated section fieldsの方に設定を行う必要があります。
今回の帳票ではNo、項目、数量、単位、金額を設定しています。

また、Advanced Settingsの部分でOCRエンジンを選択できます。
今回はこちらのOCRエンジンをABBYY、Microsoft Computer Vision、Google Visionにそれぞれ設定し 読み取り精度の比較を行います。
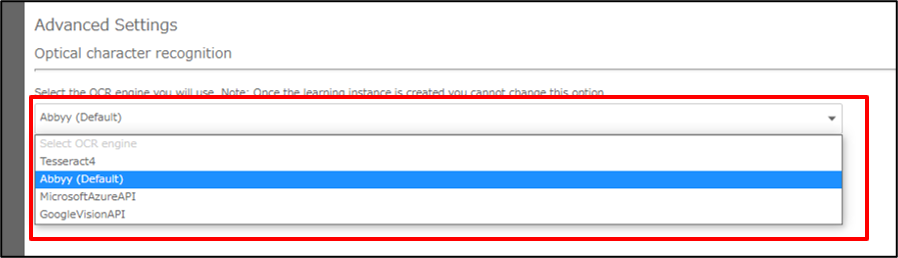
設定が完了したら「Create instance and analyze」を押下し、次の画面にうつります。
次の画面ではどの場所の値を読み取るかを設定することができます。
