はじめに
みなさん、こんにちは!
昨今、RPAをすでに導入し、業務の自動化・効率化に成功している企業様も増えている状況で、さらなる自動化・効率化を推し進めるため、「自社もAI導入したい」という企業様が多くなっております。
ただ、AIについて調べてみるとすぐに分かるのが
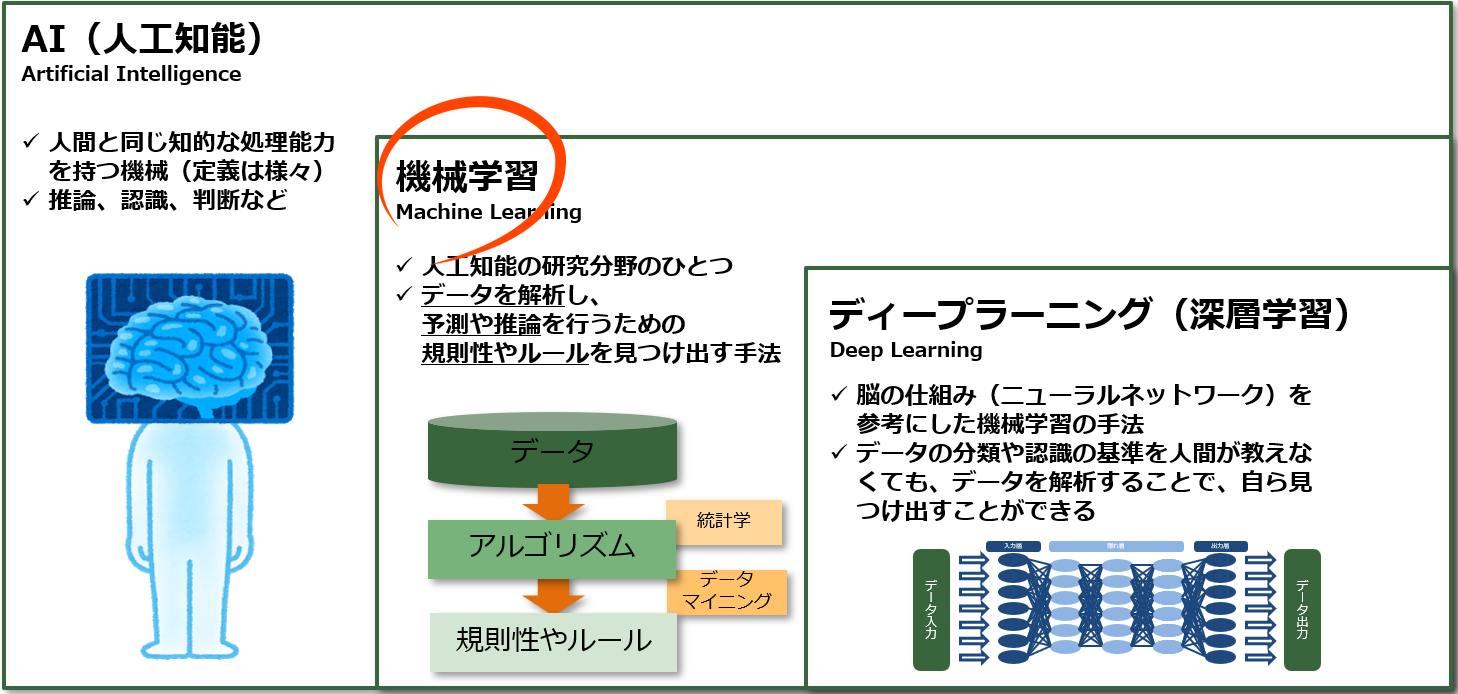
- AI(人工知能)は広義の概念で、機械学習とディープラーニングを内包している。
参考:ITソリューション塾 人工知能 研修資料

参考:ITソリューション塾 人工知能 研修資料
というところまでは理解しやすいところなのですが、そこから 具体的にどのような処理をして実現するのか、を理解するハードルがグッと高い印象を持っている人も多いのではないでしょうか。
そこで今回は、
- 機械学習の簡単な流れを理解する ところにフォーカスし、
簡単な事例を用いて、基本的な機械学習を実装する流れをソースコード付きで説明したいと思います。
住宅価格を予測してみる
今回は、「地域の住宅情報をもとに、住宅価格を予測する」という例で説明したいと思います。
そして、機械学習の中でも、正解のデータを与えて学習させる「教師あり学習」から、データの予測に使う線形回帰を利用します。
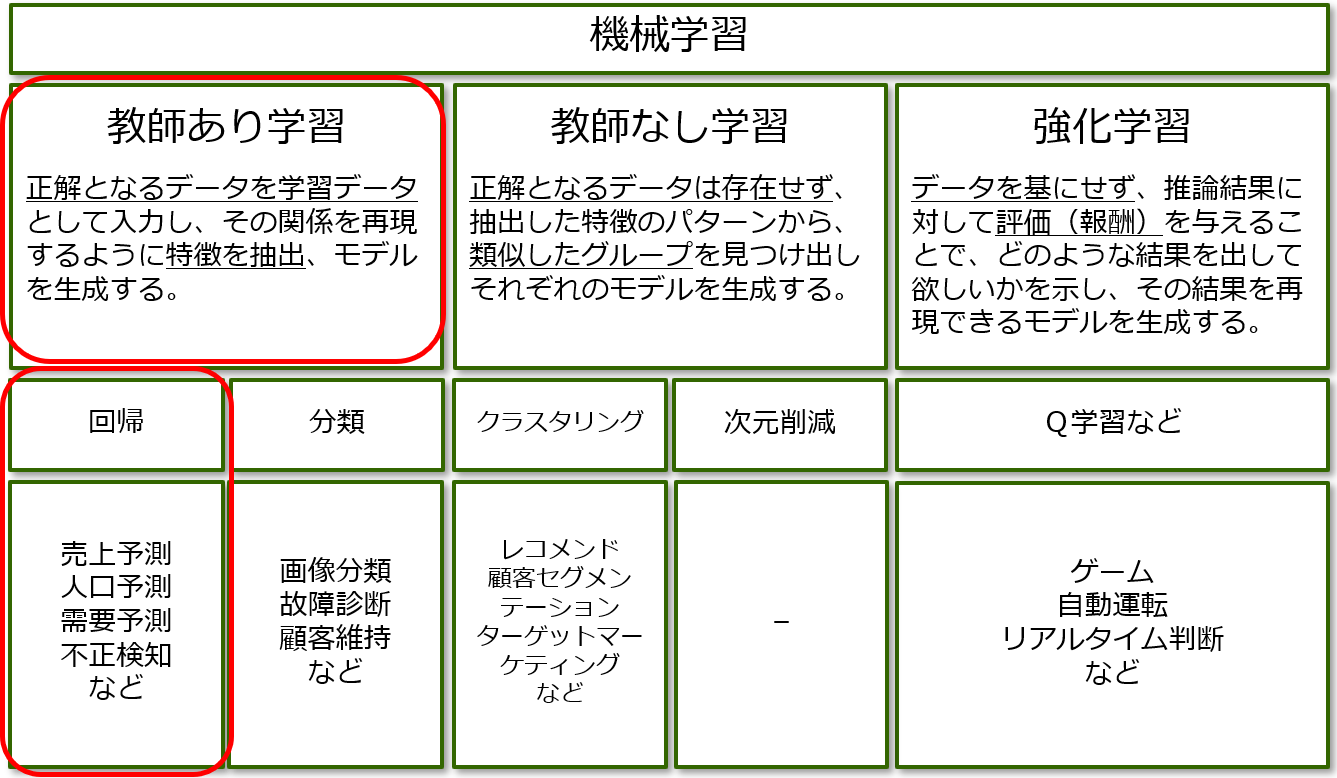
参考:ITソリューション塾 人工知能 研修資料
■補足コメント
