AI Builderによる画像認識モデルの構築
目次
米IBMが2022年7月に世界の企業を対象としたAI導入状況調査リポートGlobal AI Adoption Index 2022日本語版を発表しました。
このリポートによりますと、AIがより利用しやすいものになってきたとしている一方、「AIの専門知識が不足している」(34%)、「料金が高い」(29%)、「AIモデルを開発するツールやプラットフォームがない」(25%)といった障壁があることが挙げられています。
こうした背景もあり、今AIを手軽に利用できるAIノーコード/ローコードツールが注目されています。
本記事では、Microsoftの簡単にAIモデルの構築が可能な機能であるAI Builderについて紹介します。
AI Builderとは
まずはAI Builderの概要や特徴について見ていきます。
AI BuilderはPower Platformの機能の1つ
AI Builderとは、Microsoft Power Platformの機能の一部で、AIモデルを構築する機能です。
Power PlatformとはMicrosoftのクラウドサービスの総称で、以下の4つのサービスで構成されています。
いずれも直観的な操作でアプリ等の作成が可能な点が特徴です。
- Power Automate:自動ワークフロー作成
- Power Apps:ビジネスアプリの作成
- Power BI:データ解析、可視化
- Power Virtual Agents:チャットボットの構築
AI Builderでは、このうち作成したモデルをPower AppsのアプリやPower Automateのフローと連携することで業務効率化を実現することができます。
専門知識が不要
AI Builderでは、誰でも簡単に機械学習が利用できるようになることを目的としており、従来必要であったデータサイエンス等の専門知識がなくてもAIモデルの構築から利用まで可能です。