先ほどFields to extract設定画面にて述べましたが、設定した項目名と帳票に存在する項目名が一致している部分は既に自動で抽出が行われています。
なので、ここでは自動で抽出されているけれども間違った箇所が取得されている場合や、 項目名自体の場所が特定できていない場合の修正を行います。
例えば以下の図の中で、請求金額を取得したいのですが帳票内に請求金額という言葉がないため値が取得できていません。
そのため、まずField Labelで近くにあるラベルを設定し、Field Valueに取得したい値の場所を設定します。
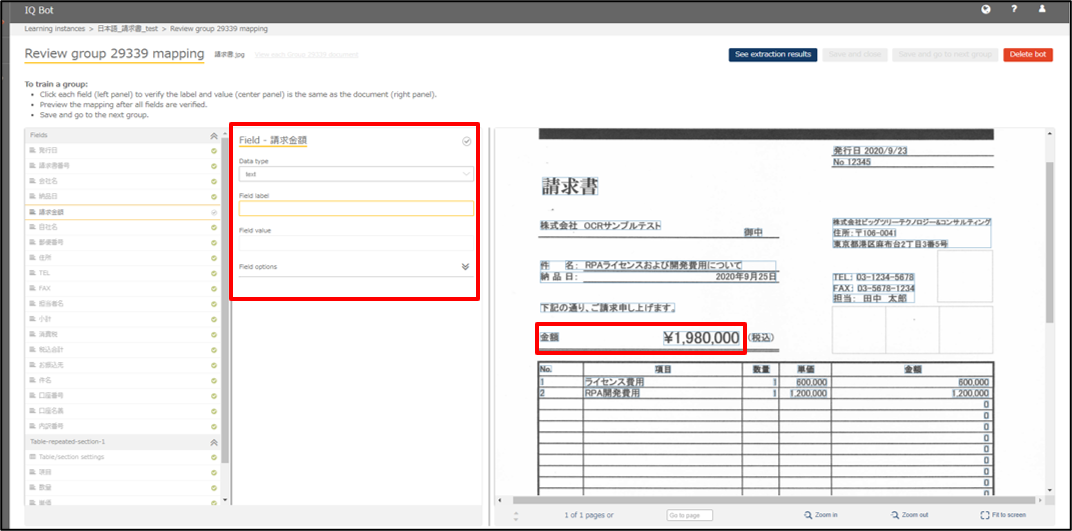
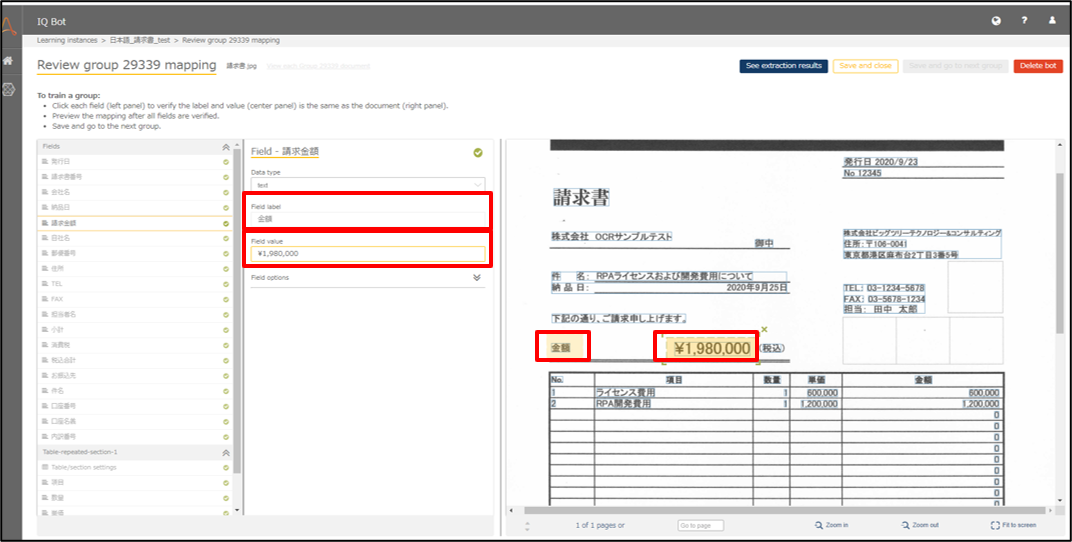
