【Power Platform】データフローを利用したDataverseへのデータ投入
目次
1.はじめに
みなさん、こんにちは。
今回はMicrosoftのローコードプラットフォーム製品群「Microsoft Power Platform(以降、Power Platform)」の
「Power Apps」で作成したアプリからも参照するデータベース製品「Microsoft Dataverse(以降、Dataverse)」にスポットを当て、
「Dataverse」へのデータ投入はSQLの知識がない人でもローコードで可能?についてコラムを書きました!
「Power Apps」で作成できるアプリは「キャンバスアプリ」と「モデル駆動型アプリ」の2種類に分かれ、
「Dataverse」にはデータ準備を容易にしてくれる「データフロー」という機能が用意されています。詳しくはリンク先のページをご参照ください。
1.1 キャンバスアプリ
キャンバスに絵を描くようにテキストボックスやボタンを配置が行えるなど自由度の高いアプリが作成できます。
Oracle、SQLServerといったデータベースを始め、多数のデータソースとの連携も可能です。もちろん同じPlatformのDataverseとの連携も可能です。
1.2 モデル駆動型アプリ
使用可能なデータソースは「Dataverse」のみに限定されますが、あらかじめ整合性の取れたデータ管理ができているということを前提にできるので、
キャンバスアプリよりも簡単かつ迅速にアプリ作成が行えます。
製品側である程度の枠組みが準備されるので「キャンバスアプリ」よりも自由度は落ちますが、コーディング量もテスト量も抑えて簡略化できます。
1.3 データフロー
今回はデータフローを作成してDataverseにデータを投入する方法をご紹介します。データフローには具体的にはこちらの利点があると思います。
・他の製品とのコネクタが充実しており、他の製品や環境からの直接データインポートすることが可能。
・データの加工方法を最初に定義すればその後は何度でも同じ手順でデータ加工をしてくれる。
・エクセルやCSVといったファイル形式のデータソースを利用する場合、ファイル数が増えても追加作業無しでデータ取込が可能。
・日次、週次、日に複数回の定時実行など、柔軟なスケジュール実行が可能。
エクセルファイルから手動でデータインポートする方法もありますが、利点として記載した作業を人手で行うことになり効率が良いとは言えません。
データフローを使いこなすことができればDataverseでのデータ管理が効率的になり、実際の運用でもテストでも大いに役立つと思います。
2.サンプルのモデル駆動型アプリのご紹介
当コラムでは「データフローを用いてSharePointに格納された売上データをDataverseのテーブルへ投入してモデル駆動型アプリで参照する。」
という業務のイメージで話を進めさせていただきます。なお、モデル駆動型アプリの作成方法は今回のコラムでは省略します。
弊社の開催したセミナー動画があるので良かったらご参照ください。
セミナー動画:https://youtu.be/dvpdHq3ub0k
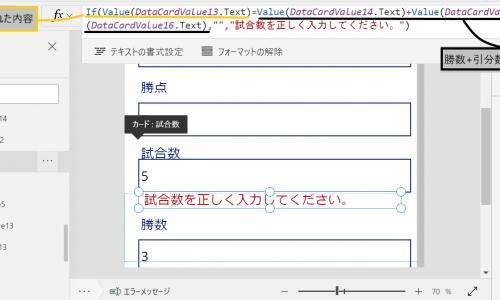
用意したサンプルアプリのイメージはこちらです。ヘアサロンでアプリ開発してみたらということをイメージしています。
データフローを作成して施術売上のデータを外部から投入します。
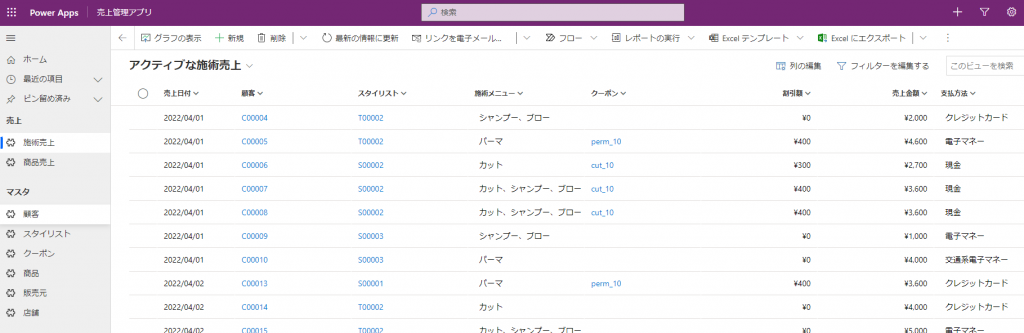
画像の列のうち「顧客」、「スタイリスト」、「クーポン」は他のテーブルで一意に管理された値を引っ張ってくる検索型(リレーション)、
「施術メニュー」、「支払方法」は選択肢型という点が特徴で、テキスト型や整数型のようなベーシックな型もデータの投入ができるか確認しました。
Dataverseのデータ型についての詳細はこちら。Microsoft Dataverse の列データ型 (ビデオを含む) - Power Apps | Microsoft Docs
3.実際にデータフローを作成してみる
データフローは以下の流れで作成します。
1.データソースの読み込み
2.Power Queryでデータ加工
3.読み込み先のテーブルとマッピング、発行
4.スケジュール実行
事前にSharePointに配置した取込データはこちらの「施術売上」シートで、1行目が不要、I列以降が不要、B列とC列の値は加工が必要な状態としています。
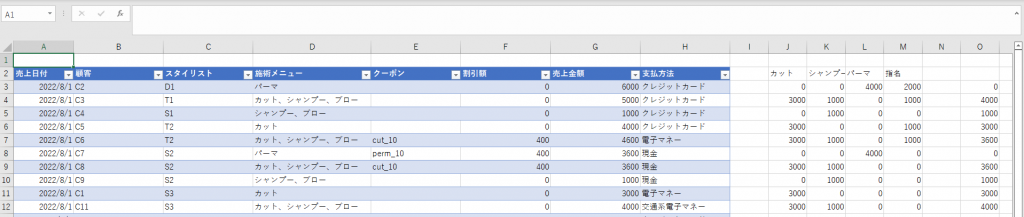
なお、唐突に出てきた「Power Query」の詳細はこちら。Power Query とは - Power Query | Microsoft Docs
ここから少し長いですが、最後まで読んでいただきお役に立てれば幸いです!