以下はAI Builderと組み合わせ可能なPower Automateのテンプレートを並べたイメージですが、ご覧の通りあらゆるビジネスニーズに応じAIモデルを用いたフローの作成をすることできます。
コスト削減が可能
また、一般にAIモデルを開発しようとすると、事前準備として大量の学習データの準備やタグ付け(アノテーション)が必要なケースも多く、開発に膨大なコストがかかりますが、事前構築済みモデルを使用することで、ユーザが用意する学習データが少なくて済むという点でAI導入におけるコスト削減が可能になります。
使用可能なAIモデル
AI Builderでは、AIモデルのビルドタイプとして「事前構築済みモデル」「カスタムモデル」の2種類があります。
ここでは、それぞれの特徴と対応するモデルについて紹介します。
事前構築済みモデル
事前構築済みモデルは、すでに用意された学習済みモデルのことで、ユーザはゼロからモデルを構築することなく業務を効率化することができます。
以下のモデルを利用することができます。
- 請求書/領収書処理:請求書や領収書から情報を抽出する
- テキスト認識:写真や PDF ドキュメントからすべてのテキストを抽出する
- IDドキュメントリーダー:パスポートや免許証から情報を抽出する
- 名刺リーダー:名刺から情報を抽出する
- 感情分析:テキスト データ内の肯定的、否定的、または中立的な感情を検出する
- カテゴリ分類:顧客からのフィードバックを定義済みのカテゴリに分類する
- エンティティの抽出:テキストから重要な要素を抽出し、定義済みのカテゴリに分類する
- キーフレーズの抽出:テキストから関連性が高い語句を抽出する
- 言語検出:ドキュメント内の主要な言語を検出する
カスタムモデル
カスタムモデルでは、目的に合わせてモデルのカスタマイズができます。
カスタムモデルでは、事前構築済みモデルのカスタマイズの他、履歴データから将来の結果を予測する予測モデルや、画像内のオブジェクトを検出する物体検出モデルの利用も可能です。
