手軽に使えるOCRサービス「Amazon Textract」を使ってみた
-
TAG
-
UPDATE
2019/09/25
Amazon Textractとは?
Amazon Textract は、電子化したドキュメントからテキストとデータを自動抽出するサービスです。何百万ものドキュメントでトレーニングされた機械学習モデルによって、高い認識精度を実現しています。ただ、2019年9月24日時点では対応言語は英語のみで日本語の抽出ができないのが残念です。
本サービスの利用にはアマゾン ウェブ サービス(AWS)のアカウントの取得(無料)が必要で、マネージメントコンソールもしくはAPIから利用できます。料金体系は読み込みページ数に比例した従量課金制で一定期間の無料利用枠があります。
Amazon Textract の料金:
https://aws.amazon.com/jp/textract/pricing/
従来のOCRとの違い
1.事前設定が不要
Amazon Textractは、一般的なOCR製品で必要とされるドキュメント毎の事前設定(項目定義や座標設定等)が不要です。
それによりすべてのドキュメントのコードの維持管理やフォーマット変更への対応が不要になるなど、開発・運用面でのメリットが享受できます。
2.構造化データの抽出が可能
一般的なOCR製品では事前に定義した項目にOCRしたデータをセットします。また注文明細のようなレコード数が不定のデータに未対応のものが多いですが、Amazon Textractはドキュメントの構造を解釈し、構造含めデータ化できます。
例えば、単一項目であればラベル名と入力値をkey-value ペアで、表形式の項目であればヘッダ含め表形式が維持されて出力されます。
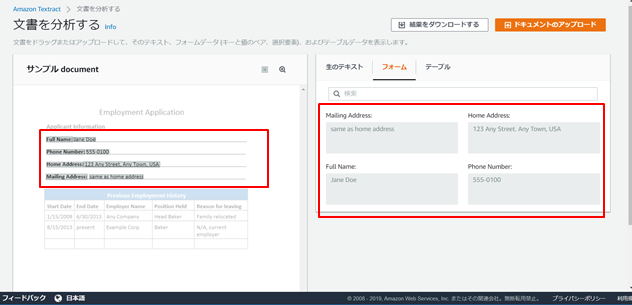
<出力結果イメージ1>
※左が読み込んだドキュメント、右がOCR結果
※『フォーム』では、ラベル名と入力値がkey-value ペアで出力される
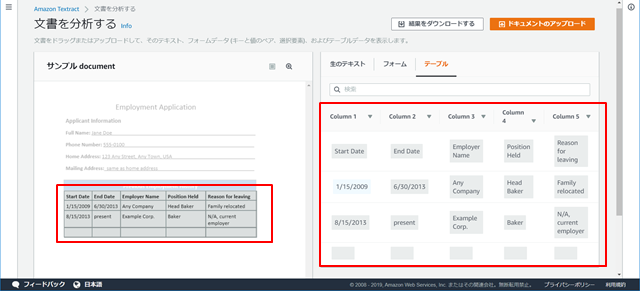
<出力結果イメージ2>
※『テーブル』では、ヘッダ含め表形式が維持され出力される
実際に使ってみた
下の請求書で検証してみましょう。
請求明細(Details)の項目と金額が対応した一覧データが取得できれば理想的ですね。
請求書のように明細行数が都度変動するドキュメントは、一般的なOCR製品では対応できなかったり、対応できたとしても複雑な設定が必要になります。
Amazon Textractではうまく取得できるでしょうか?早速試してみましょう。

1.準備
前述した通り、Amazon Textractはドキュメント毎の事前設定が不要なため、AWSアカウントとデータ(pdf,png,jpg)さえあればすぐにOCRすることができます。
2.実施
今回はマネージメントコンソールから実施します。
AWSアカウントにサインインし、Amazon Textractからファイルをアップロードします。
アップロード後10秒程度で処理が完了しました。
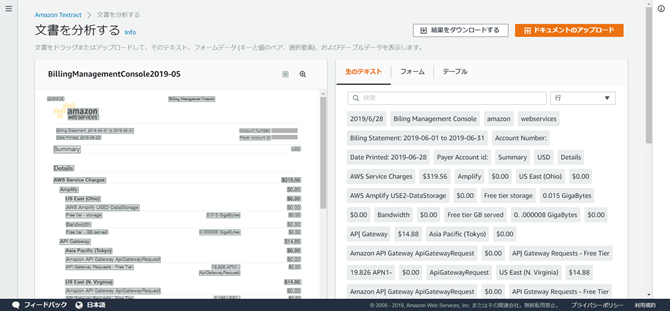
3.検証
結果を検証してみましょう。
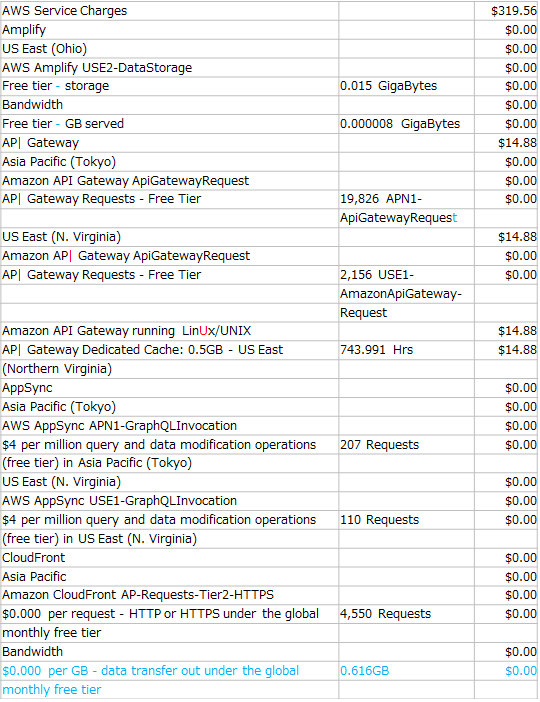
OCR結果『テーブル』をCSV形式でダウンロードし誤読や認識漏れを確認します。
赤字が誤読、青字が認識できなかった箇所になります。
今回のドキュメントにおける認識率は約92%(*)で、これは他のOCR製品と比較しても見劣りしない結果です。
※認識率=正しく読み取れた文字数÷元データの全文字数
まとめ
事前設定不要ながら認識精度は実用可能なレベルであることがわかりました。
当然ですがレイアウトや画質によって認識精度は変わるため、導入にあたってはきちんと事前検証を行う必要があります。
さいごに
BTCではRPA、OCRをはじめとする様々な技術を取り入れながら、市場のニーズに応えていきます。
導入実績も多数ございますので、「導入を検討しているがどこから手を付ければよいかわからない」、「導入したものの期待した効果が得られていない」などお困りのことがございましたらお問い合わせください。
参考
・Amazon Textract
https://aws.amazon.com/jp/textract/
最新情報をお届けします!
RPAに関する最新コラムやイベント情報をメールで配信中です。
RPA領域でお仕事されている方に役立つナレッジになりますので、ぜび登録してください!









- September 2024 (2)
- August 2024 (4)
- July 2024 (1)
- June 2024 (2)
- May 2024 (3)
- April 2024 (1)
- March 2024 (1)
- February 2024 (1)
- January 2024 (1)
- December 2023 (1)
- November 2023 (2)
- October 2023 (3)