3.1 データソースの読み込み
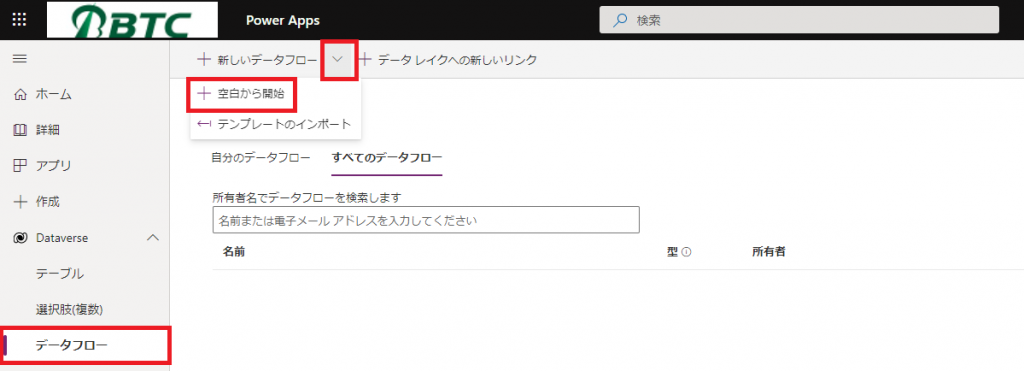
①「Power Apps」のページを開き、「Dataverse」⇒「データフロー」⇒「新しいデータフロー」⇒「空白から開始」の順に選択します。
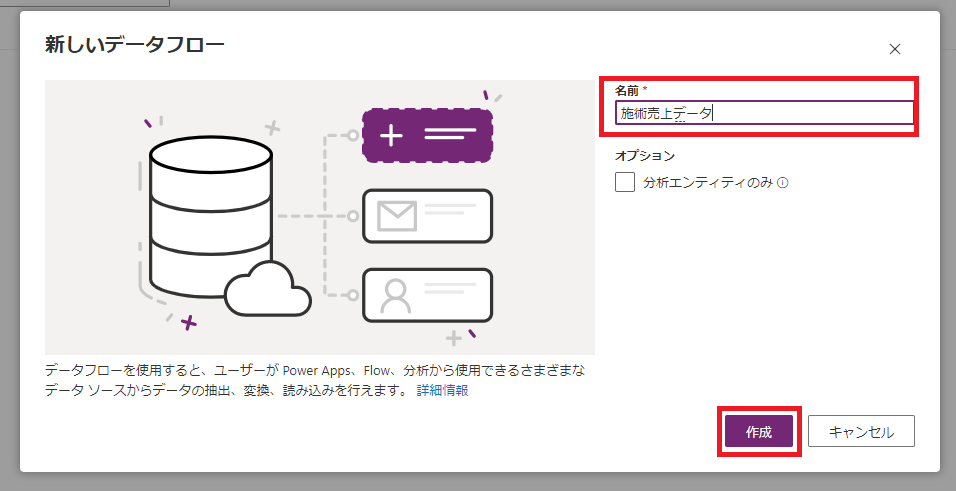
②データフローの名称を入力して「作成」ボタンを押下します。
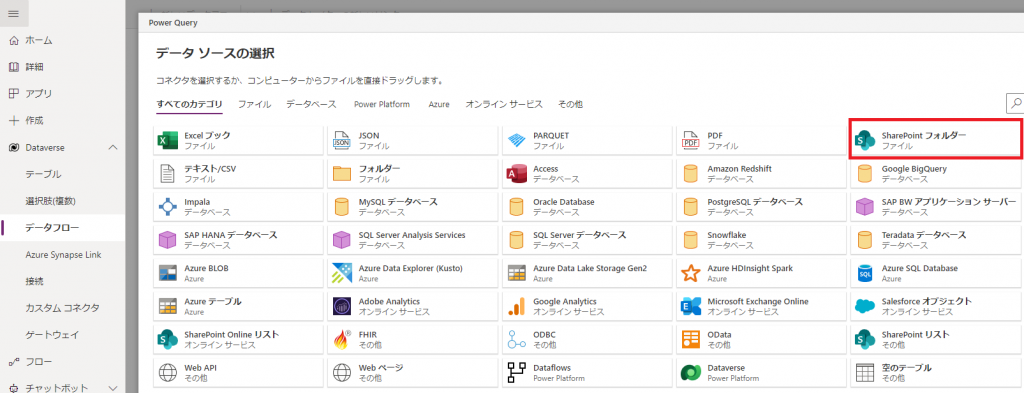
③データソースの選択画面には多くのコネクタが準備されており、様々なデータソースからデータの取込が可能です。
今回はSharePoint OnlineにExcelファイルを配置しているので「SharePointフォルダー」を選択します。
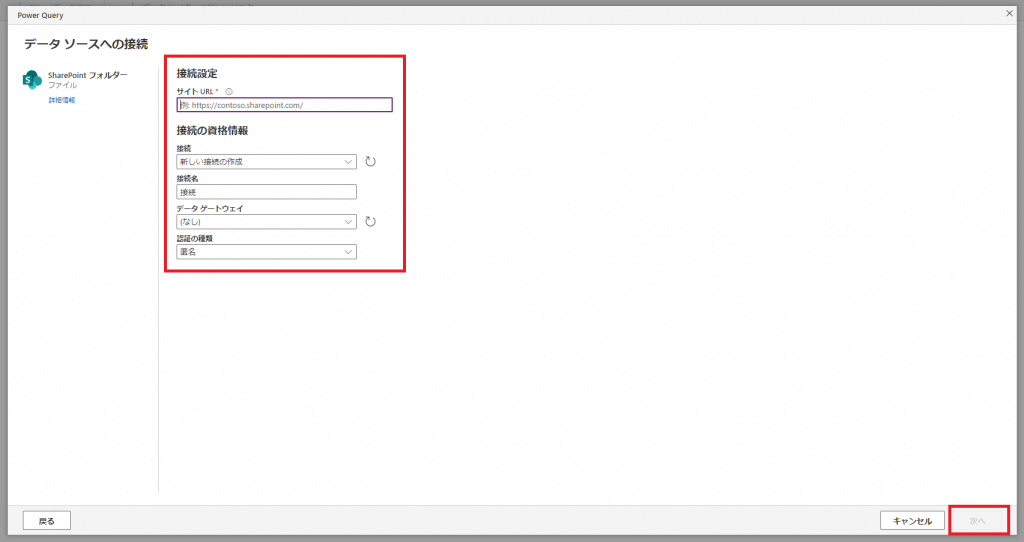
④SharePoint OnlineのサイトのトップページのURLなどの必要な情報を入力して「次へ」を押下します。
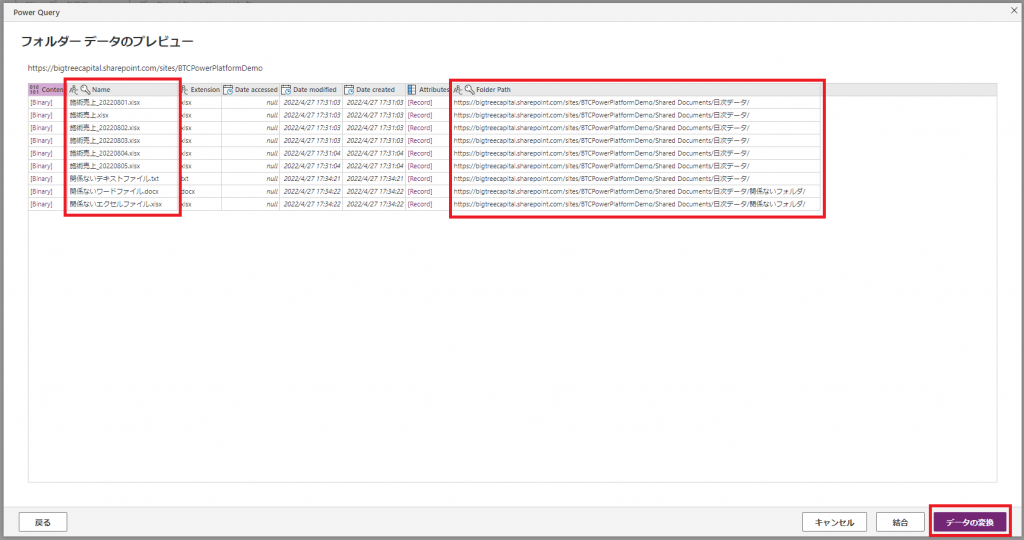
⑤SharePoint上の全てのファイルが一覧形式で読み込まれます。今回は初回データと2022/8/1~8/5のデータを読み込むというシナリオです。
表示内容に問題なければ「データの変換」ボタンを押下します。 ※読み込みを行うファイルは全て同じフォーマットにしておく必要があります。
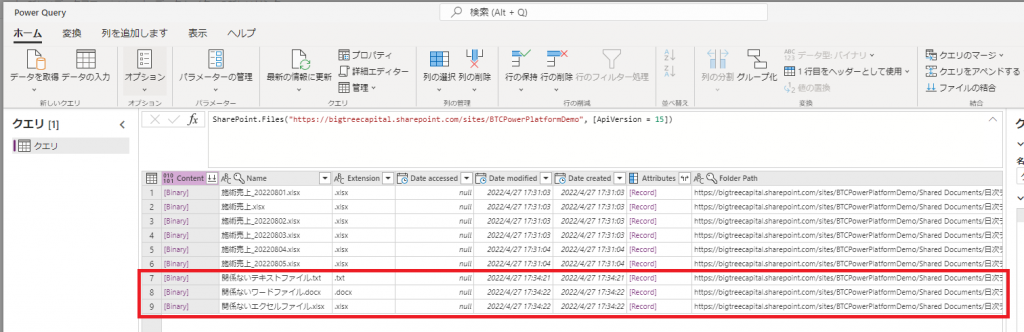