カスタムモデルを使用した画像認識アプリを作成してみる
ここからは、実際にAI Builderのカスタムモデルを構築し、そのモデルを使用したアプリの作成手順について見ていきます。
アプリでスキャンした電気/ガスの検針票のデータをテキストで出力します。
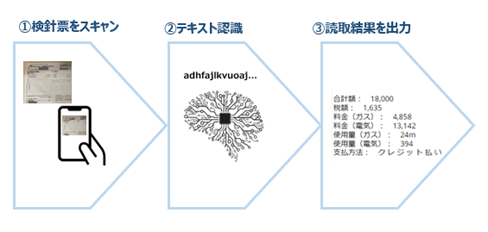
作成の流れですが、まずはテキスト認識のカスタムモデルを作成し、その後Power Appsでスマホ用のキャンバスアプリを作成していきます。
カスタムモデルの構築
まずテキスト認識のカスタムモデルを作成していきます。
Power Automateを開きます。
画面左にあるメニューから「モデル」をクリックします。
「モデルの作成」をクリックします。
モデルの一覧画面に遷移します。
「ドキュメントからカスタム情報を検出する」をクリックします。
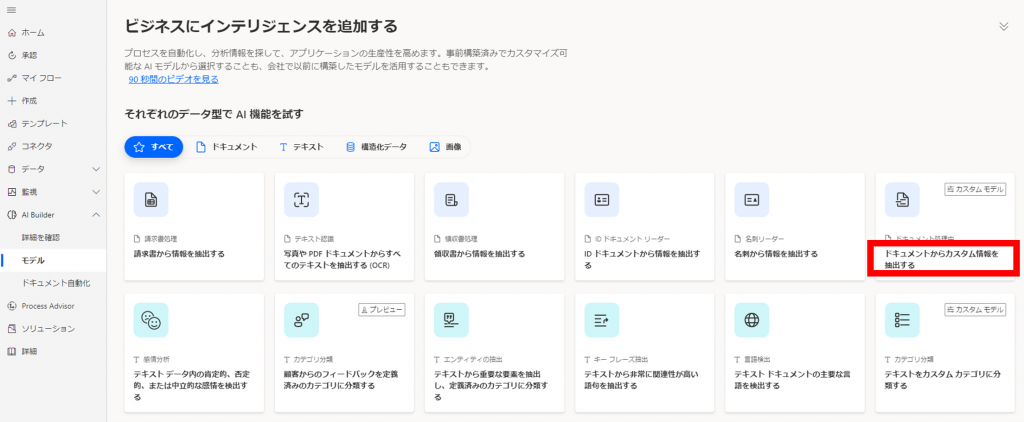
モデルのプレビュー画面が表示されます。「作業の開始」をクリックします。
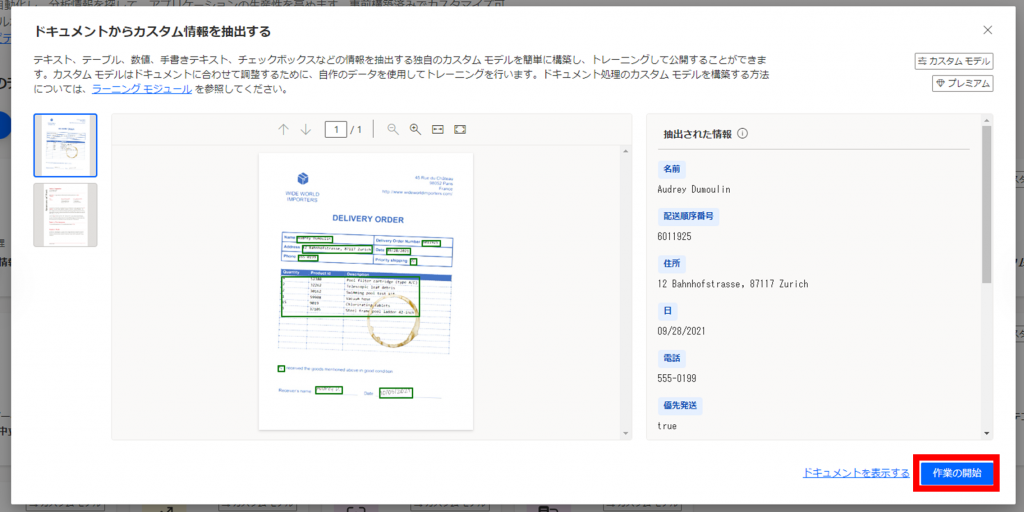
ドキュメントの種類を選択します。
ドキュメントの種類は「構造化および半構造化ドキュメント」と「構造化されていない自由形式ドキュメント」の2種類がありますが、ここでは「構造化および半構造化ドキュメント」をクリックします。
抽出する情報を選択していきます。
以下の情報を設定していきます。
- Total:合計請求金額
- Tax:消費税額
- Amount_Gas:ガスの請求内訳金額
- Amount_Electricity:電気の請求内訳金額
- Usage_Gas:ガスの使用量
- Usage_Electricity:電気の使用量
- Payment Method:支払方法
「+追加」をクリックします。
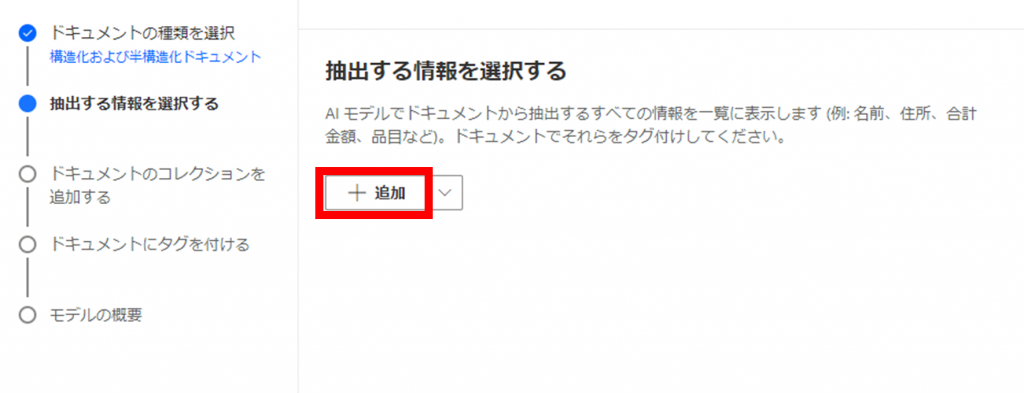 次に、「フィールド」をクリックします。
次に、「フィールド」をクリックします。