設定が完了したら、See extraction resultsにて抽出結果を確認します。
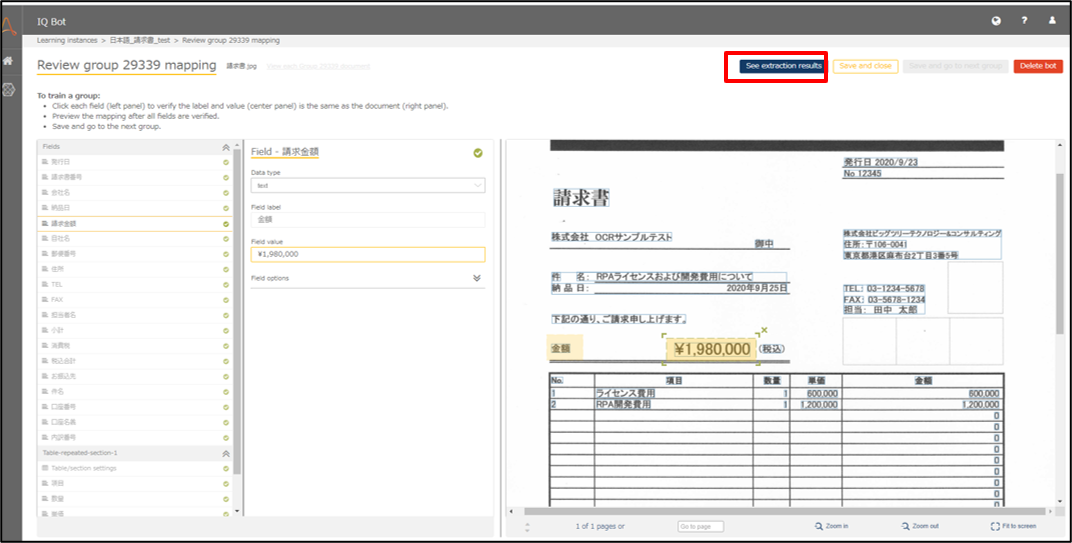
実際にどの値が抽出されているかを確認すると、発行日の部分に関しては 「2020/9/23」という値のみ取得したいのですが、発行日という文字まで入ってしまっています。
項目位置の設定が甘かったので、Back to trainingを押下して先ほどの設定画面に戻り、修正を行います。
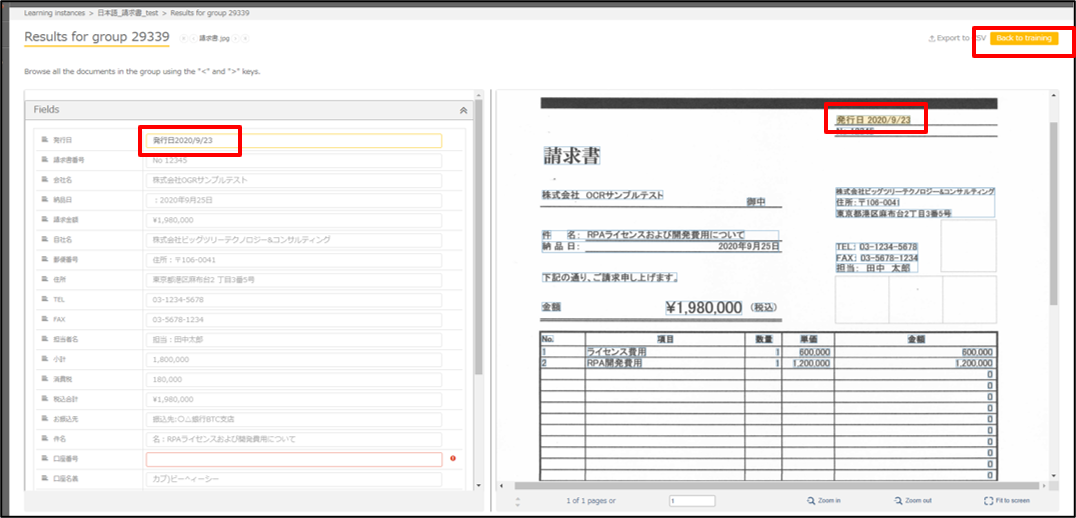
戻って確認してみると、Field labelとField valueの範囲が広すぎて、横の値まで範囲に含まれていることが分かります。