⑥Power Queryの画面が開いたらPower Queryでデータ加工を行います。まずは赤枠部分の無関係なレコードを消すところからスタートです。
3.2 Power Queryでデータ加工
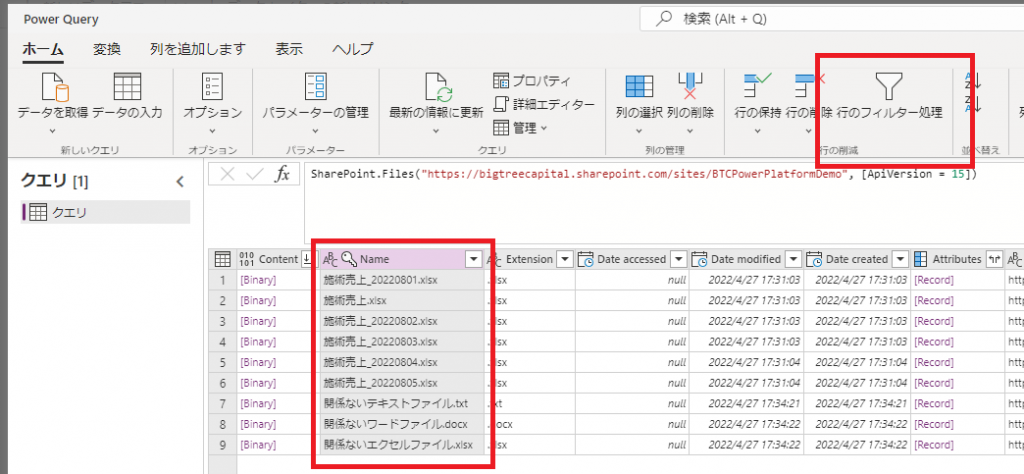
①不要なファイルの行を削除したいのでフィルタリングする列を選択して「行のフィルター処理」を押下します。
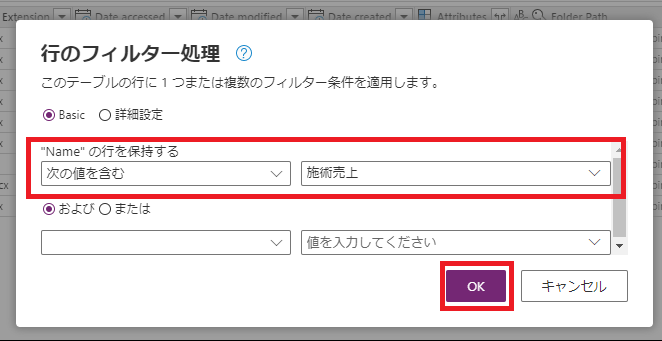
②フィルターの内容を指定して「OK」ボタンを押下します。
このように様々なデータ加工をGUIで行えるのでコーディング未経験でも代表的な加工手順を覚えれば簡単にデータの加工が行えます。
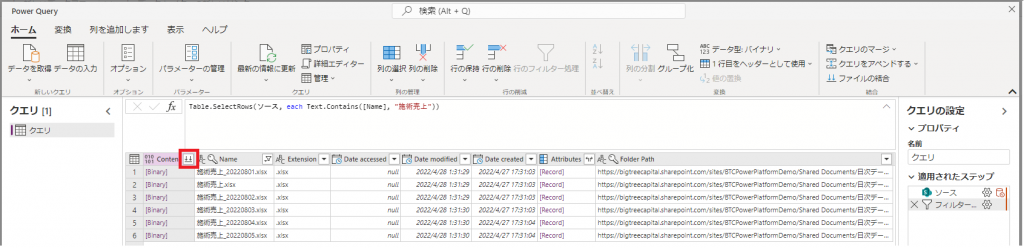
③フィルターの結果が画面に反映され、対象ファイルの絞り込みが行えました。
次はテーブル左端の「Content」カラムの右横のボタンを押下してファイルを展開します。こちらのカラムにファイルのデータが入っています。
④「Content」を展開すると「ファイルの結合」ウインドウが開きますので、読み込み対象のシートを選択して「OK」ボタンを押下します。
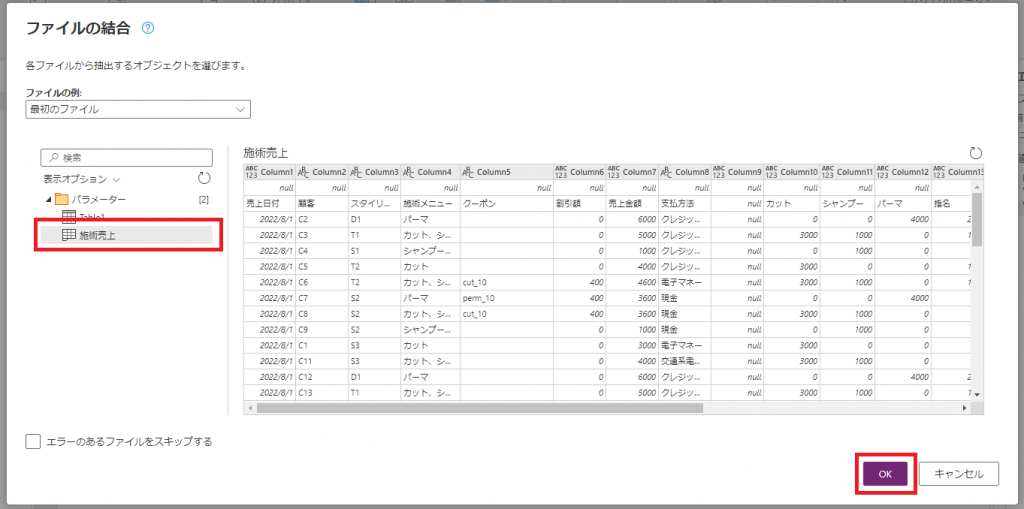
対象ファイルが全て展開されてテーブルに格納されました。
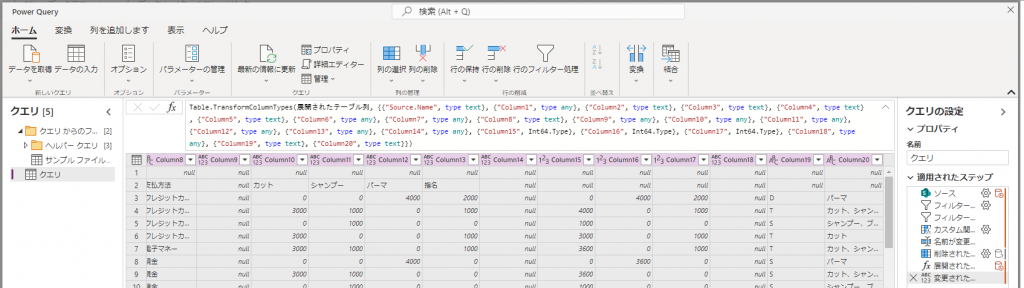
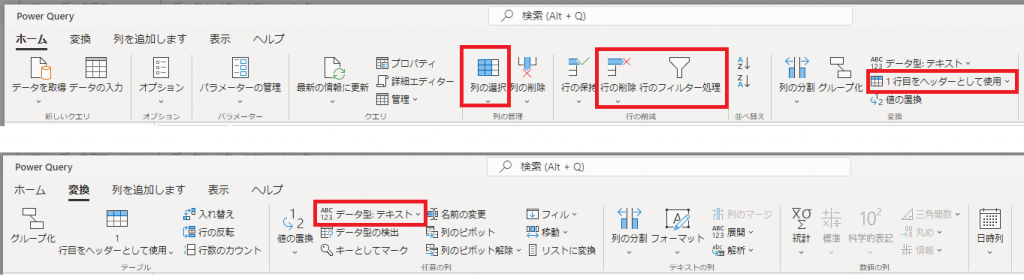