「次へ」をクリックします。
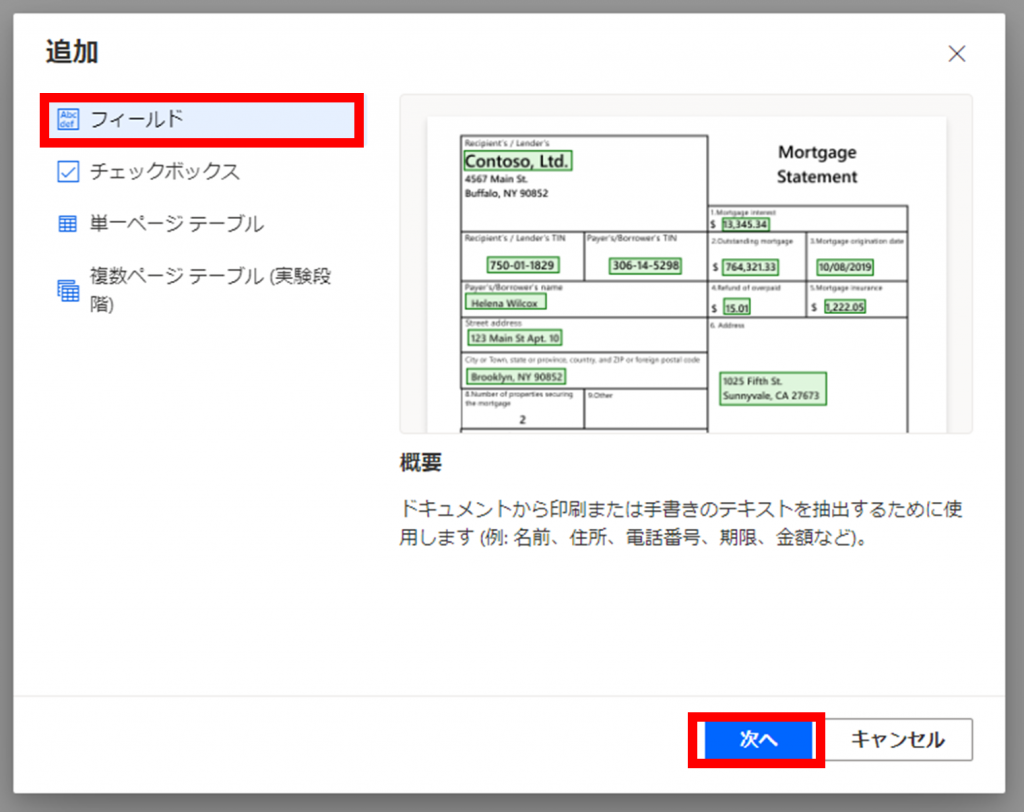
「名前」に抽出対象の名前を入力します。
「完了」をクリックします。
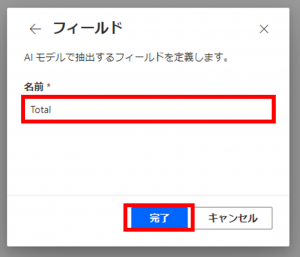
この手順を抽出対象の情報単位で行います。
(ここでは、上記Total~Payment Methodの7フィールドについて設定します)
以下のイメージのように、すべてのフィールド設定が完了後、「次へ」をクリックします。
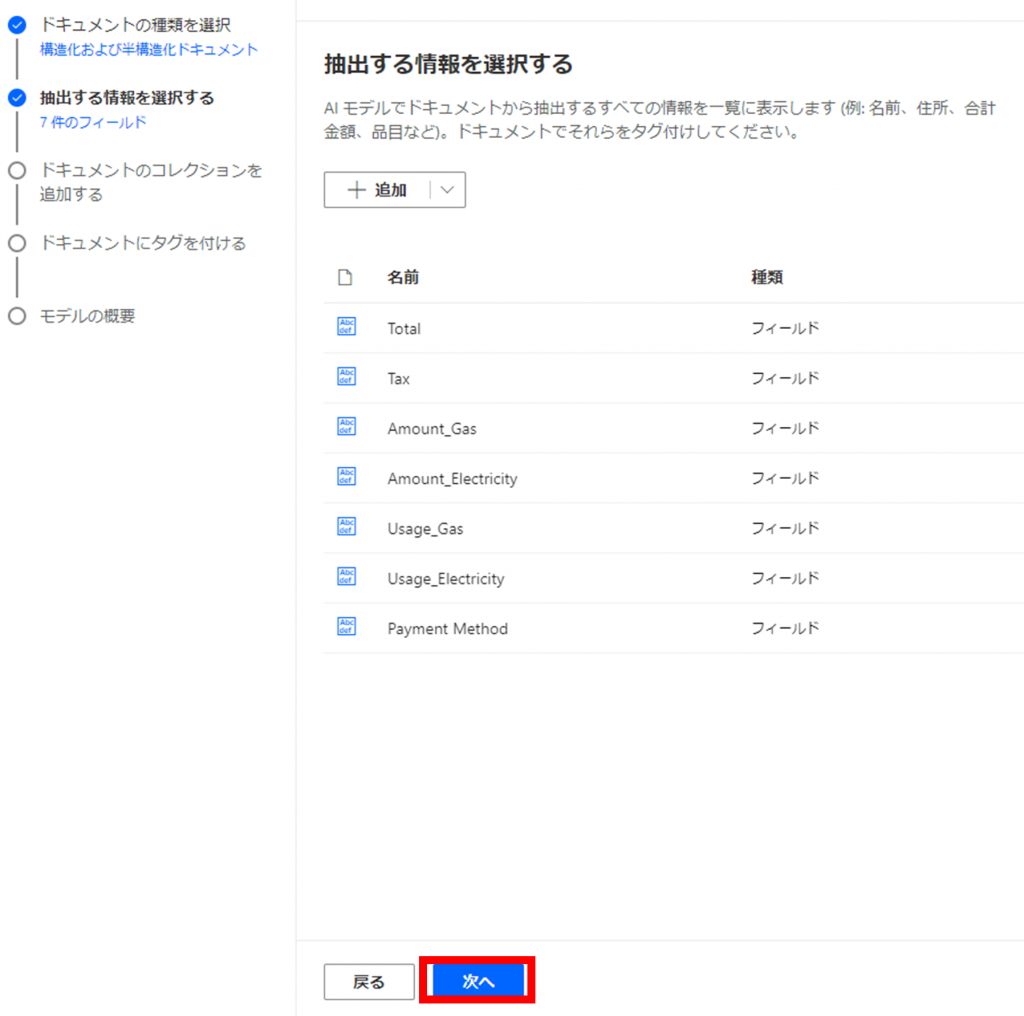
モデルが学習するサンプルドキュメントを追加していきます。
「新しいコレクション」をクリックします。
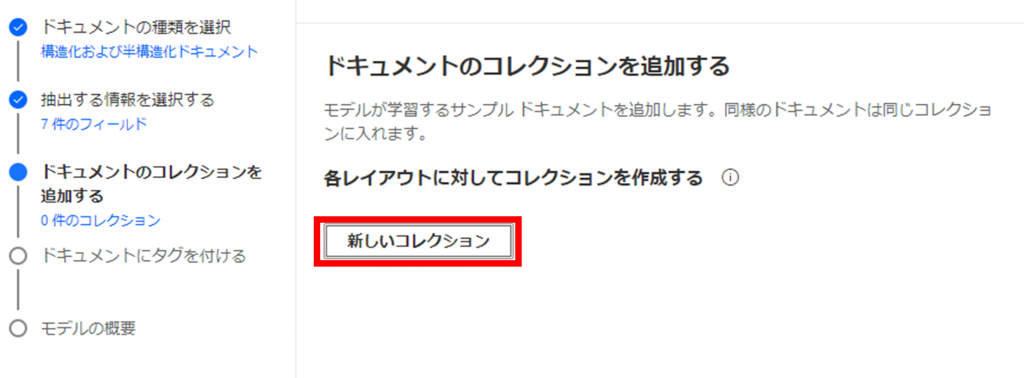
新たに表示されるコレクション名に値「Invoice」を入力し、「+」をクリックします。
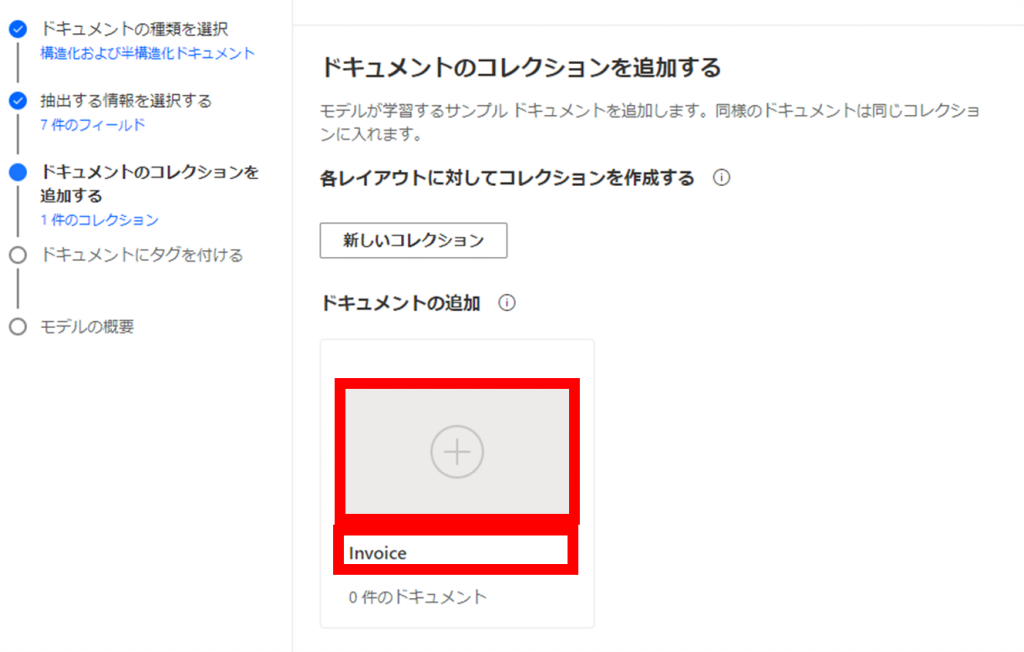
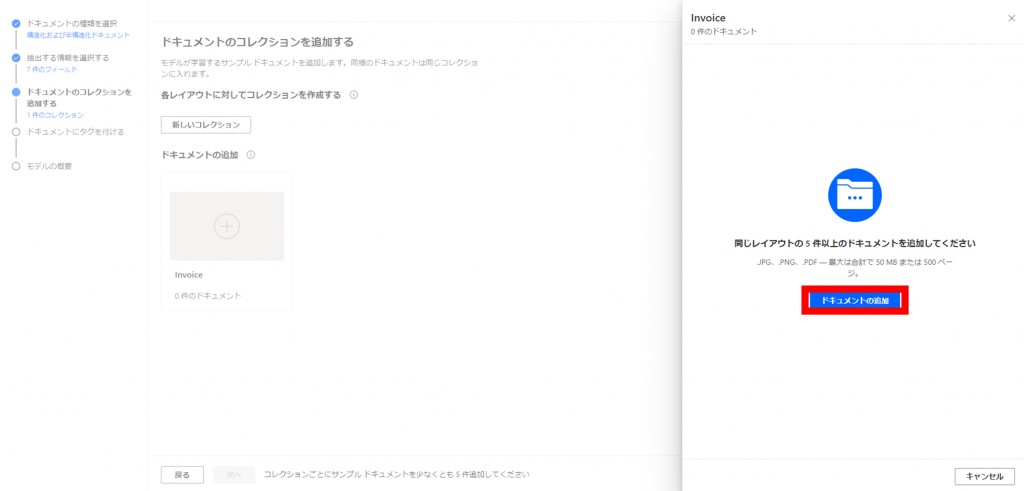
「ドキュメントの追加」をクリックします。
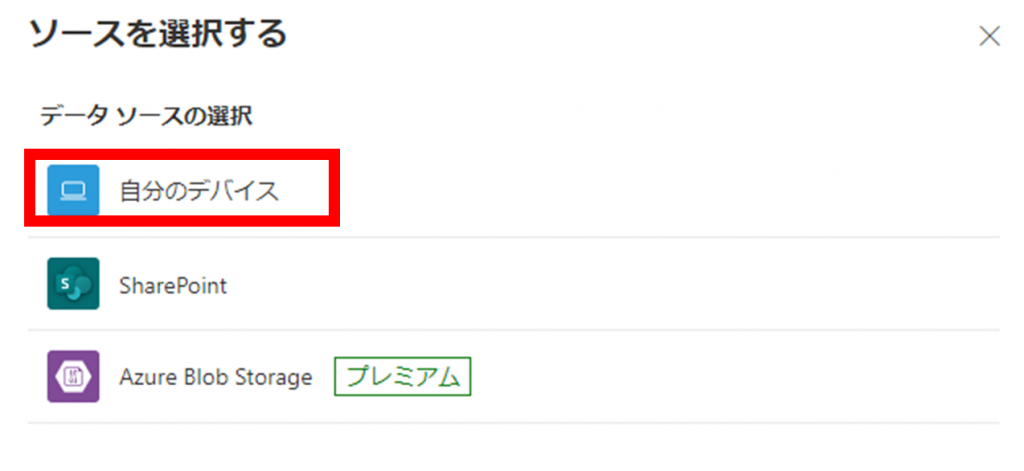
サンプルドキュメントの格納先を選択します。
今回は「自分のデバイス」を選択します。
サンプルファイルを選択し、「開く(O)」をクリックします。
サンプルファイルは同じレイアウトのものを最低5枚用意する必要があります。
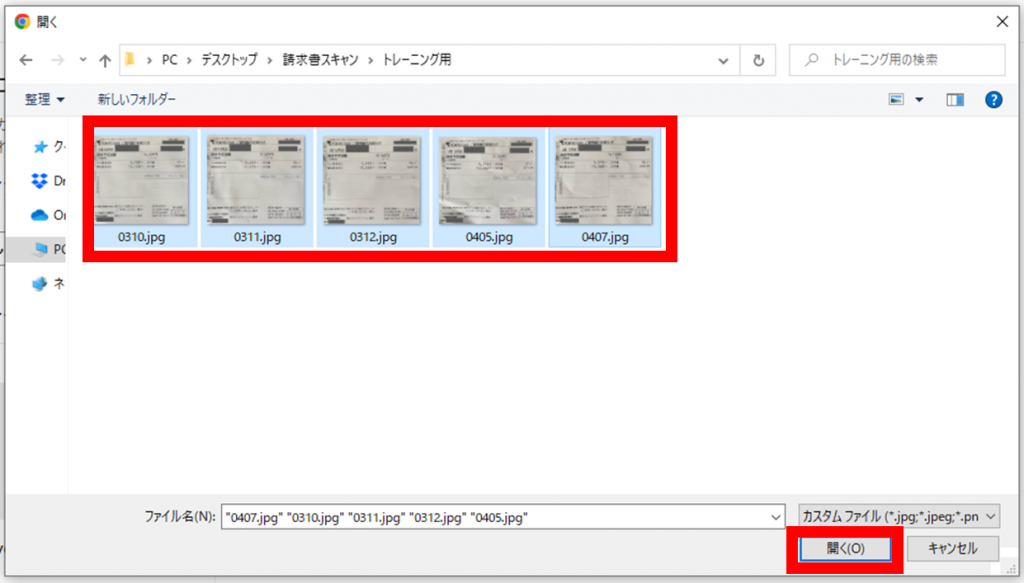
「5件のドキュメントのアップロード」をクリックし、サンプルファイルをアップロードします。
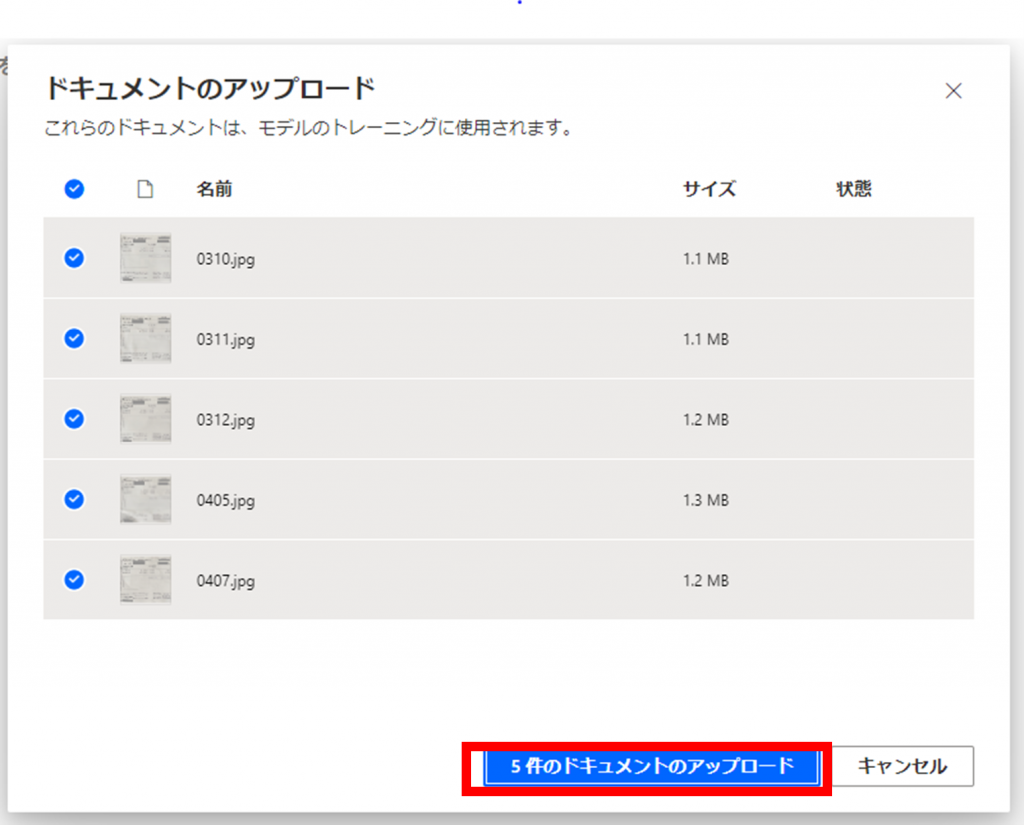
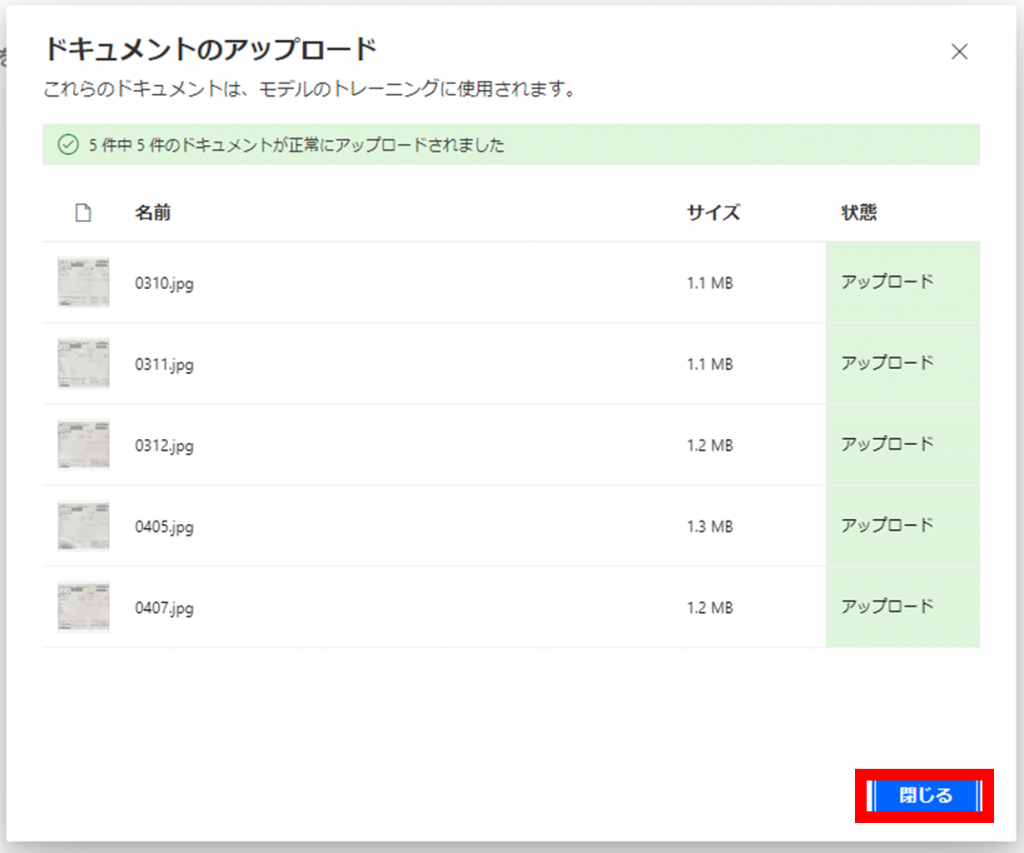
アップロード完了後以下の画面が表示されます。