Field labelを発行日のみに修正し、valueの位置も発行日に重ならないようにします。
valueに発行日が入ってしまっていますが、範囲は正しいので再度See extraction resultsを確認してみましょう。
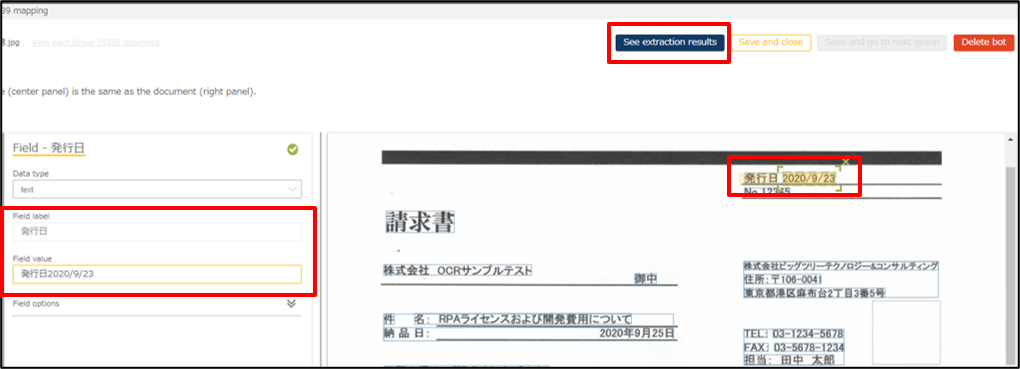
すると今度は発行日に「2020/9/23」のみ値が入っていることが確認できました!
このような修正を繰り返して読み取り位置を設定していきます。
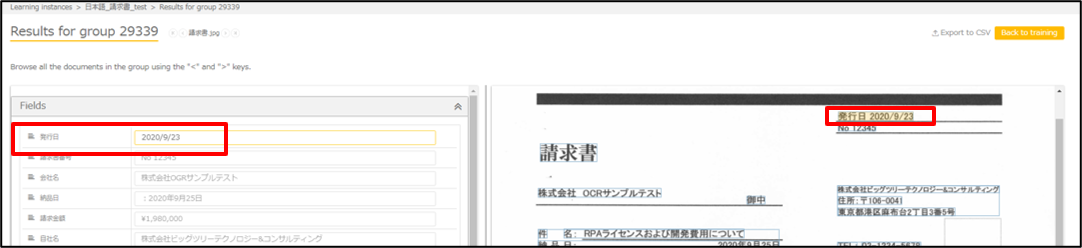
続いてはテーブルの設定です。
Table repeated section 1 に、テーブルに設定した項目が入っています。
Column name に取得したい列名、Column valueには取得したい列内の値の最初の場所をそれぞれ指定します。