⑤同様にメニューの各アイコンで以下の操作を実施します。 ※GUIで直観的に操作できるため詳細は省略。
・先頭の空白行を削除
・Column2~Column8以外の列を削除
・1行目の値をヘッダーにする
・不要な空白行およびタイトル行を削除
・売上日付の型を文字列⇒日付に変換
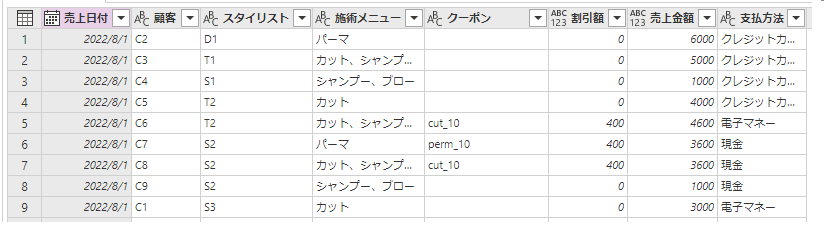
こちらがデータ加工後の状態です。
⑥「顧客」「スタイリスト」列を変換するために以下の操作を実施します。
・対象の列を文字列値(顧客.1)と数値(顧客.2)に分割
・分割した数値(顧客.2)を前ゼロ埋めの5桁へ変換し、文字列値(顧客.1)と結合した値を新しい列(顧客)として追加
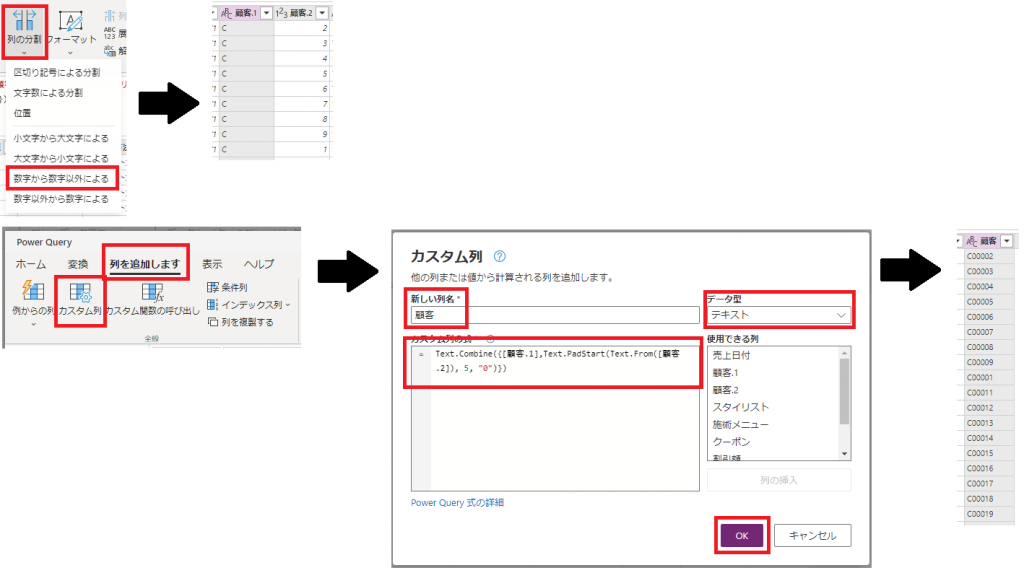
カスタム列の追加には「Power Query M関数」の知識が必要になります。Excel関数に慣れている方は内容の理解も早いと思います。
Power Query M関数についての詳細はこちら。Power Query M 関数参照 - PowerQuery M | Microsoft Docs
今回のカスタム列の作成で使用した数式ですが、実行される内側から説明すると以下の流れになります。
・Text.From([顧客.2]) : 顧客.2を数値型から文字列型へ変換
・Text.PadStart(Text.From([顧客.2]), 5, "0") : 文字列型へ変換した顧客.2を前ゼロ埋めの5桁に変換