「閉じる」をクリックします。
「次へ」をクリックします。
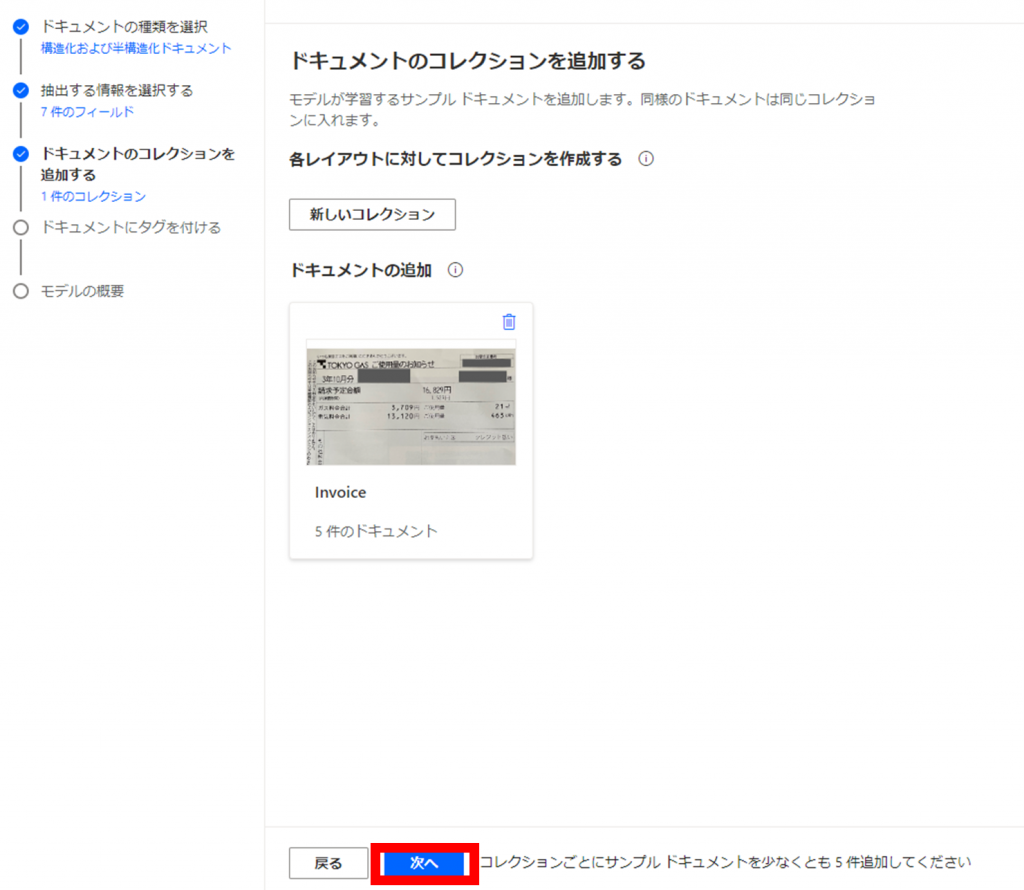
続いて、アップロードしたサンプルドキュメントにタグをつけていきます。
(サンプルドキュメント上の値の位置とフィールドの対応付けを行うイメージになります)
以下の画像のように、表示されるサンプルドキュメント上でクリックまたはドラッグ&ドロップで認識範囲を指定します。
認識範囲の指定を行うと、吹き出しで対応のフィールドが一覧で出てきますので、該当のフィールドを選択します。
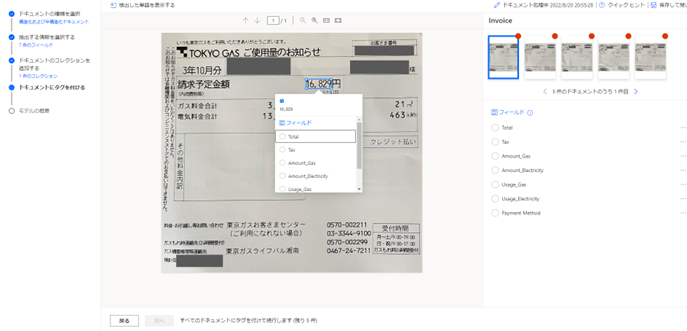
これをすべてのサンプルドキュメントに対して設定します。
すべて設定が完了したらこのような画面になります。
「次へ」をクリックします。
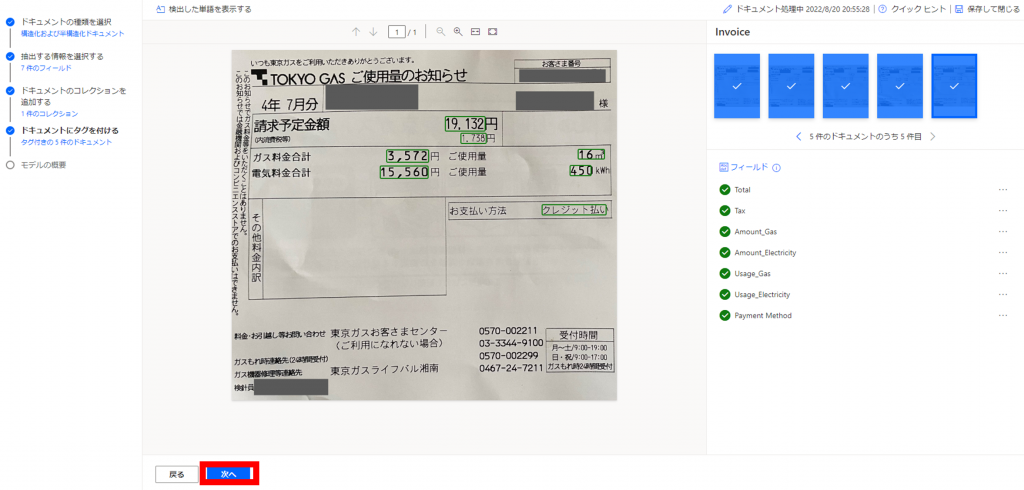
続いて、作成したモデルのトレーニングを行います。
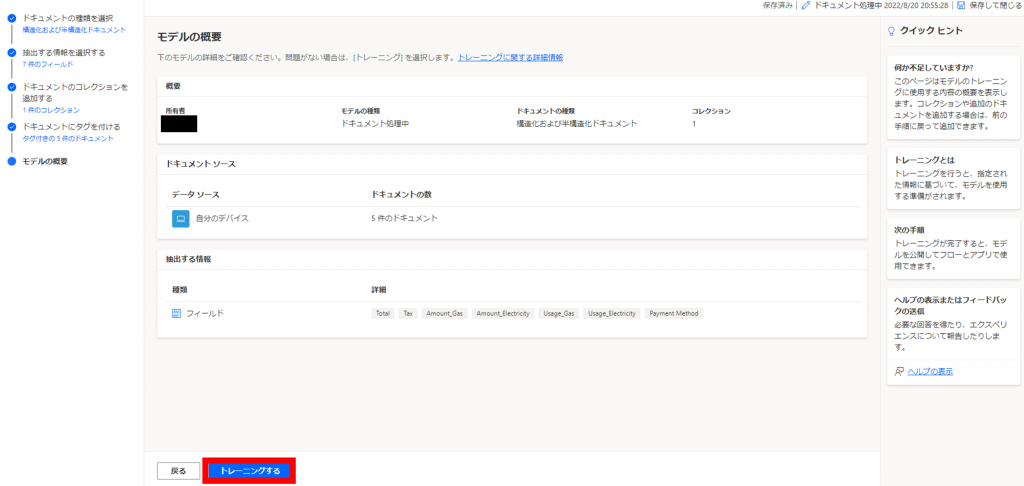
「トレーニングする」をクリックします。
(トレーニングにはサンプルデータサイズに応じ時間がかかる場合があります)。
以下の画面が表示されたら「モデルに移動」をクリックします。
次の画面に遷移します。
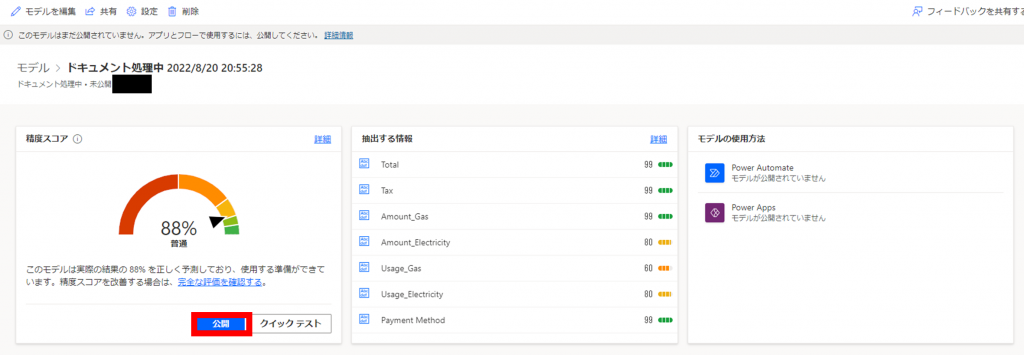
「モデル」には作成済みのモデルが一覧で表示されますが、今回作成されたモデルが表示されています。
なお、モデル名は「ドキュメント処理中 2022/8/20 20:55:28」となっています。
また、「状態」はトレーニング中のため「トレーニング」と表示されています。トレーニングが完了するまでしばらく待ちます。
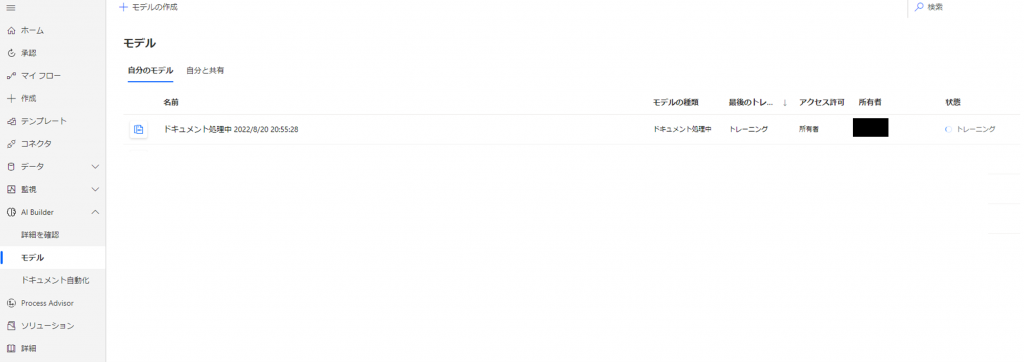
トレーニング完了後、「状態」が「トレーニング済み」になります。
3点リーダーから「詳細」をクリックします。

モデルの公開を行う前に、ここでモデルのクイックテストを行います。