See extraction resultsを押下して確認してみましょう。
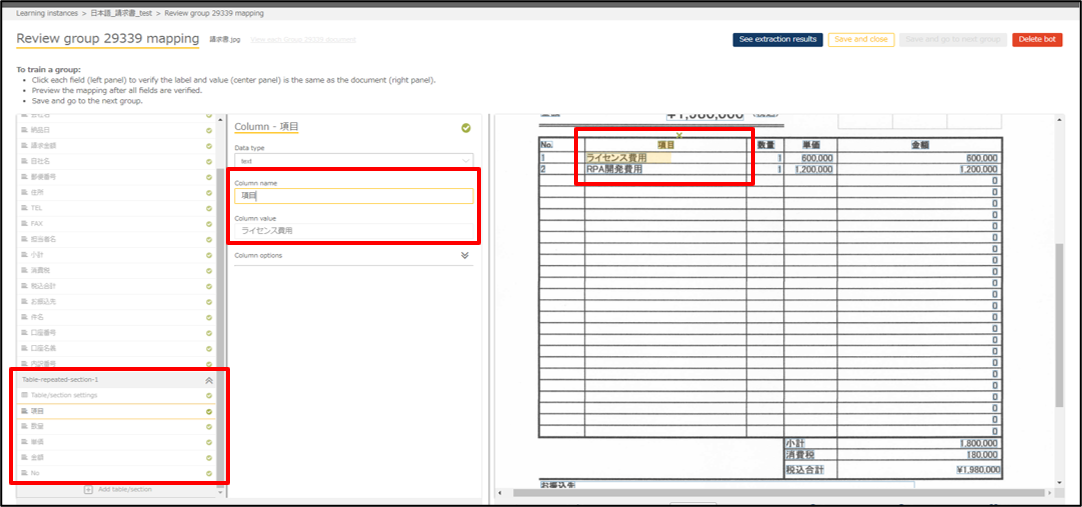
テーブルに対応する行ごとに値が取得できました。
また、最初の列の値のみ設定しただけですが、自動でテーブルの範囲を取得していることがわかります。
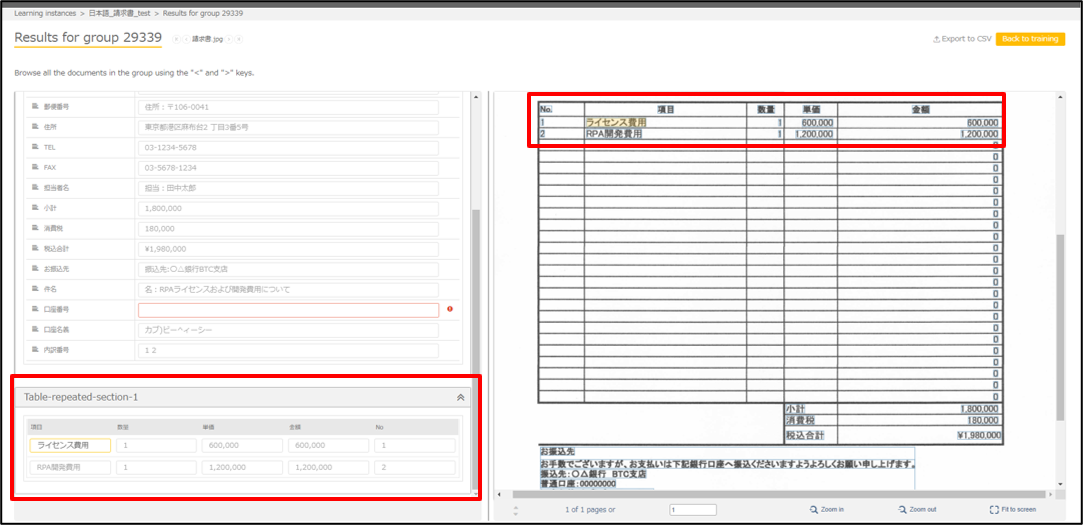
ここでテーブル設定の注意ですが、テーブル項目名がない帳票には標準で対応していないため、 少し工夫した対応が必要になります。
全ての項目の設定が完了したらSave and closeを押下してインスタンスを保存します。
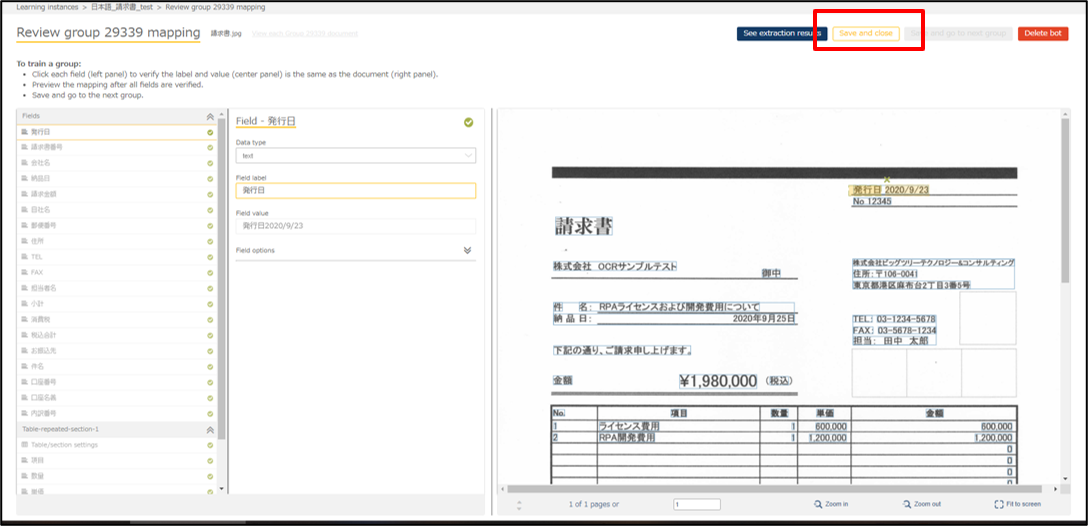
保存が完了すると以下の画面になるので、Set to staging をオンにします。