とてもありがたいことに「回帰」「分類」「クラスタリング」「次元削減」それぞれのサンプルもあるので、本記事で理解を深めたあとに、参考に見てみるとおもしろいかと思います。
データ解析・予測の流れ(ざっくり)
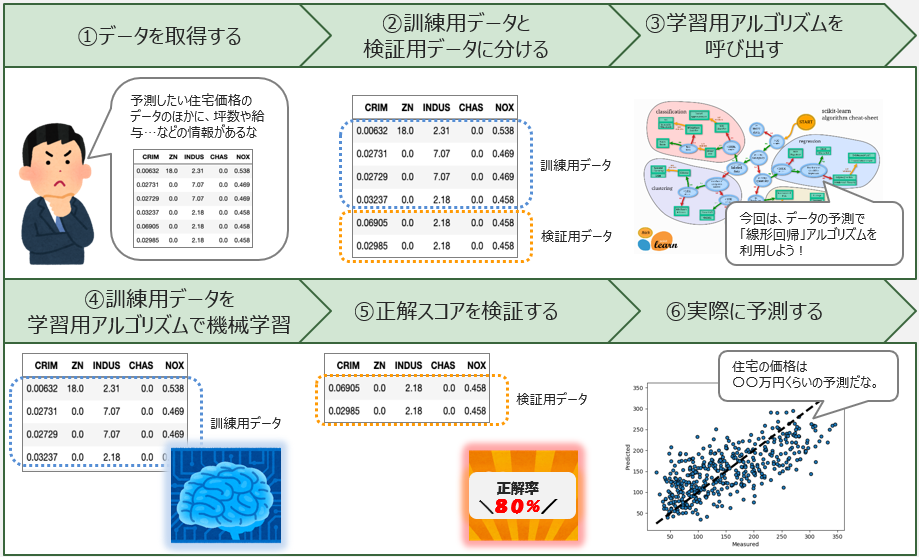
実装の流れは、大きく以下の6ステップです。
①データを取得する
②訓練用データと検証用データに分ける
③学習用アルゴリズムを呼び出す
④訓練用データを学習用アルゴリズムで機械学習
⑤正解スコアを検証する
⑥実際に予測する
これだけだと、あまりイメージがわかないですよね。
それぞれを、実際のソースコードと合わせてみていきたいと思います。
■補足コメント
プログラムを実行するツールとして、機械学習ではおなじみのJupyter Notebookを利用します。
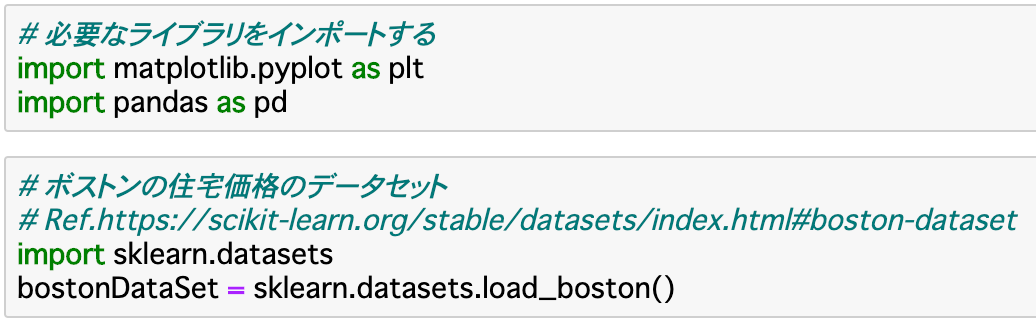
①データを取得する
今回は、サンプルデータとして利用することができる「ボストンの住宅情報」を取得して、変数(bostonDataSet)にセットします。
いったん、ボストン住宅情報データの中身の説明を確認すると、
- α.予測するためのデータ(地域の情報「住居の平均部屋数」「低所得者の割合」etc) と
- β.予測したいデータ「住宅価格」
で構成されていることが分かります。
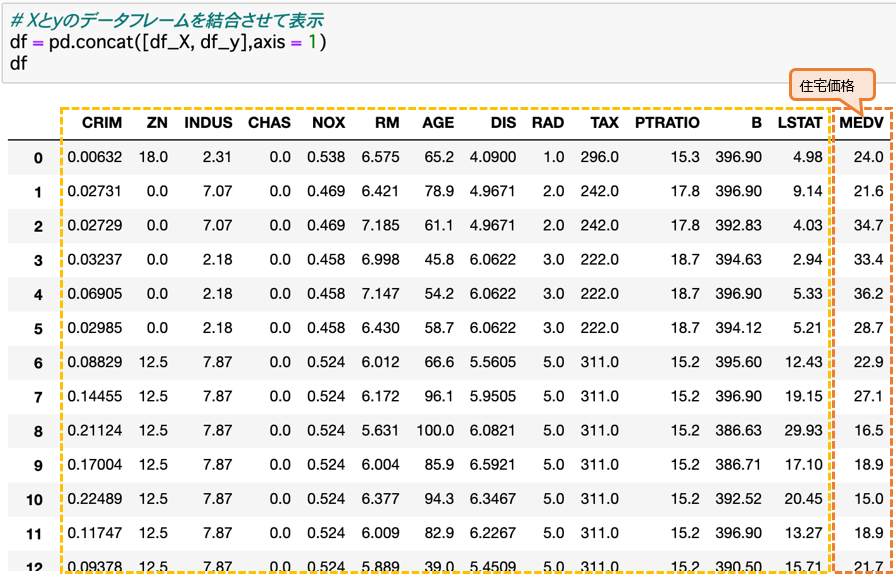
ここで、「α.予測するためのデータ」(地域の情報)を、X軸にセットします。