「クイックテスト」をクリックします。
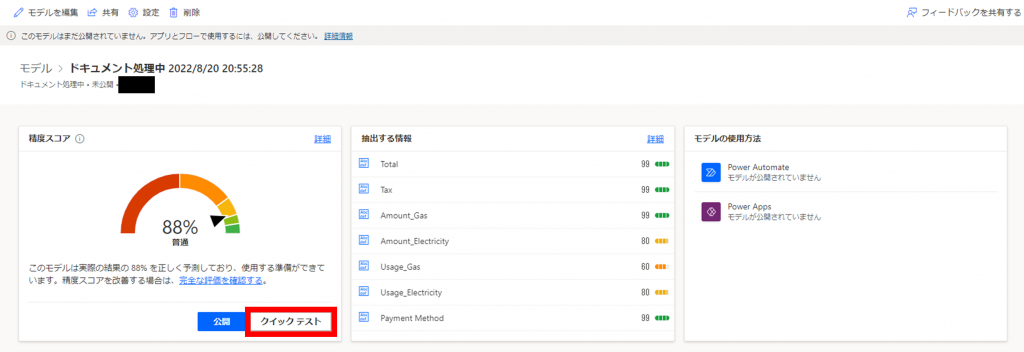
「自分のデバイスからアップロード」をクリックします。
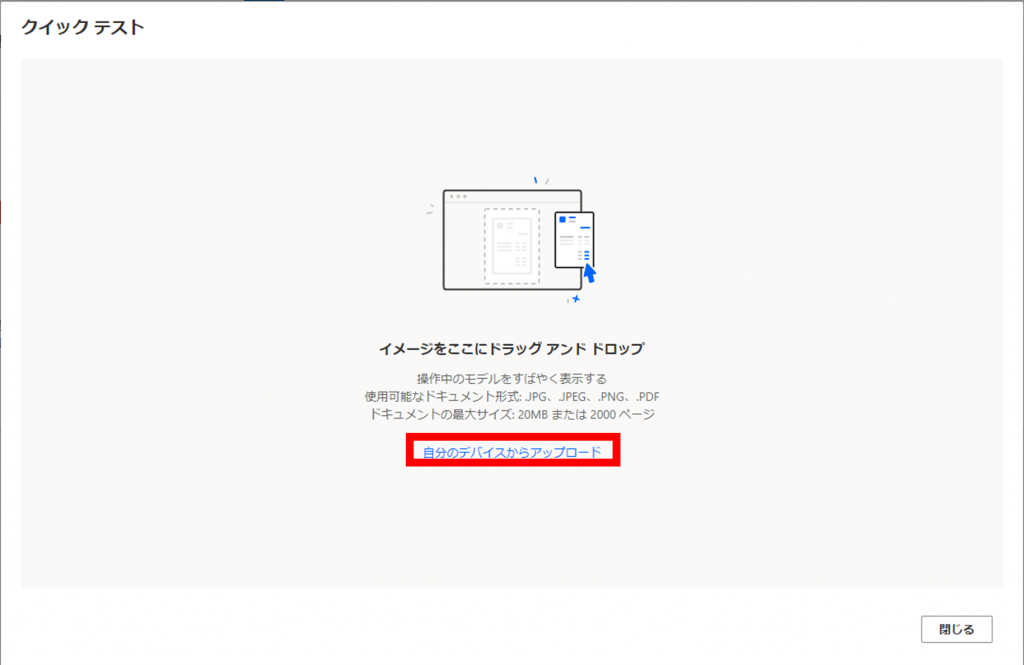
テスト対象のデータを選択し、「開く(O)」をクリックします。
この時、選択するファイルはモデル作成時に使用したサンプルファイルとは別のファイルを選択します。
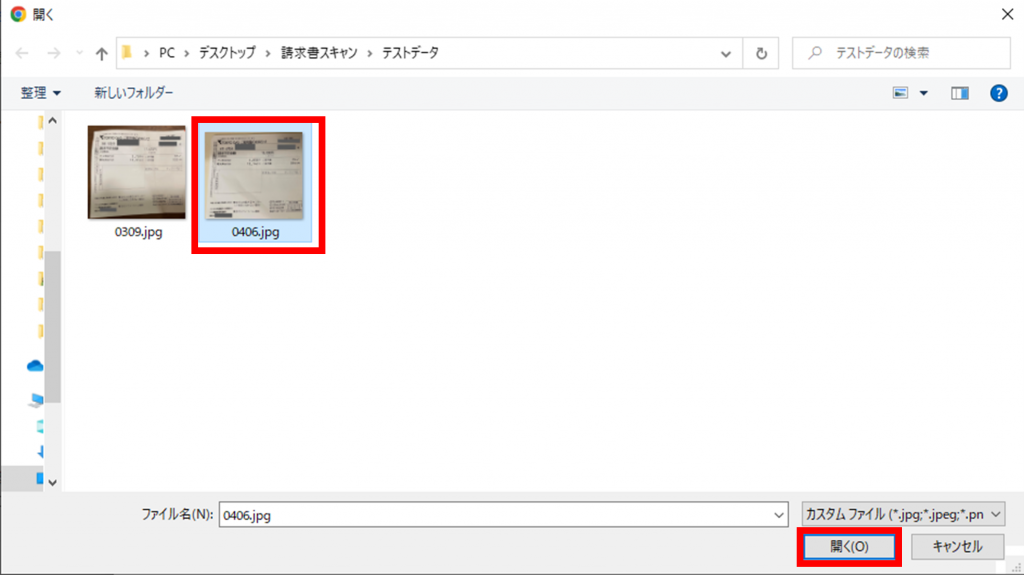
テスト結果が表示されました。
右側のイメージのように認識範囲にマウスのフォーカスを当てると、認識した値と信頼度スコア(%)を確認することができます。
ここで意図した結果にならなかったり、信頼度が著しく低い項目がある場合はテストのやり直しやサンプルデータの追加等の対応を行う必要があります。
今回はこのまま「閉じる」をクリックし次に進みます。
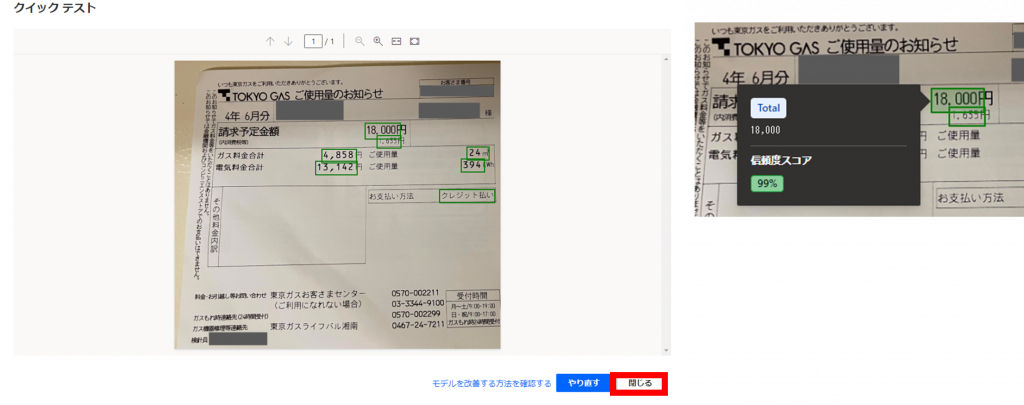
クイックテストが問題ないことを確認後、モデルを公開します。
モデルを公開することで、Power AutomateやPower Appsでモデルを使用したフローやアプリを作成することが可能になります。「公開」をクリックします。
「モデルが公開されました」とメッセージが表示されることを確認します。
アプリの作成
ここからは、作成したモデルを用いてPowerAppsアプリを作成していきます。
PowerAppsを開き、「作成」をクリックします。
「空のアプリ」をクリックします。
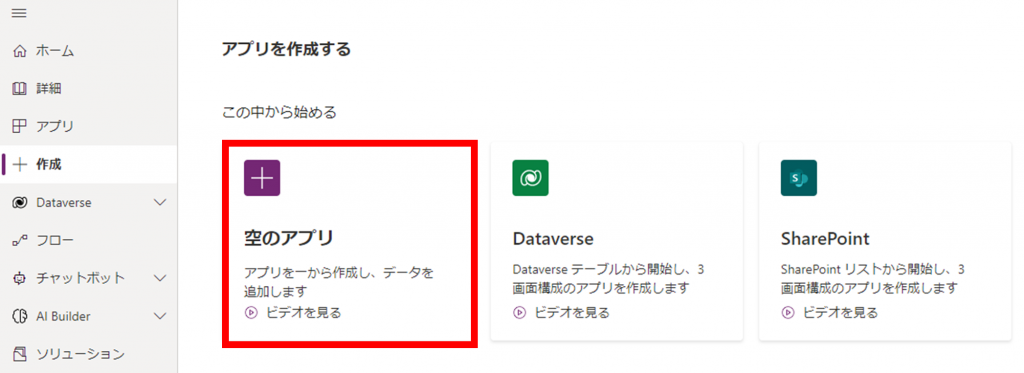
「空のキャンバスアプリ」の「作成」をクリックします。
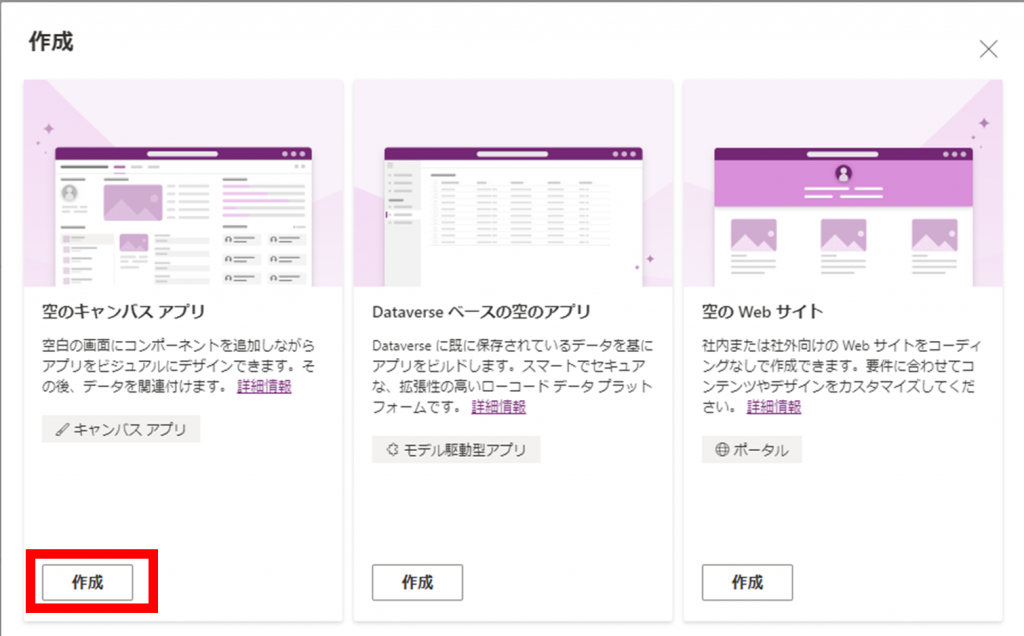
アプリ名を入力します。ここでは「Extracting invoice data」と入力します。