・Text.Combine({[顧客.1],Text.PadStart(Text.From([顧客.2]), 5, "0")}) : 顧客.1と前ゼロ埋めした顧客.2を結合
同様に「スタイリスト」列も編集して不要な列を「列の選択」で削除し、右下の「次へ」ボタンを押下します。
【Dataverse、各データ型、モデル駆動型アプリの知識をお持ちの方に向けたお話】
・検索型フィールドのマッピング
編集した「顧客」「スタイリスト」は後ほど検索型の列にマッピングします。検索型のフィールドに実際に入る値は16進数のGUIDですが、
リレーション先のテーブルの「プライマリ名の列」の値にすればPower Platform側で自動的に解釈してリレーションを張ってくれます。
・選択肢型フィールドのマッピング
フィールドに入る実際の値は数値ですが、取込データの「施術メニュー」「支払方法」は編集無しの文字列値のままでOKです。
もちろん実際の数値でも問題無く取込が行えます。
・選択肢(複数)型フィールドの注意点
モデル駆動型アプリの画面上で複数の値をチェックして選択できる型ですが、データフローでは複数の文字列値(例:{"犬","猫"})での取込不可のため、
実際に格納される数値(例:{1230001, 1230002})への変換が必要です。
アプリ上では便利ですが外部からデータを取り込む場合は注意が必要です。
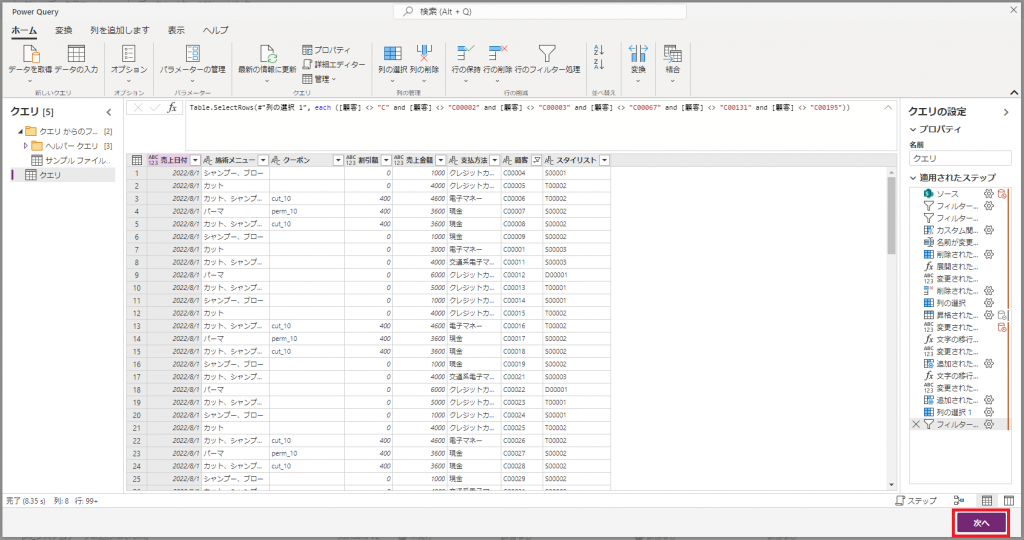
3.3 読み込み先のテーブルとマッピング、そして発行へ
①マッピング画面に遷移したら読み込み先のテーブルとのマッピングを編集します。