y軸には、「β.予測したいデータ」(住宅価格)をセットします。
「α.予測するためのデータ」(地域の情報)と、「β.予測したいデータ」(住宅価格)を結合させるとこのような状態です。
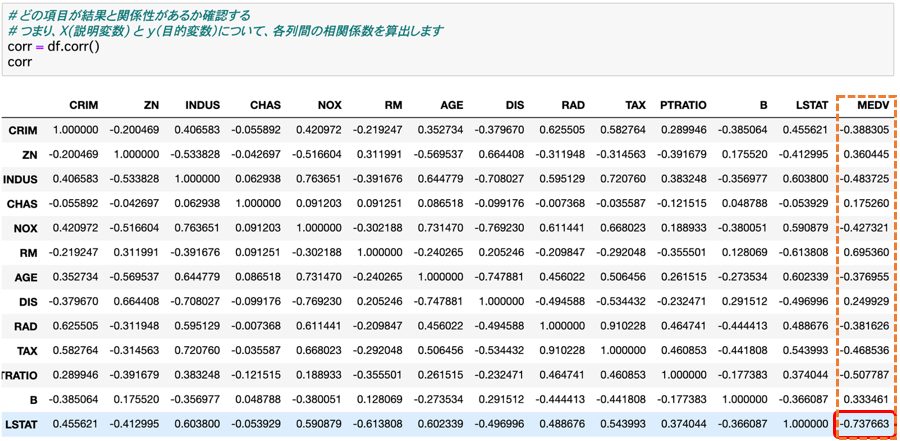
■相関係数のお話
相関係数は、2つの変数の間にある関係性の強弱を測る指標で、-1 ~ 1 の間の実数で表現されます。
つまり、相関係数が -1 に近いほど負の相関が強く、1 に近いほど正の相関が強いことを意味します。
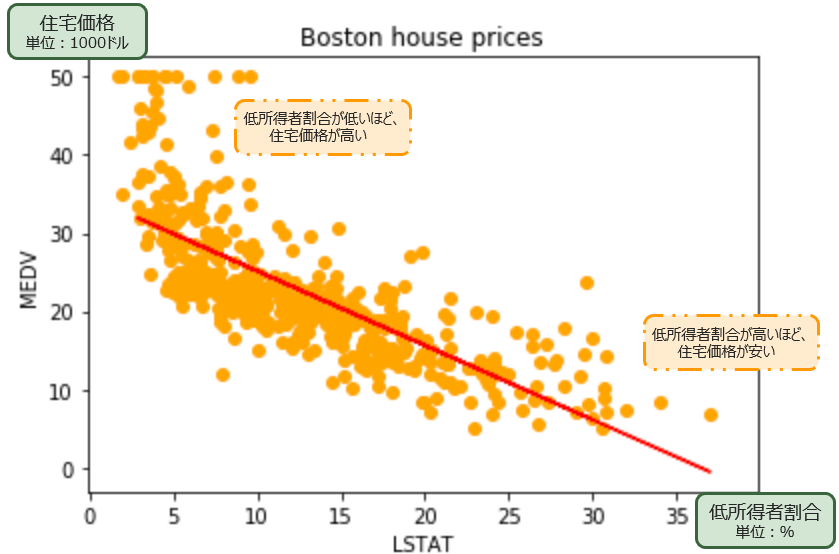
今回のデータセットでは、「LSTAT」(低所得者の割合)という説明変数が、目的変数である「MEDV」(住宅価格)と最も相関が大きいことがわかります。
今回は、α.目的変数「MEDV」(住宅価格)と相関が大きい β.説明変数「LSTAT」(低所得者の割合)を使って、予測を行うことにします。
低所得者の割合が大きいほど、住宅価格が低い(= 負の相関)想定ですが、具体的に低所得者がどのくらいの割合のときに、住宅価格がいくらになるのでしょうか?それを予測していきましょう。
②訓練用データと検証用データに分ける
機械学習では、低所得者の割合が10%のときの住宅価格は?というような未知のデータを予測するために、訓練用データと検証用データに分けます。
| 訓練用データ | 予測するための情報とその答えを学習するためのデータ | 教科書で学ぶイメージ |