「形式」ですが、今回はモバイルアプリとしての使用を想定しているため「電話」にチェックします。
「作成」をクリックします。
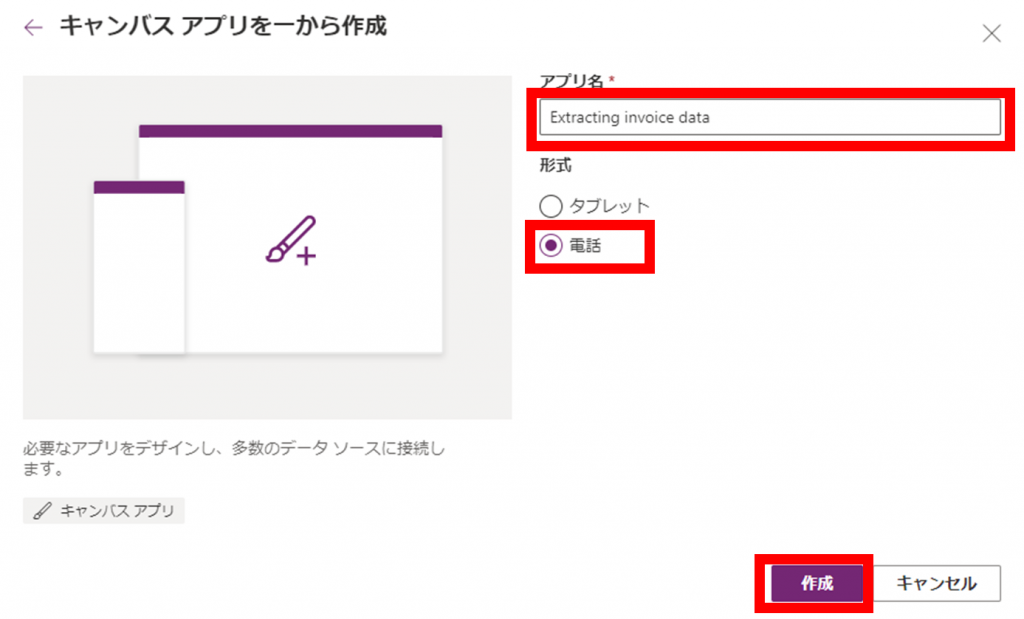
「挿入」-「AI Builder」から「フォームプロセッサ」をクリックします。
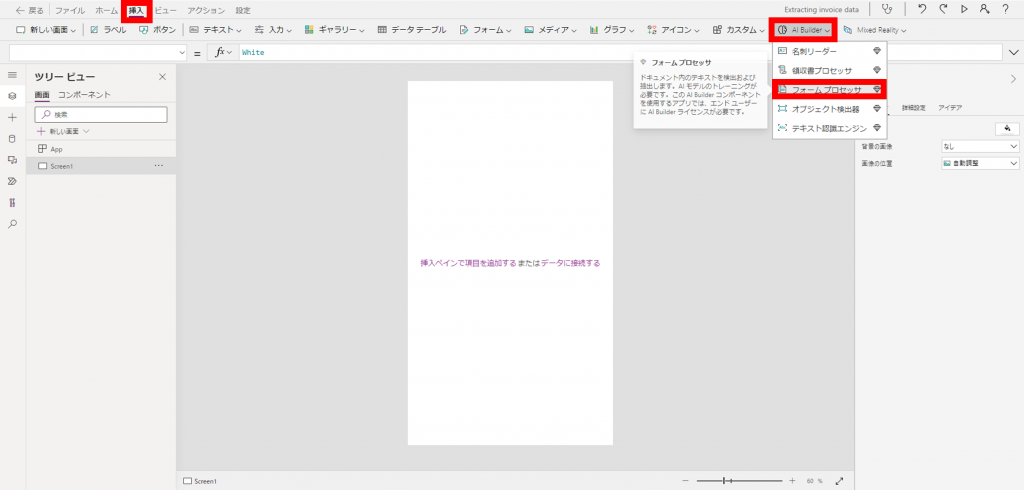
「AIモデル」に作成したモデル名が表示されるのでクリックします。
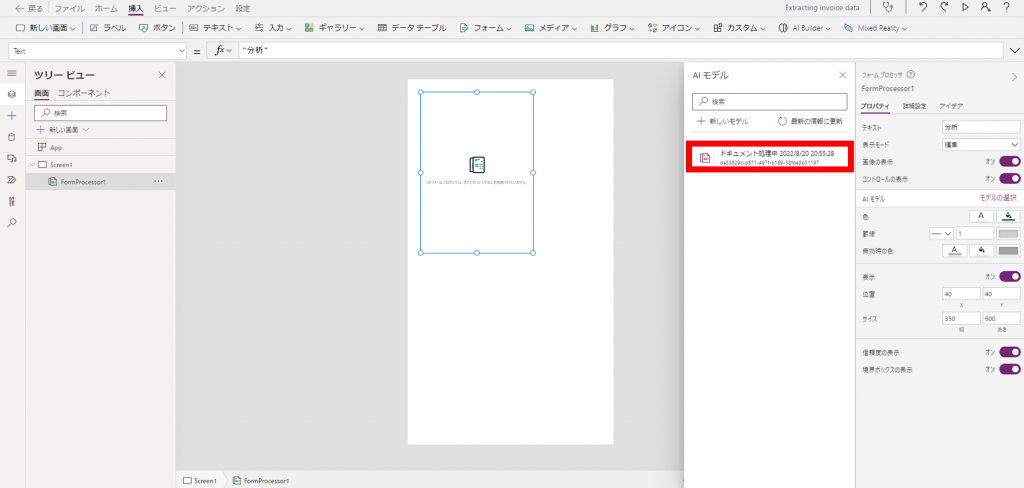
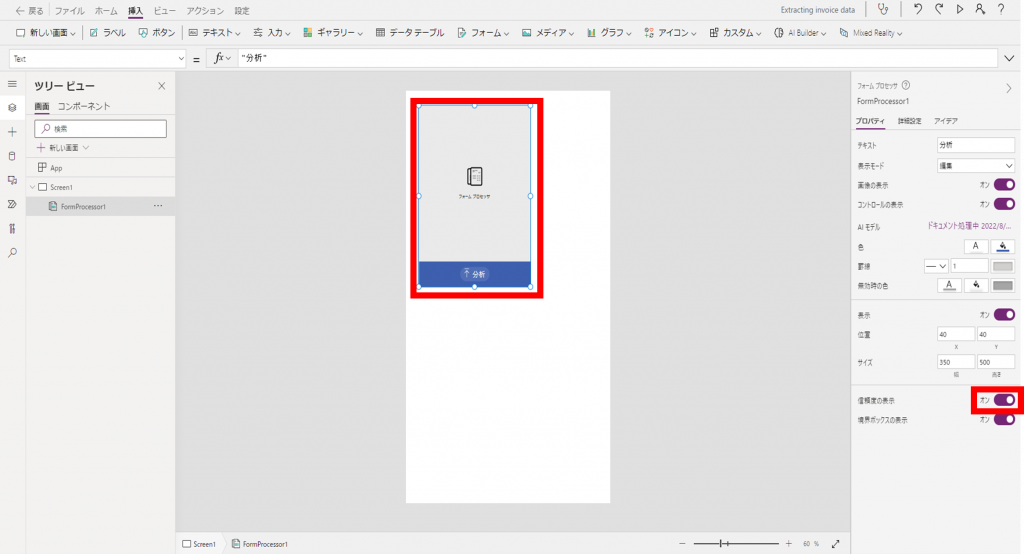
画面中央に表示されているフォームをドラッグ&ドロップで適切な範囲に広げます。
次に、「信頼度の表示」のチェックをオフにします。
「挿入」-「ラベル」をクリックしテキストラベルを挿入します。
このテキストラベルには、スキャンした結果を出力させます。
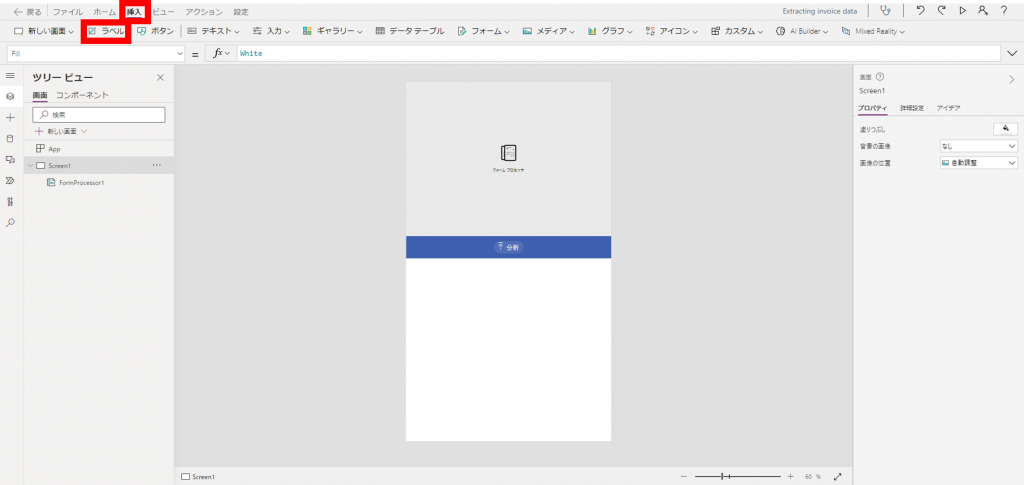
追加したテキストラベルをドラッグ&ドロップでスクリーン下部に移動し適切な範囲に広げます。
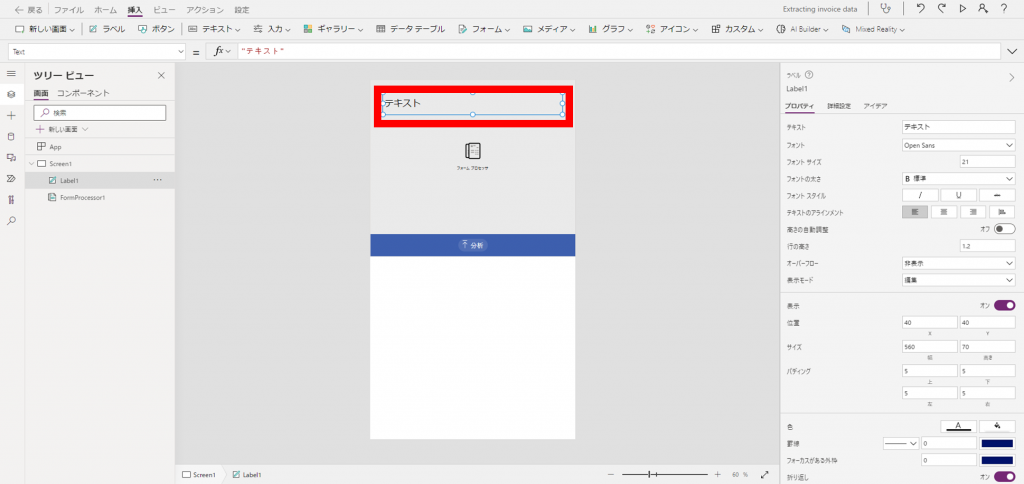
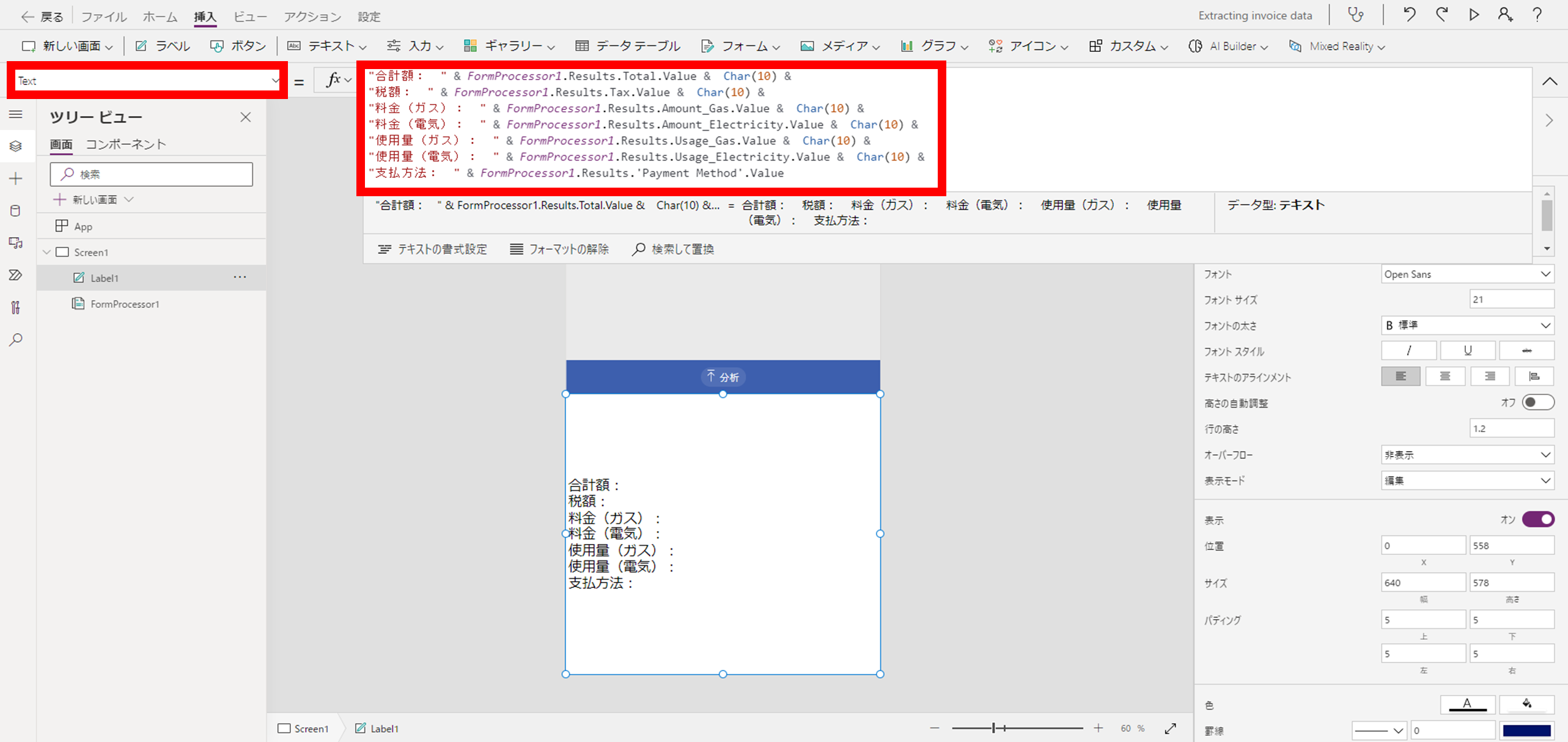
テキストラベルの「Text」プロパティに出力内容を設定します。
下記のイメージでは、スキャンされた結果各フィールドの値を行単位で出力させるように値を設定しています。
アプリを保存します。
「ファイル」をクリックします。
「保存」をクリックします。

「公開」をクリックしアプリを公開します。
「このバージョンの公開」をクリックします。
アプリ起動
それでは、アプリを起動しテストデータをスキャンしてみます。
こちらが結果です。

画面上部にはスキャンした画像が表示されますが、認識箇所が信頼度に応じて次の3種類の色の枠線で囲まれます。
・青:60~100%
・オレンジ:40~59%