では、今作成したインスタンスにRPAから帳票を取り込み、結果を出力してみましょう。
Automation AnywhereのControl Roomにて、Botを新規作成します。
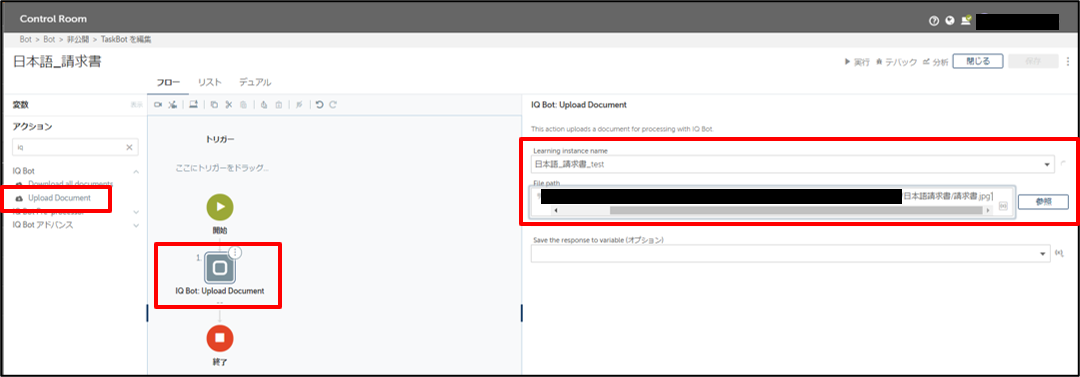
BotにIQ BotのUpload Document というアクティビティを追加します。
ここでは先ほど作成したinstanceを選択し、読み込ませたいファイルパスを指定します。
(以下の画像ではファイルパスをマスキングしています)
続いてIQ BotのDownload all documents というアクティビティをその後ろに追加し、 IQ Botで読み取った結果を出力します。
ここでもインスタンスとファイルパスを選択し、さらにIQ Bot document statusを選択します。
これはSuccess、Invalid、UnClassified、Untrainedの4種類から選択でき、 それぞれに対応するステータスの結果が出力されます。今回はSuccess Statusを選択して結果を確認します。
保存⇒実行を押下してロボットを実行してみましょう。
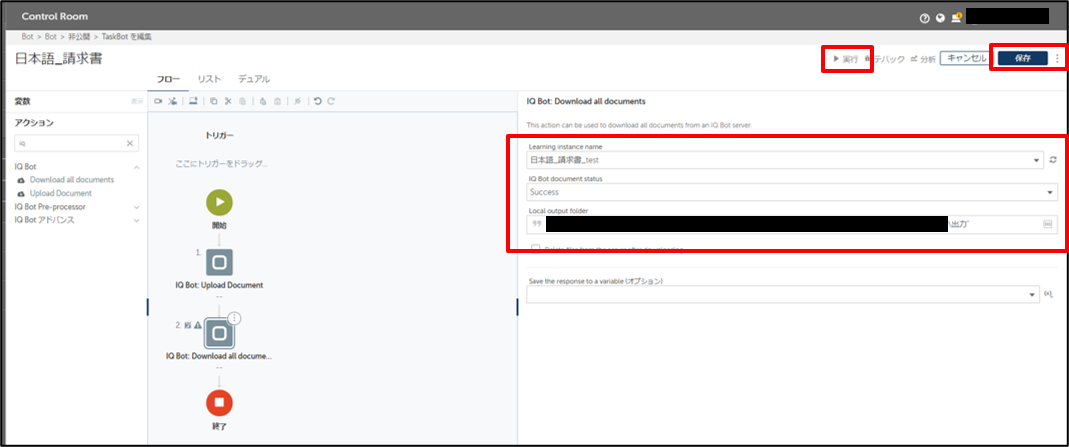
実行が完了しました。指定した出力フォルダを見てみましょう。
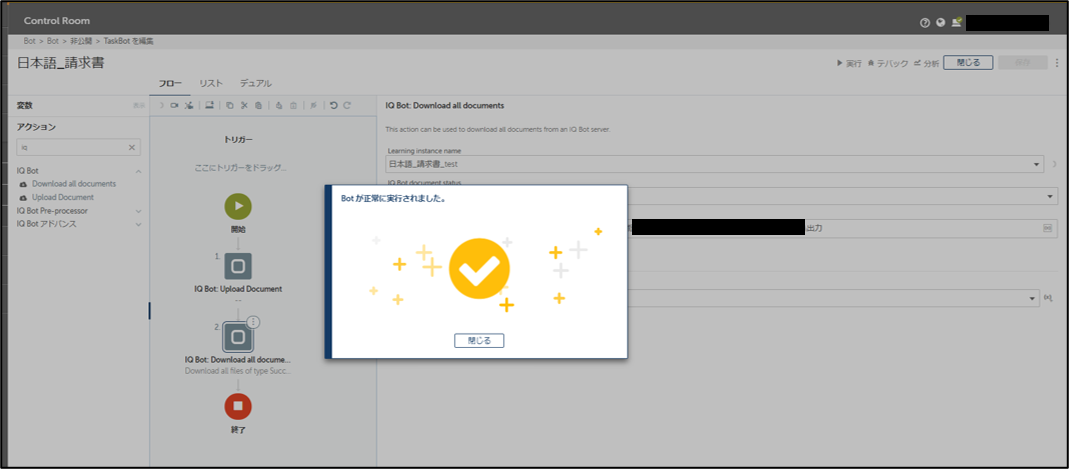
出力フォルダにはcsv形式で結果が出力されています。
ファイルを開いてみると、このようにテーブルの行分値が出力されていることがわかります。