と、思ったら想定よりも表示されている列が少ないことに気づきました。読み込み先のテーブルから別テーブルのリレーションを表す参照列が出ていませんでした。
②調べたところ、参照列をマッピング対象として表示させるには、お互いのテーブルにキーが必要ということでした。
お互いのテーブルにキーがなければ正確にリレーションは張れないということで、手が止まって困りましたが「よくできてるなぁー」と思いました。
詳細はこちら。標準データフローでのリレーションシップを持つフィールドのマッピング - Power Query | Microsoft Docs
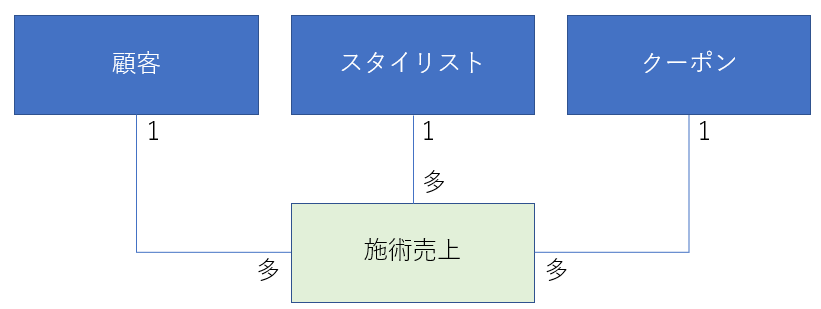
今回のデータフローで登場する施術売上と各マスタテーブルの関係がこちらです。
Dataverseのテーブルページで列定義の見え方はこちらです。
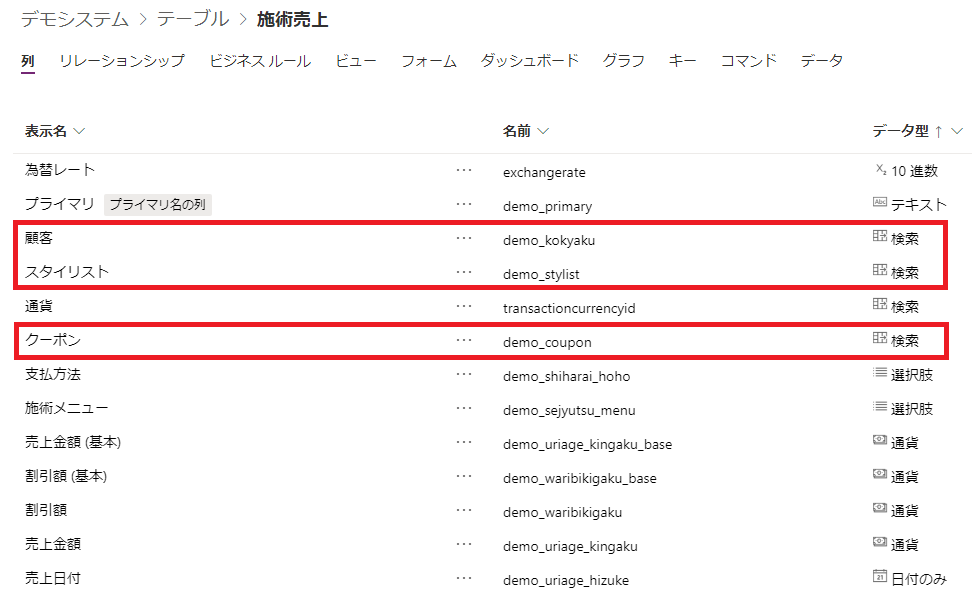
③各テーブルにキーを追加しました。一意になっていればいいので必ずしもキーに検索列の項目が入っている必要はありません。
キーの説明と作成方法の詳細はこちら。Power Apps ポータルを使用した代替キーを定義する - Power Apps | Microsoft Docs

④マッピング画面を再度確認すると検索列も表示されるようになりましたので、
Power Queryで準備した項目と読み込み先のテーブルとのマッピングを設定して「公開」ボタンを押下します。
実行するのは別のタイミングという場合は「公開」ボタンの右横から「後で発行する」という選択も可能です。