| 検証用データ | 機械学習を行って予測した結果の答え合わせするためのデータ (=アルゴリズムの正確さが測れる) | 問題集を解くイメージ |
※なお、統計学用語でこれを「交差検証(クロスバリデーション)」といいます。

X(α.予測するためのデータ)を、訓練用データ(X_train)と検証用データ(X_test)に分ける。
y(β.予測したいデータ)を、訓練用データ(y_train)と検証用データ(y_test)に分ける。
ここでは、データの8割を訓練用データ、2割を検証用データに設定しています。(test_size=0.2)
■補足コメント
scikit-learnでの慣習で、Xは大文字、yは小文字を利用します。
③学習用アルゴリズムを呼び出す
既に用意されているモデル LinearRegression(線形回帰)のインスタンスを用意します。
④訓練用データを学習用アルゴリズムで機械学習
②で用意した訓練用データを、③のアルゴリズム(線形回帰)で学習させます。
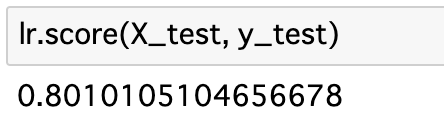
⑤正解スコアを検証する
②で用意した検証用データを使って、機械学習したアルゴリズムの正確性(%)を確認します。
※ここでは、約63%程度の正解率だと分かります。
⑥実際に予測する
今回機械学習させたアルゴリズムを利用して、実際のデータを予測してみます。
低所得者の割合が10%のときの住宅価格は、27,000ドル(約290万円)だと予測できます。