OCRエンジンごとの精度比較
では実際に3つのOCRで英語活字、英語手書き、日本語活字、日本語手書きの検証を行っていきます。
英語活字文書
まずは英語の活字文書の請求書で比較をします。以下の帳票を読み取りました。

項目はInvoiceDate からTOTALまで全部で26個。 それぞれが正確に読み取れているかを判定し、読取成功数から精度を計算します。

結果はどの帳票も全て100%読取成功しました!やはり英語の活字には強いようです。
日本語活字文書
続いて日本語の活字の請求書を見てみましょう。項目は全部で28個です。

結果は以下のようになりました。

ABBYYとGoogleでは日本語の活字もほとんど読み取れていましたが、 読み取れていない部分がいくつかありました。

ABBYYでは口座名義が以下のように読み取られていました。
正 : カブ)ビーティ―シー
誤 : カブ)ビー^ィーシー
また、Googleでは振込先が以下で読み取られてしまいました。
正 : 〇△銀行BTC支店
誤 : 0 △銀行 BTC支店
日本語活字対応はしていますが、未サポートであるMicrosoft Computer Visionについては 他の2つと比べると精度が落ちています。
振込先についてはGoogleと同じ間違いでしたが、 その他よく見られた間違いは郵便番号、TEL、FAXにおいて「-」が抜けていることでした。
また、自社名も以下のように間違えていたことから、横線に弱いのではないかと推測されます。
自社名
正 : 株式会社 ビッグツリーテクノロジー & コンサルティング
誤 : 株式会社 ビッグッリテクノロジ & コンサルティング
英語手書き文書
次は英語の手書きの帳票です。文字数はLetterは182文字、Alphabetは52文字です。

結果は以下のようになりました。
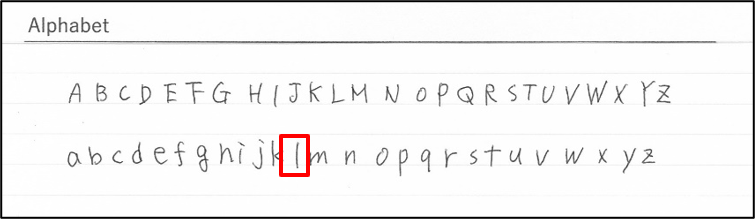
Microsoft Computer VisionはLetterで1文字間違い、Google VisionはAlphabetで1文字間違いという接戦です。