・赤:0%~39%
画面下部には認識結果がテキスト形式で出力されていますが、大体意図した通りに読み取れているかと思います(信頼度が低い赤枠の箇所も正しく読み取れています)。
今回は5枚のサンプルデータで実施しましたが、より多くのデータでトレーニングを行うことで認識率を向上させることが可能です。
AI Builderで業務効率化を実現
いかがでしたでしょうか?
今回はAI Builderの概要及び使い方について紹介しましたが、専門的な知識がなくてもAIモデルの構築から使用まで手軽に実施できます。
構築済みモデルを利用する場合は、コストをかけずにモデルを利用することができます。
カスタムモデルでは、サンプルデータの準備やモデルのチューニング等メンテナンスが必要ですが、ほとんどが直感的な操作でモデルの作成が可能なことをご理解いただけたのではないかと思います。
本記事を参考にAI Builderの知見を深め、業務効率化にお役立ていただければ幸いです。
弊社ではローコードやRPAをはじめとする各種ソリューションを活用した業務効率化の実績が多数ございます。
今回紹介したAI Builderの他、業務効率化のためのソリューション選定や推進体制の構築、ルール作り等、お困りのことがありましたらお気軽にお問合せください。
最新情報をお届けします!
RPAに関する最新コラムやイベント情報をメールで配信中です。
RPA領域でお仕事されている方に役立つナレッジになりますので、ぜび登録してください!









- November 2024 (2)
- October 2024 (3)
- September 2024 (2)
- August 2024 (4)
- July 2024 (1)
- June 2024 (2)
- May 2024 (3)
- April 2024 (1)
- March 2024 (1)
- February 2024 (1)
- January 2024 (1)
- December 2023 (1)