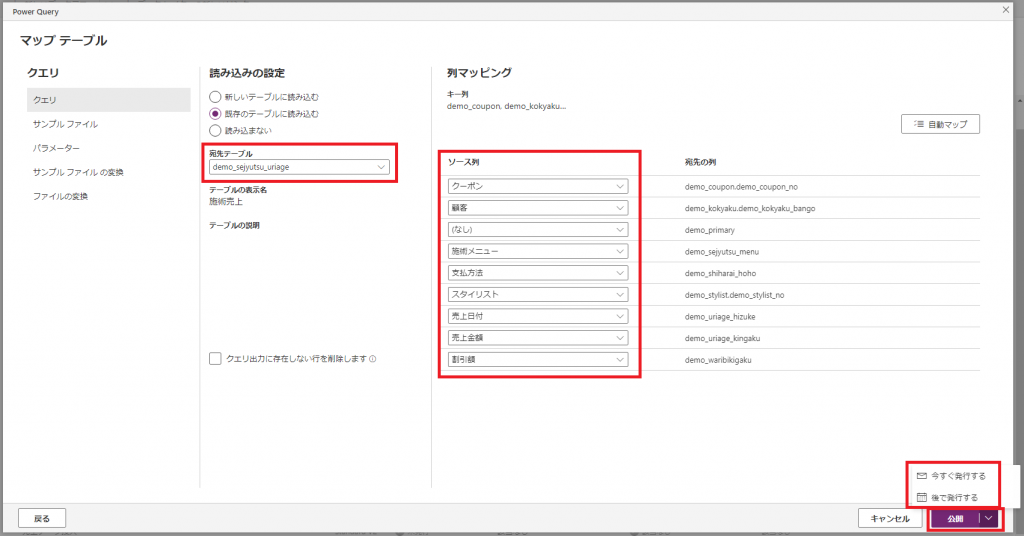
なお、今回はチェックを入れていない「クエリ出力に存在しない行を削除します」にチェックを入れると、
Power Queryで加工したレコードと一致しないレコードをテーブルから削除してくれます。
「外部環境で管理している顧客情報が常に最新なので確実に一致させておきたい」といった場合に便利な機能だと思います。
⑤無事に成功するとこちらの画面のように下書き状態などが緑のチェックマークの表示となり、アプリから取り込んだデータを参照できました。
アプリ上では検索列の項目は青字のハイパーリンクになっていて、施術売上テーブルから各マスタテーブルとのリレーションも問題なく貼れています。
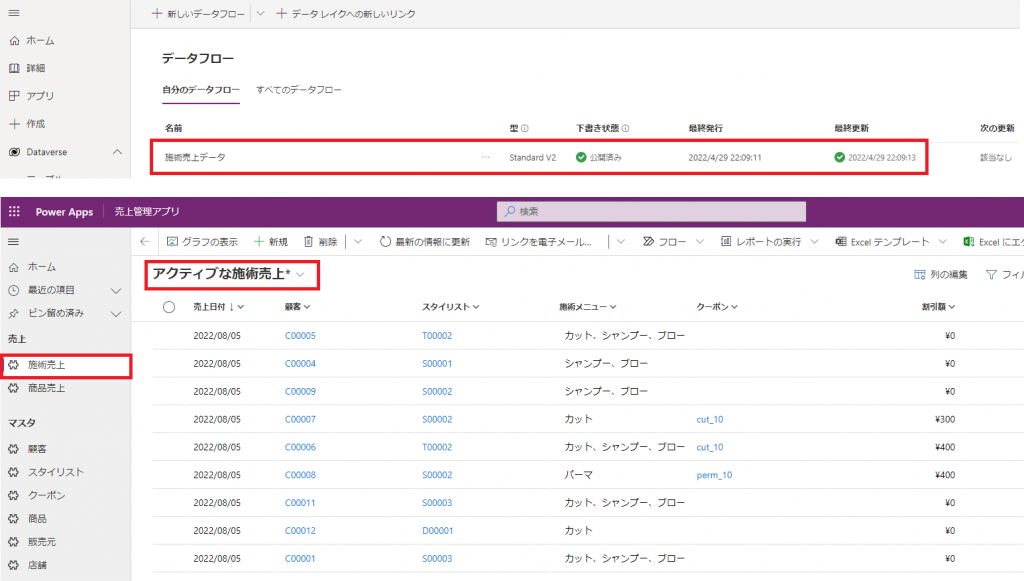
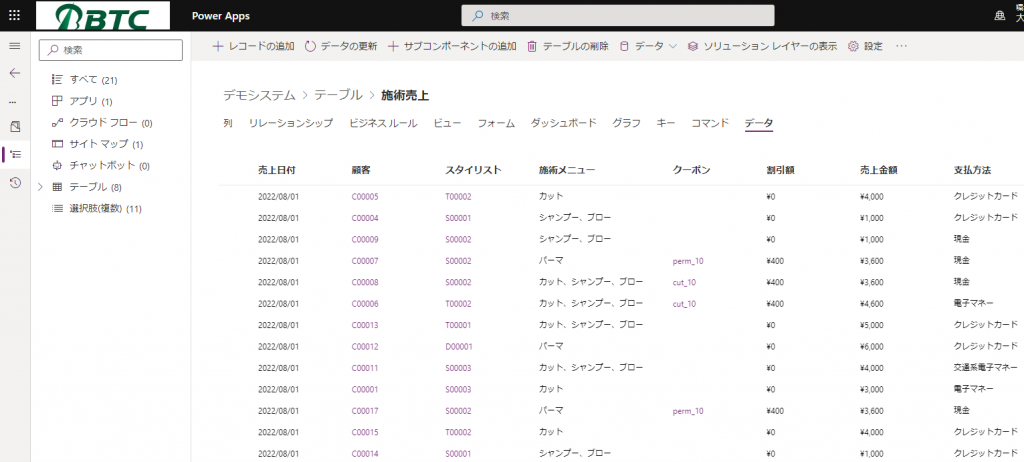
テーブルページのデータも同じような見た目になっています。
3.4 スケジュール実行
①データフローは日次や週次といった定期的なデータを取込するためにスケジュール実行の設定も可能です。
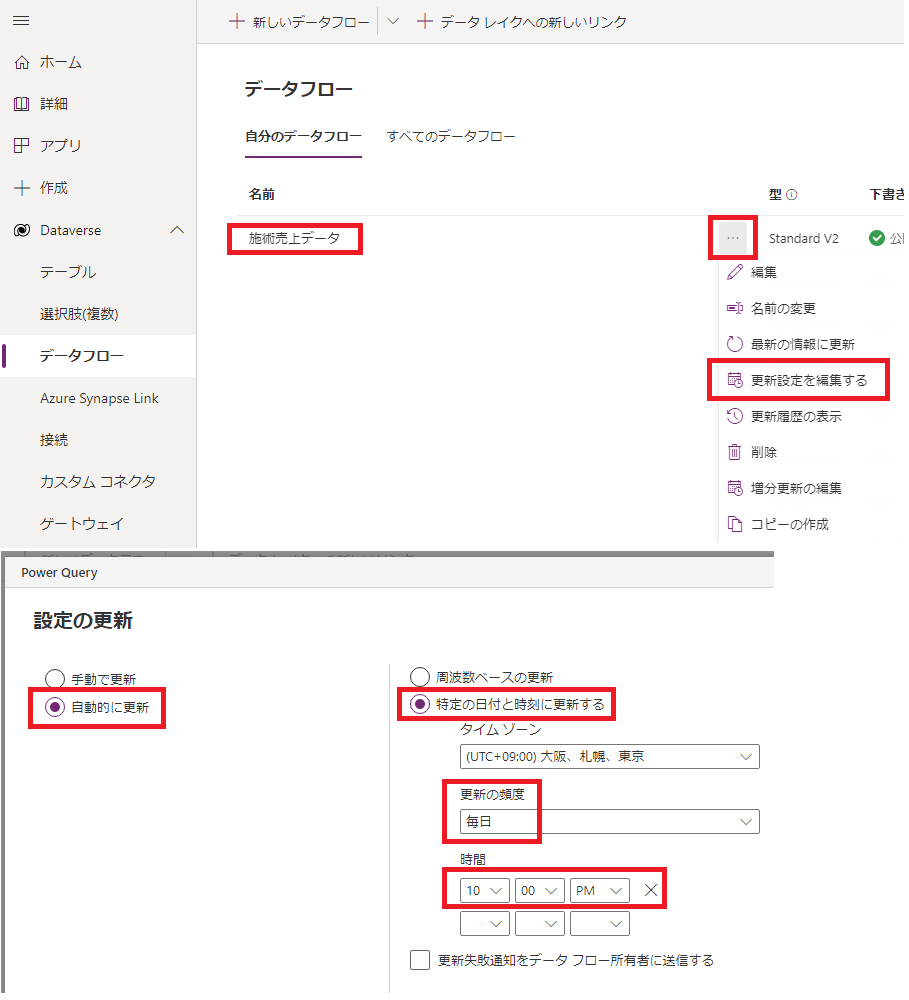
②保存して閉じると「次の更新」に次回の実行タイミングが表示されます。タイミングで自動処理してくれるのは非常に便利ですね。

4.まとめ
いかがでしたでしょうか?Dataverseへのデータ投入はSQLの知識不要のローコード開発で対応することができました。
このように「Power Platform」のどの製品も手順を覚えさえすれば、市民開発者でも迅速に高品質なシステムの開発が可能です。
これまでの「システム開発はエンジニアに全てお任せ!」という時代から、「システム開発はユーザー主導で推進、難しい部分だけエンジニアにお任せ!」
という時代になっていきそうですね。難しい部分のご相談は是非とも弊社にお問い合わせください!
またコラムを書く機会があれば、Dataverseに投入したデータをPower Platformのデータ分析ツールのPower BIで分析するというテーマで書きたいと思います。
Power BIは分析レポートの裏側のデータ加工はPower Queryを使っているので、データフローを触っておくと大いに役に立ちます。
弊社では今後も次々と機能拡充されていく「Power Platform」に引き続き注目していきます。
最新情報をお届けします!
RPAに関する最新コラムやイベント情報をメールで配信中です。
RPA領域でお仕事されている方に役立つナレッジになりますので、ぜび登録してください!









- November 2024 (2)
- October 2024 (3)
- September 2024 (2)
- August 2024 (4)
- July 2024 (1)
- June 2024 (2)
- May 2024 (3)
- April 2024 (1)
- March 2024 (1)
- February 2024 (1)
- January 2024 (1)
- December 2023 (1)