Microsoft Computer VisionがLetterでは 上の図の「.」(ピリオド)が「,」(カンマ)と読み込まれてしまっていました。
細かすぎる!というツッコミが入るかもしれませんが、Google Visionでは正確に読み取れていたので驚きです。
反対にGoogle VisionがAlphabetで間違えていたのは小文字の「l」(エル)です。
「/」(スラッシュ)と読み取られていました。
日本語手書き文書
そして最後は日本語の手書きです。
こちらは対応しているエンジンがGoogle Visionだけですが、確認してみましょう。
文字は全部で95文字です。

結果は以下のようになりました。

こちらは実際に読み取った内容を見てみましょう。
正
鈴木様:今回はご注文(#12345)ありがとうございます。 請求書を添付書類として送付します。 私たちのサービスをお選びいただき、ありがとうございます。 今後ともよろしくお願いいたします。田中太郎
誤
会木様' 今回すご注文 (#(2345) ありがとうございます。 請主書を添付書類として送付します。 私たちのサービスをお選びいただき、ありがとう!”さいます。 今後ともよろしくお腹いいたします。田中太郎
主に漢字の部分を誤って読み取っていることが分かります。
まとめ
今回精度比較をした3つのOCRエンジンと、帳票4種類の結果を以下の表にまとめました。
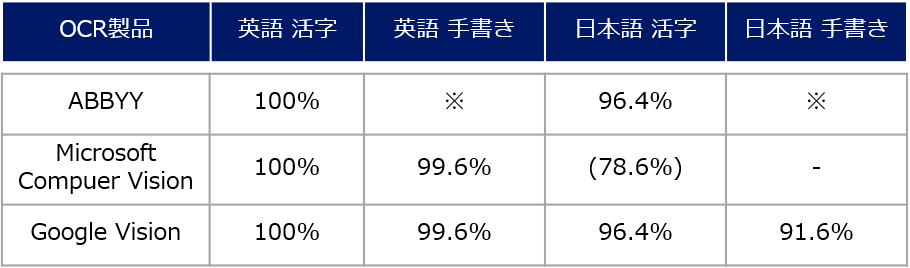
どのエンジンにおいても英語の活字では間違えることはほとんど見られず、 日本語の活字にしても対応している2つのエンジンは100%に近い成功率でした。
また、手書き文字に対しても英語の場合はほとんど正確に読み取ることができ、 認識が誤っていた箇所はピリオドとカンマの違いや、小文字のLとスラッシュなどの判別が難しいと思われる部分でした。
日本語の手書きでは、漢字において認識の誤りが多少みられましたが、読取成功率で言えば90%を越えています。
今後新しいOCRが提供されることになっていますが、検証してみてGoogleVisionでも利用可能であることがわかりました。
表内の※であるABBYYの手書き文字については、検証はしてみたもののほとんど読み取れませんでした…
OCRエンジンごとの精度比較は以上の結果になりましたが、 実際に業務で使用する際はひとつのエンジンを使うというだけではなく、 1帳票に対して複数OCRでの検証を行い、精度を上げることで人の確認箇所を減らすことも可能です。
今回の結果から、識字率が99.6%や96.4%であれば、人が確認する部分をかなり少なく抑えることができると思われます。

最後に
弊社でもOCRを活用して紙帳票の読み取りを自動化する案件も増えてきております。
みなさまの業務に大きな成果をもたらすIQBotを是非お試しください。
また、PoCの支援や導入についてご依頼や相談がありましたら、以下までご連絡をお願いいたします。
最新情報をお届けします!
RPAに関する最新コラムやイベント情報をメールで配信中です。
RPA領域でお仕事されている方に役立つナレッジになりますので、ぜび登録してください!









- July 2024 (1)
- June 2024 (2)
- May 2024 (3)
- April 2024 (1)
- March 2024 (1)
- February 2024 (1)
- January 2024 (1)
- December 2023 (1)
- November 2023 (2)
- October 2023 (3)
- September 2023 (1)
- August 2023 (4)