※ただ、この住宅価格というのが一戸を意味しているかは、サンプルデータセットから断定できないところです…(自社でデータを収集するときは明確にする必要がありますね。)
■おまけ
ちなみに、分かりやすくするために次元数を 1 (LSTAT:低所得者の割合)にしたのですが、元々のデータセットの次元数 13 (CRIM~LSTAT) で学習させるともう少し高いスコア(約80%)が出ました。
まとめ
今回は、機械学習に触れたことがない方向けに、機械学習の簡単な流れを理解するところにフォーカスして、6つのステップで解説しました。
実際のデータでは、漏れやミス(数値の項目に文字列など)が発生していることも多くあります。
機械学習では、データの品質がとても重要なため、あらかじめデータの削除や変換などの前処理を行うケースがほとんどです。
また、今回のように学習済のモデルを使う場面と、個別の企業様に応じて専用モデルを作る必要がある場面は、実現したい内容によって異なります。
それぞれのメリット&デメリットを踏まえ、解決したい課題に沿ったご提案のコンサルテーションから、実際の導入開発までサポートさせていただくことが可能ですので、まずはお気軽にご相談ください。
最後につぶやき
今回は、機械学習の簡単な流れを説明するために、あえて説明しなかった内容や、線形回帰以外のアルゴリズムには触れませんでした。
もし、この他にも知りたい・興味がある内容がありましたら、続編を検討したいと思いますので、お問合せ・ご要望いただけますと幸いです!